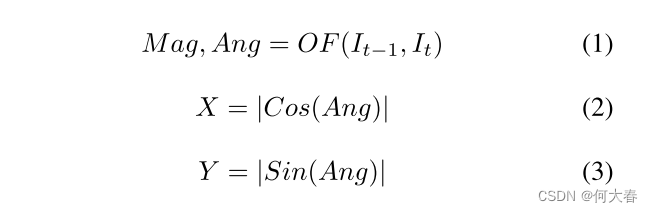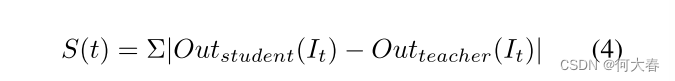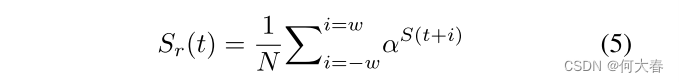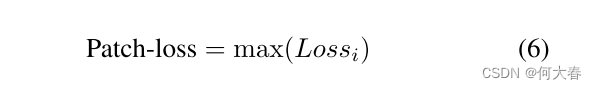文章信息:

原文链接:https://ieeexplore.ieee.org/document/10208994/
源代码:无
发表于:CVPR 2023
Abstract
基于多任务学习的视频异常检测方法将多个代理任务结合在不同的分支中,以便在不同情境中检测视频异常。然而,大多数现有方法存在以下一些缺点:
I) 它们的代理任务组合方式不是以互补且可解释的方式进行的。
II) 对象的类别没有得到有效考虑。
III) 并未覆盖所有运动异常情况。
IV) 上下文信息未参与异常检测。
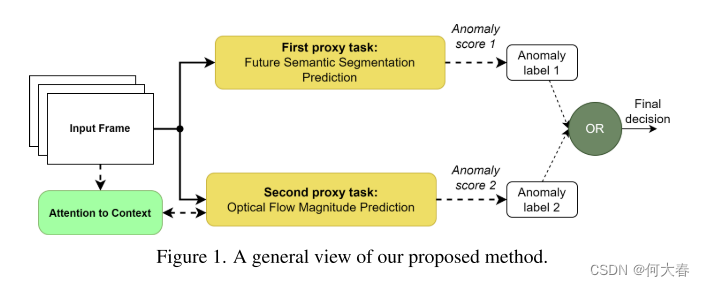
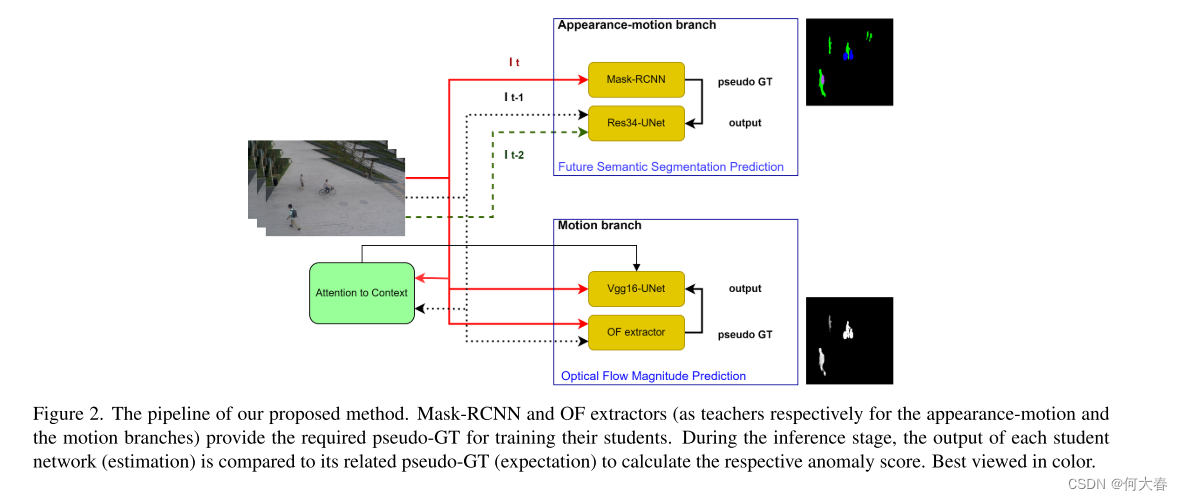
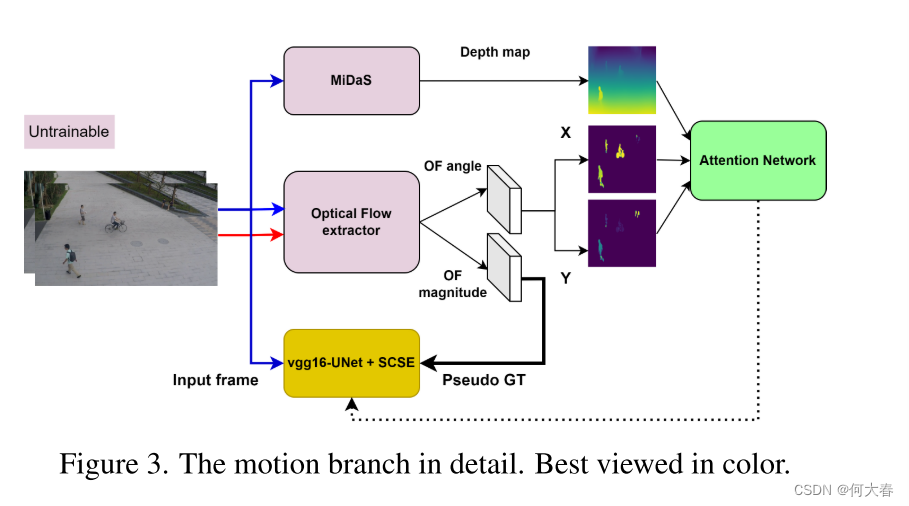
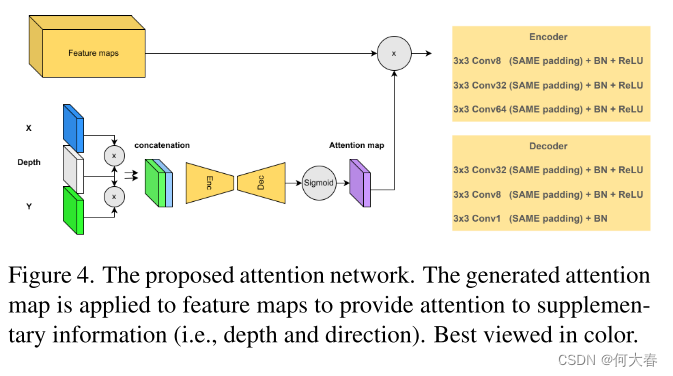
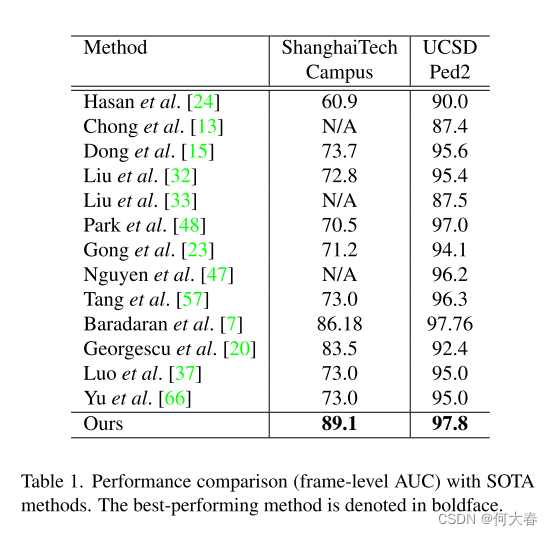
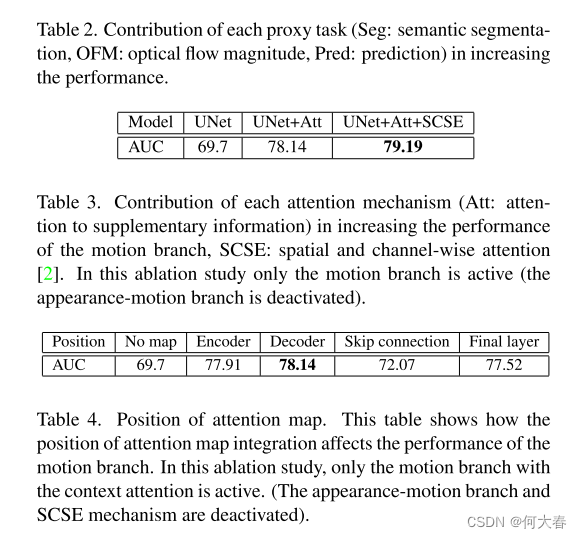
为了解决这些问题,我们提出了一种新颖的基于多任务学习的方法,它结合了互补的代理任务以更好地考虑运动和外观特征。在一个分支中,受语义分割和未来帧预测任务的能力启发,我们将它们合并成一个新任务,即未来语义分割预测,以学习正常对象类别和一致的运动模式,并同时检测相应的异常。在第二分支中,我们利用光流幅度估计进行运动异常检测,并提出了一种注意机制,以在正常运动建模中引入上下文信息,并关注对象部分、运动方向和对象与摄像机之间的距离,以检测运动异常。我们的定性结果表明,所提出的方法有效地考虑了对象类别,并注意了上述决定性因素,从而实现了精确的运动建模和更好的运动异常检测。此外,定量结果显示我们的方法相对于最先进的方法具有优越性。
1. Introduction
随着监控摄像头的增多,对视频内容的自动分析需求不断增加。通常,该分析的目的是检测视频中的异常事件(即在给定背景下不熟悉或意外的事件[10, 20]),这可能需要立即采取行动。由于异常事件的罕见性和多样性,通常很难获得足够的训练异常样本用于监督训练。因此,该领域的研究人员更加关注半监督方法,其中通过代理任务(即间接帮助实现目标目标的任务)学习正常情况,通过找到与正常情况的偏差来检测异常。例如,在视频异常检测(VAD)中,当前帧的重建或遮罩帧的预测是常见的代理任务,训练模型对于正常情况显示出对异常的较差的重建或预测结果,而估计的错误决定了异常分数。研究人员在他们的方法中的多个分支中采用不同的代理任务,以考虑不同的模态性(主要是外观和运动)。不同的代理任务旨在相互补充,因此被组合以实现更高的性能。例如,Nguyen和Meunier [47] 提出了一个两流网络,其中一个流模拟外观特征并检测基于外观的异常,而另一个流模拟运动模式并寻找运动异常。已经提出了多种类似的策略,每个工作都提出了不同的代理任务组合和不同的异常分数融合策略[7, 16, 20, 26, 47, 57]。最近,研究人员(例如 [11, 20, 29])提议添加更多的代理任务(即基于多任务学习的方法)以涵盖更多的时空模式。多任务学习方法中的关键问题是选择多少/哪些代理任务才能达到互补并提高性能。通常,添加更多的代理任务可能会导致更好的性能;但是,这会增加计算负担和运行时间。因此,设计目标是提出最少量的互补任务,考虑它们在检测多种异常类型中的能力和不足,以覆盖所有必要的属性。值得注意的是,可解释的异常检测要求在选择每个代理任务背后有一个强有力的解释。
尽管最近的方法取得了更好的结果,它们仍然要么没有充分考虑运动模式,要么没有明确分析对象类别进行异常检测。为了解决这些缺点,受到[20]的启发,我们提出了一种改进的基于多任务学习的视频异常检测(VAD)方法。与[20]不同,并借鉴语义分割任务在VAD中考虑对象类别的成功[7],我们在外观分支中以一种改进的方式利用语义分割代理任务的能力。此外,与[20]相反,后者在对象级别执行异常检测,我们提出了一种全面的VAD方法,避免了失去位置信息的缺点。
Nguyen等人[47]提出从单帧估计光流(OF)以建模运动模式并检测相关的异常。然而,从单帧估计光流可能对运动网络造成困扰。为了克服这个问题,Baradaran和Bergevin [7]提出使用每个对象的光流幅度(OFM)估计来检测运动异常。尽管他们的方法解决了上述问题,但他们的方法在运动估计中忽略了运动方向信息。因此,他们的方法不能有效检测由于突然的方向变化引起的异常(例如打斗、跳跃等)。此外,为了使每个对象与其运动幅度(即基于像素的对象在帧间位移)相对应,一些重要因素,如运动方向、对象部分和对象与摄像机的距离,未被考虑在内。