1.1 什么是MongoDB?
MongoDB是一个可扩展、开源、表结构自由、用C++语言编写且面向文档的数据库,旨在为Web应用程序提供高性能、高可用性且易扩展的数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中 功能最丰富、最像关系数据库的NoSQL数据库;它支持的查询语言非常强大,其语法有 点类似于面向对象的查询语言,可以实现类似关系数据里单表查询的绝大部分功能,而且还支持对数据建立索引。
1.2 MongoDB特点
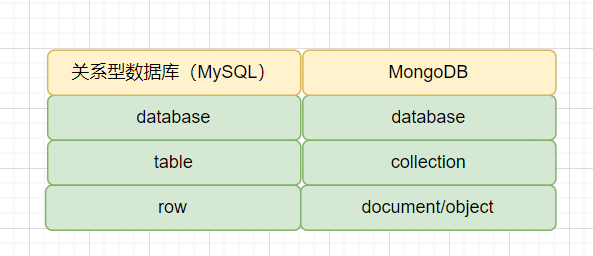
它用与JSON格式类似的键值对来存储(在MongoDB中叫BSON对象),其中值的数据类型有常见的字符串、数字、日期,还可以是BSON对象、数组以及数组的元素,也可以是BSON对象,通过这种嵌套的方式,使MongoDB的数据类型变得相当丰富。 MongoDB与传统关系数据库还有一个重大区别就是:可扩展的表结构。也就是说collection (表)中的document (—行记录)所拥有的字段(列)是可以变化的,下面文档对象document ( —行记录)比上面列出的文档对象document (—行记录)多一个time字段,但它们可以共存在同一个collection (表)中。
MongoDB查询语句不是按照SQL的标准来开发的,它围绕JSON这种特殊格式的文 档型存储模型开发了一套自己的查询体系,这就是现在非常流行的NoSQL体系。关系数据库中常用的SQL语句在MongoDB中都有对应的解决方案。当然也有例外,MongoDB不支持Join语句。我们知道传统关系数据库中Join操作可能会产生笛卡尔积的虚拟表,消耗较多系统资源,而MongoDB的文档对象集合collection可以是任何结构,我们可以通过设计较好的数据模型尽量避开这样的操作需求。如果真的需要从多个collection (表)中检索数据,那我们可以通过多次查询得到。
在关系数据库中经常用到的group by等分组聚集函数,在MongoDB中也有,而且MongoDB提供了更加强大的MapReduce方案(GOOGLE提出的并行编程),为海量数据的统计、分析提供了便利。
MongoDB支持日志功能Journaling,对数据库的增、删、改操作会记录在日志文件中。MongoDB每100ms将内存中的数据刷到磁盘上,如果意外停机,在数据库重新启动时,MongoDB能通过Journaling日志功能恢复。
MongoDB支持复制集(Replset), —个复制集在生产环境中最少需要3台独立的机器 (测试的时候为了方便可能都部署在一台机器上),一台作主节点(primary), —台作次节点(secondary), —台作仲裁节点(只负责选出主节点),备份、自动故障转移,这些特性都是复制集支持的。
MongoDB支持自动分片Sharding,分片的功能实现海量数据的分布式存储,分片通常与复制集配合起来使用,实现读写分离、负载均衡,当然如何选择片键是实现分片功能的关键。如何实现读写分离我们后面会详细分析。
1.3. 适合哪些业务
1.4 总结
MongoDB是一个面向文档的数据库,不支持关系数据库中的join操作和事务。它用集合的概念代替了关系数据库中的表,用最小逻辑单元文档代替关系数据库中的行。它的集合结构是动态的,没有必要像关系数据库一样插入数据前先定义表结构,而且可以随时増加、修改、删除组成文档的字段。
MongoDB支持当前所有主流编程语言的客户端驱动,使用方便,应用广泛,非常适合文档管理系统的应用、移动APP应用、游戏开发、电子商务应用、分析决策系统、归档和曰志系统等应用。