本文介绍: 首先回顾一下之前的RNN的一个端到端的模型,以下是一个典型的两层的LSTM模型,我们可以发现,这样一个RNN模型,一个非常重要的一个缺点就在于,它必须顺序地执行,对于文本这样一个序列,它必须先计算得到第一个位置的一个表示,然后才可以往后计算文本第二个的一个表示,然后接着才能去计算第三个。而这样的模式,其实对于目前并行能力非常强大的GPU等专业设备来说,非常不友好,会造成很多资源浪费。
Transformer structure 模型结构
Transformer概述
首先回顾一下之前的RNN的一个端到端的模型,以下是一个典型的两层的LSTM模型,我们可以发现,这样一个RNN模型,一个非常重要的一个缺点就在于,它必须顺序地执行,对于文本这样一个序列,它必须先计算得到第一个位置的一个表示,然后才可以往后计算文本第二个的一个表示,然后接着才能去计算第三个。
而这样的模式,其实对于目前并行能力非常强大的GPU等专业设备来说,非常不友好,会造成很多资源浪费。
然后其次是尽管RNN有很多变体,比如说GRU、LSTM,但是它依然需要依靠前面提到的注意力机制,来解决像信息瓶颈这样的一些问题
考虑到RNN的这些所有的缺点,我们是否能够抛弃RNN的模型结构来来做文本的一些任务?这个答案显然是肯定的,研究人员在2017年发表的这篇文章,用他们的标题就直接回答了这个问题,这个标题叫attention is all you need,影响很大,后期也出现了很多类似xxx is all you need的论文,这篇文章中,模型作者就提出了一个非常强大的模型结构,来进行机器翻译的任务,这个结构就是接下来要讲的Transformer

我们首先来整体看一下这样一个Transformer 的整体结构,可以看到,它同样是一个encoder和decoder的模型,他的encoder端我们用红色框来框出,decoder端用蓝色的部分来表示
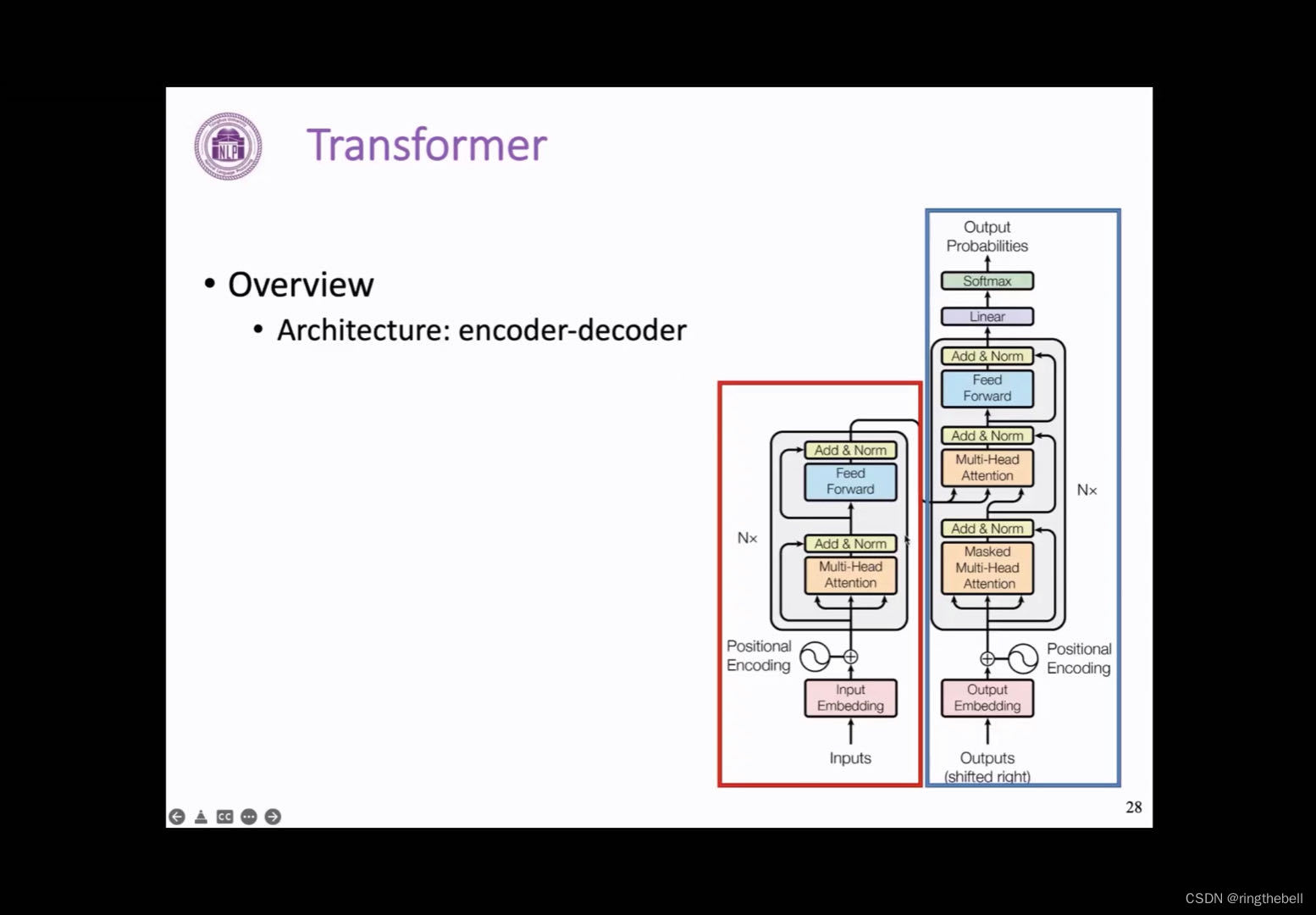


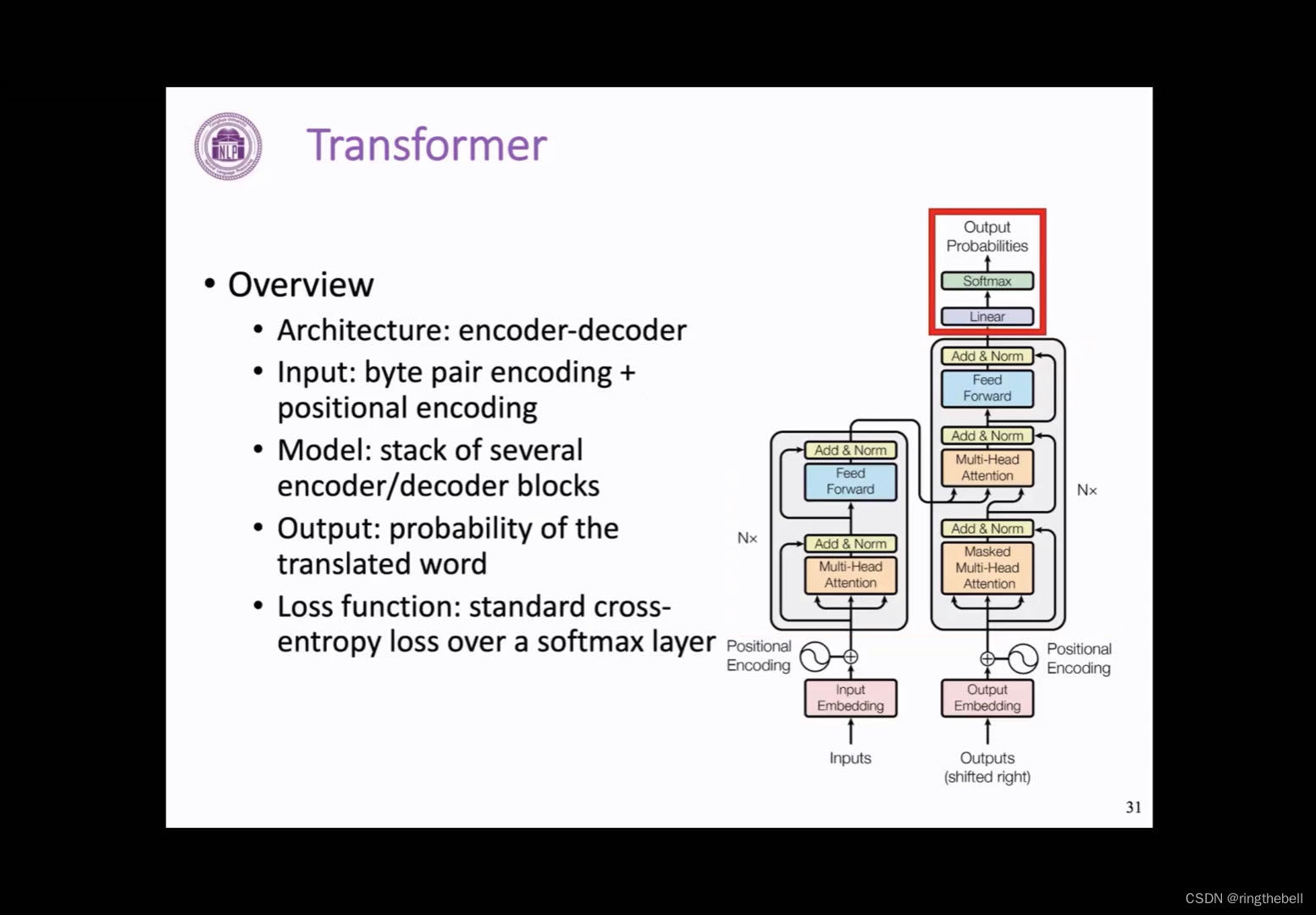
input encoding输入层(输入编码BPE、PE)





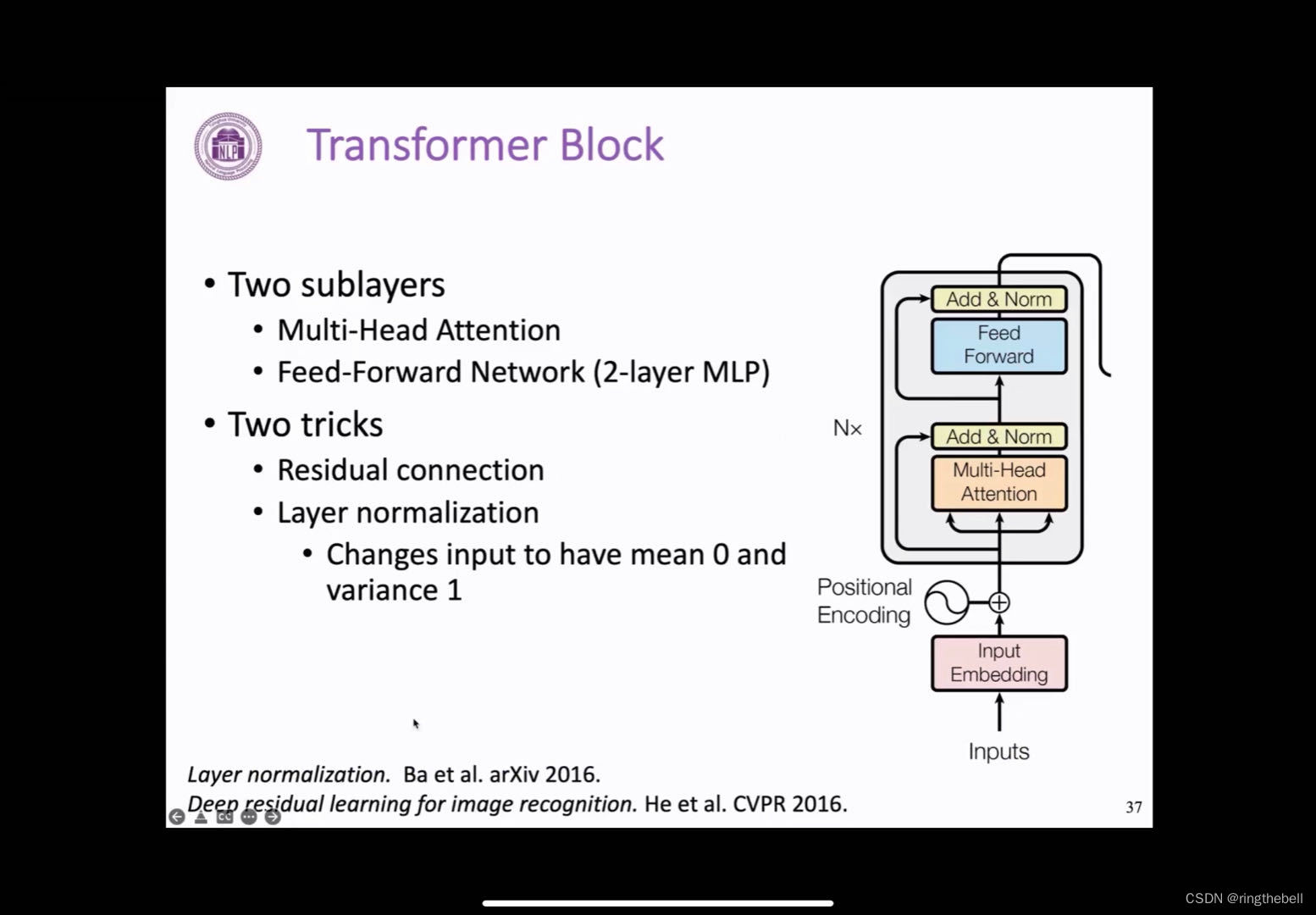
encoder block-核心(Transformer block)


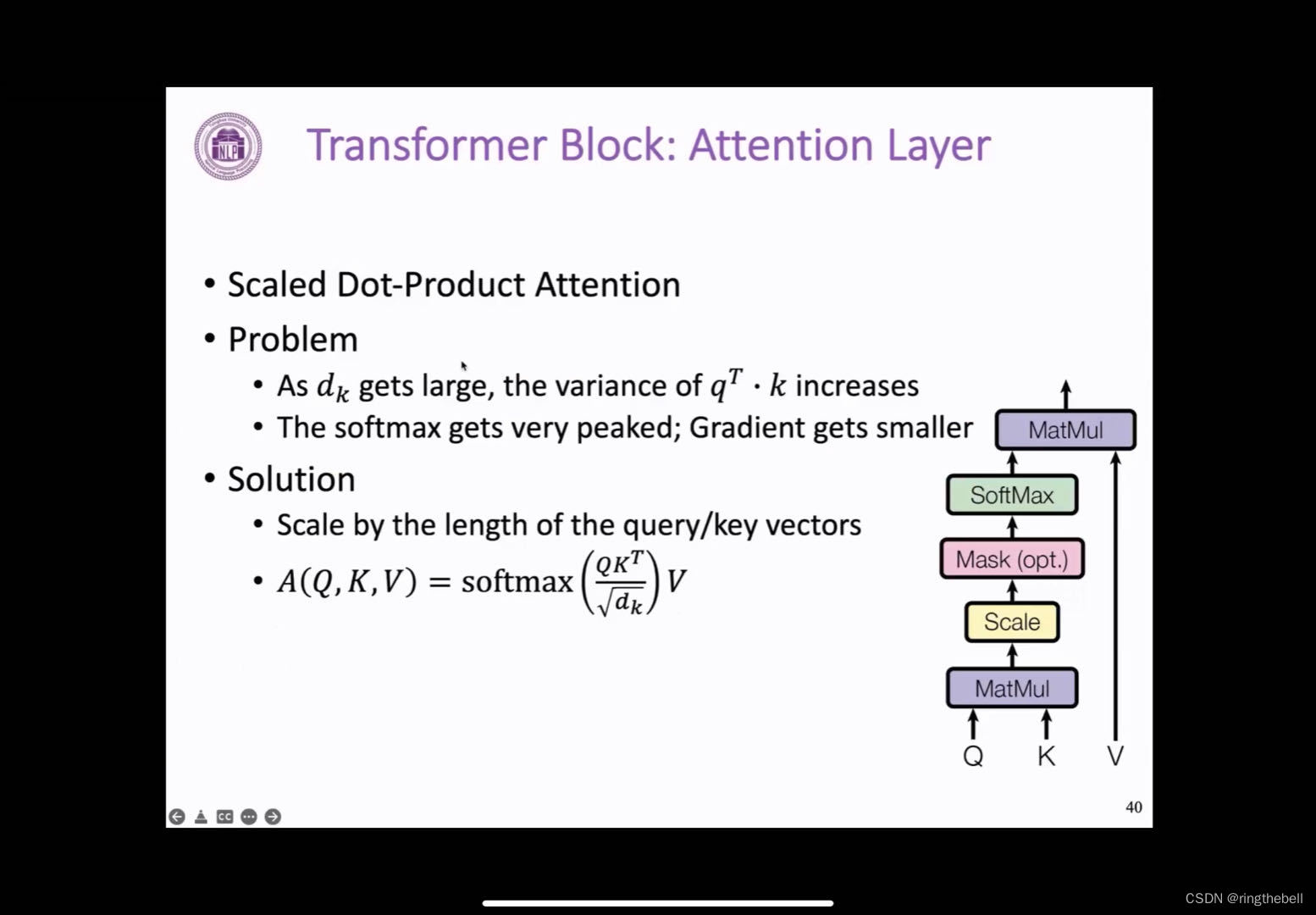


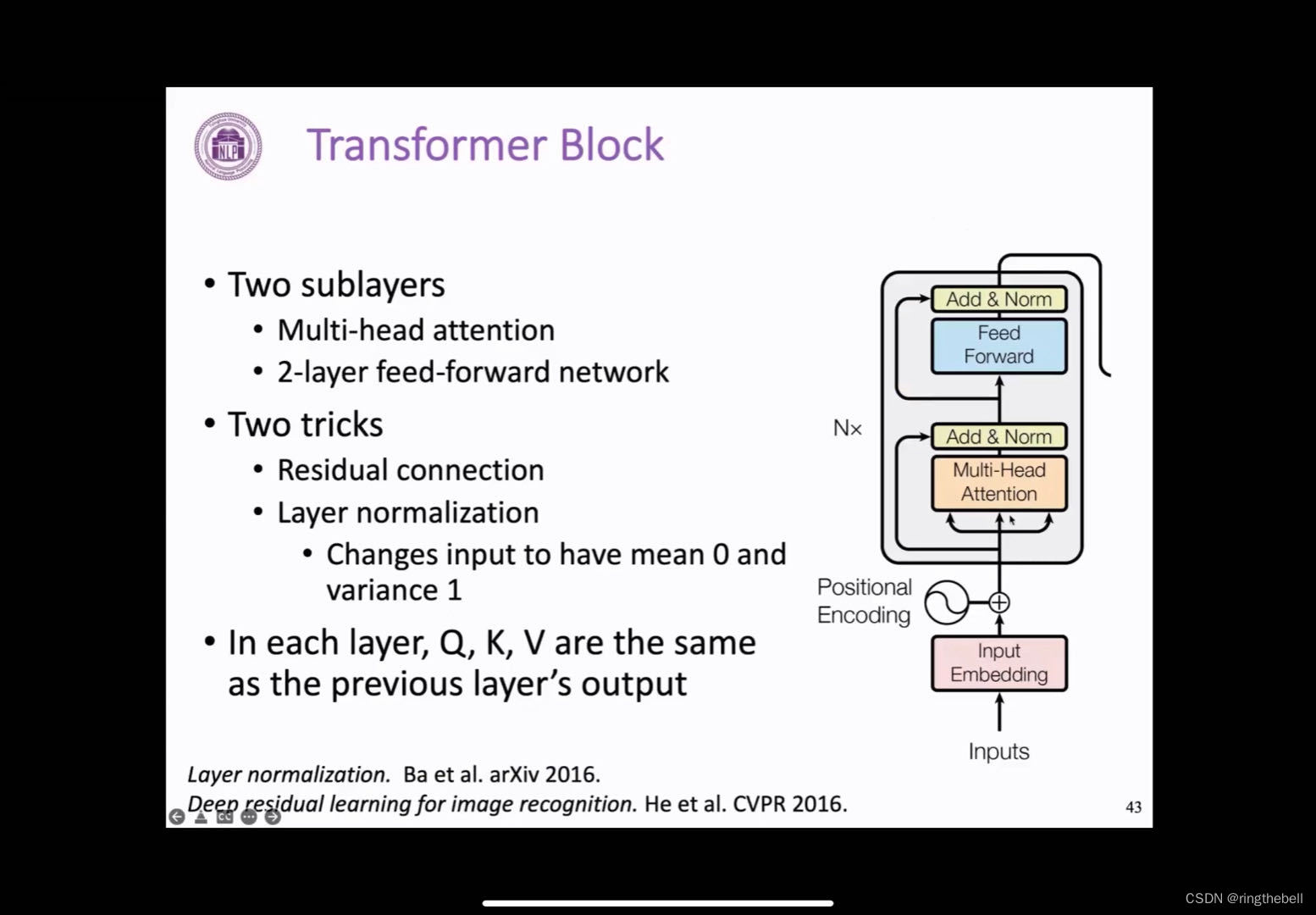
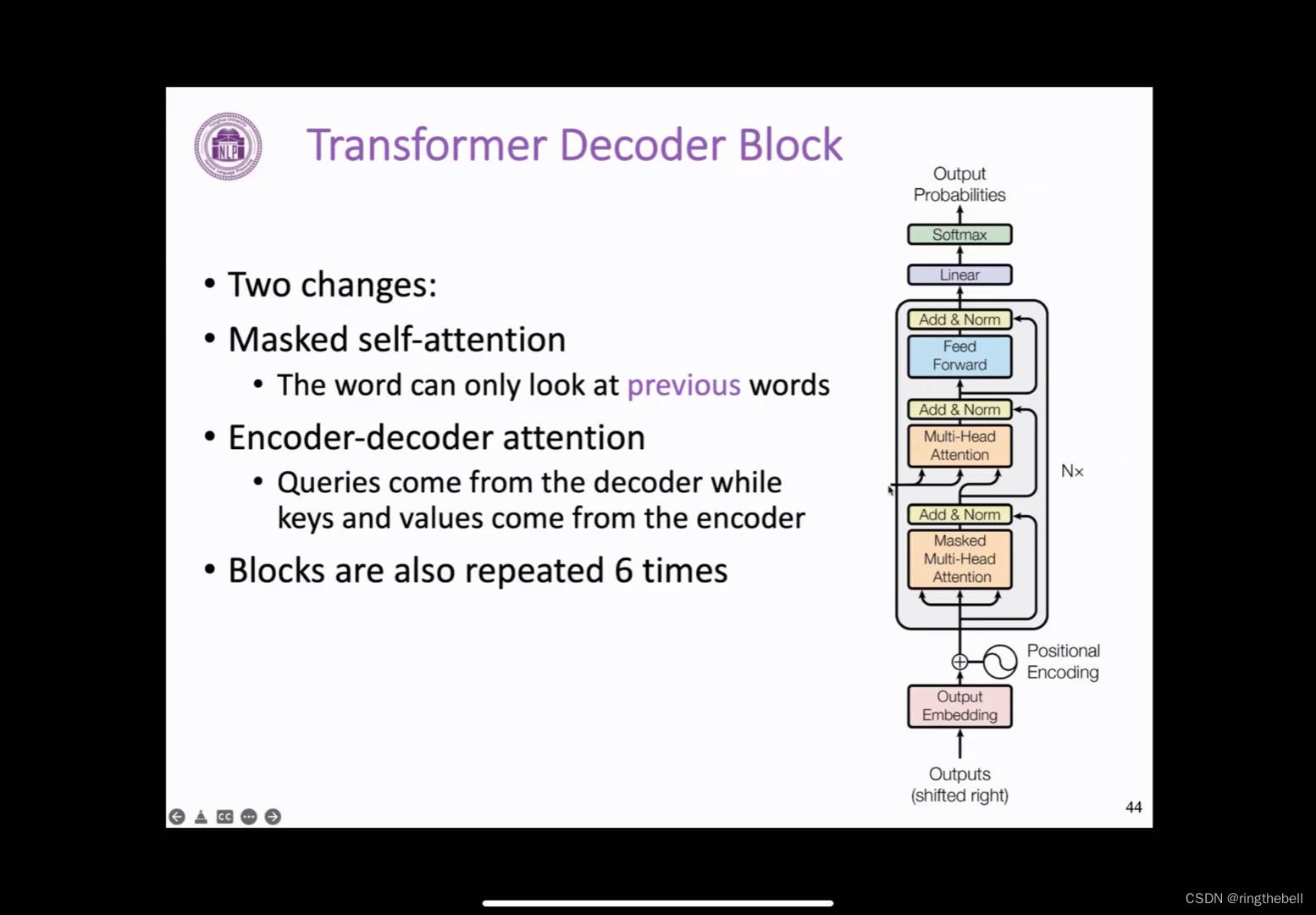
Transformer decoder block

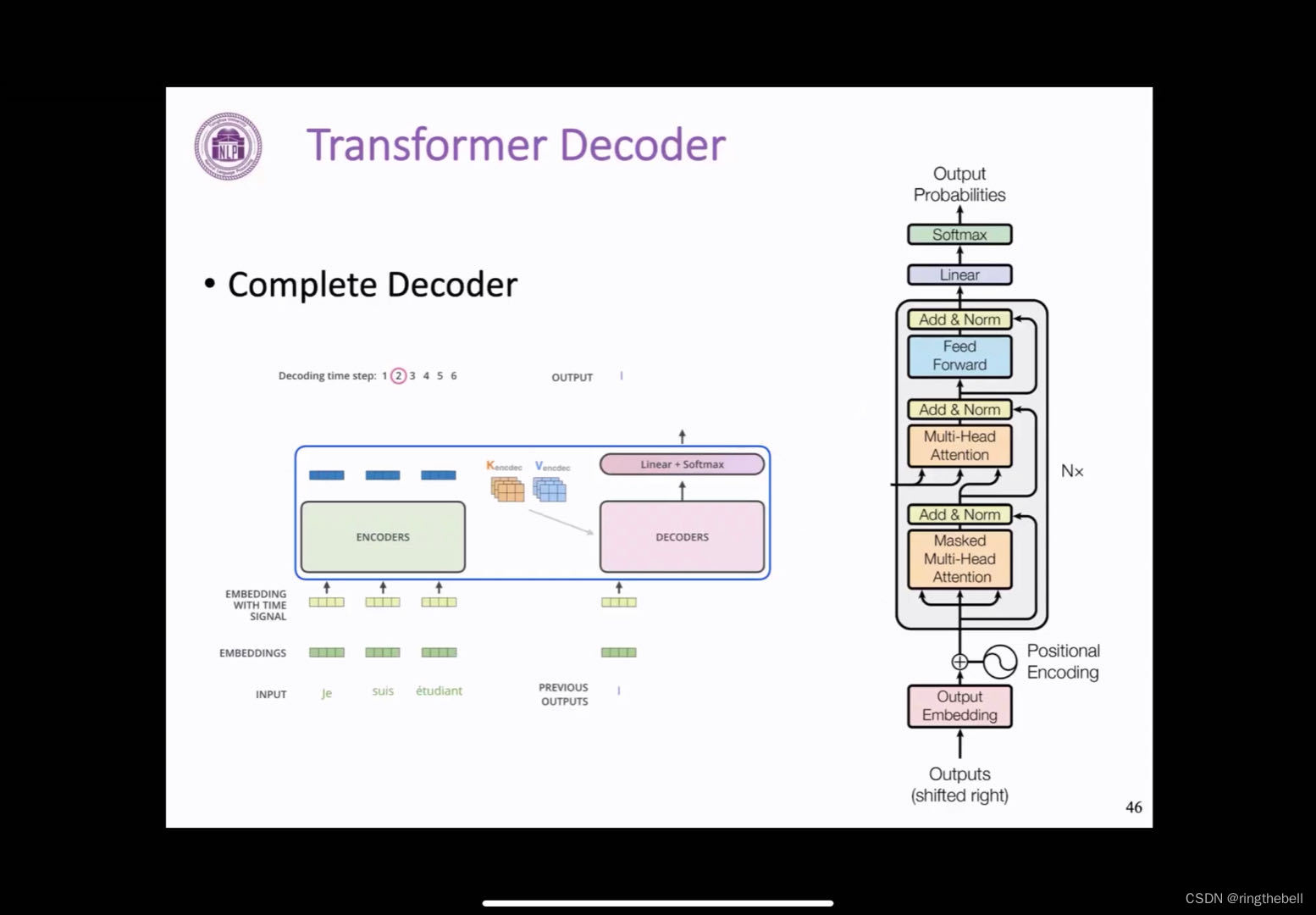
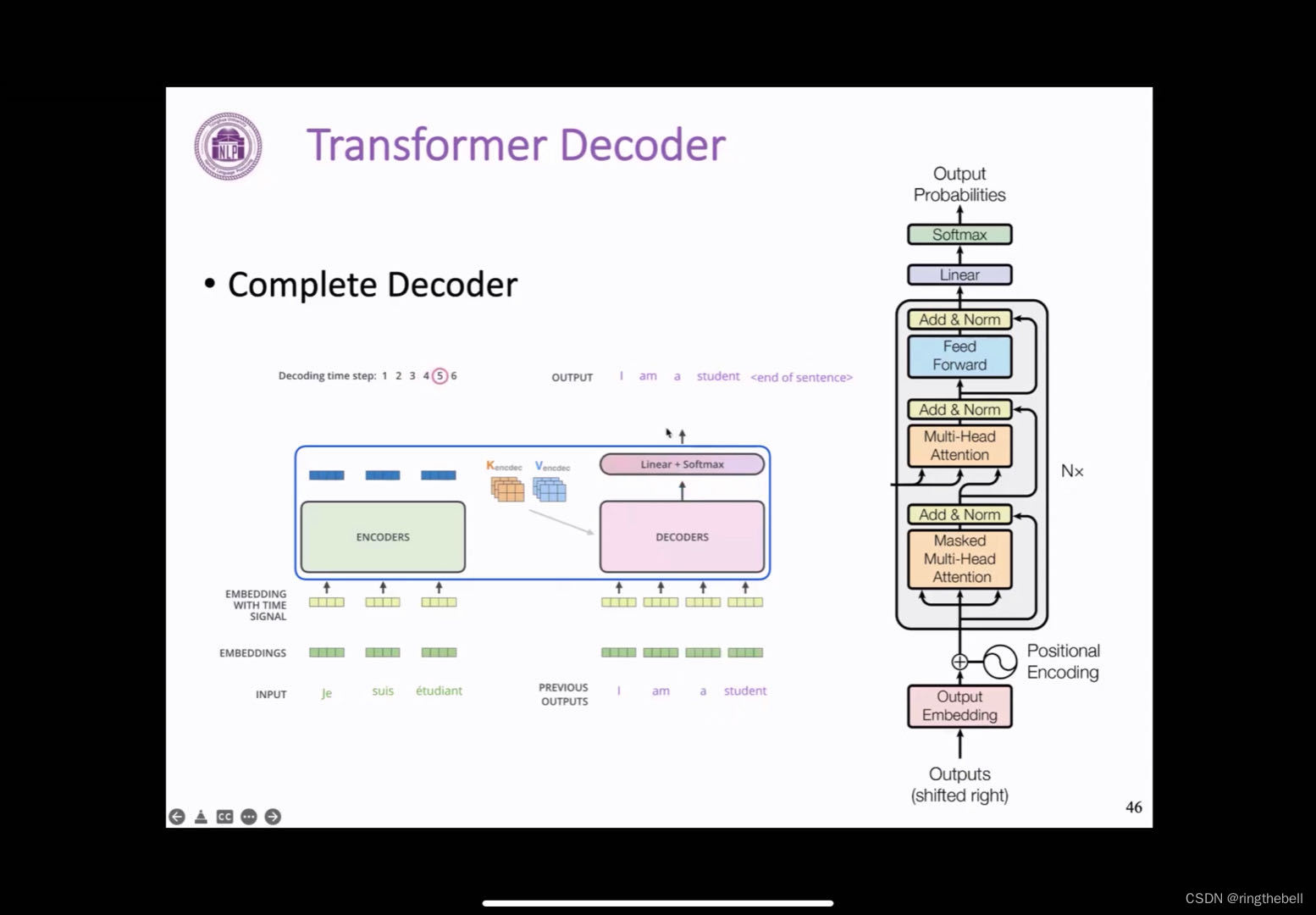
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






