本文介绍: Hadoop伪分布式安装配置A、添加hadoop用户 B、配置本地YUM源 C、SSH无密码配置 D、Hadoop安装与配置 E、配置HDFSF、HDFS常用命令参考
A、添加hadoop用户
1、添加用户组
2、添加用户并分配用户组
3、修改hadoop用户密码
B、配置本地YUM源
1、上传系统安装镜像到虚拟机服务器的/root目录
2、新建挂载点目录
3、挂载镜像
4、切换目录
5、新建备份目录
6、备份文件,把所有以Cent开头的文件全部备份移动到bakup目录中
7、新建YUM源文件,添加如下内容
[local]
name=local
baseurl=file:///mnt/centos
enabled=1
gpgcheck=0
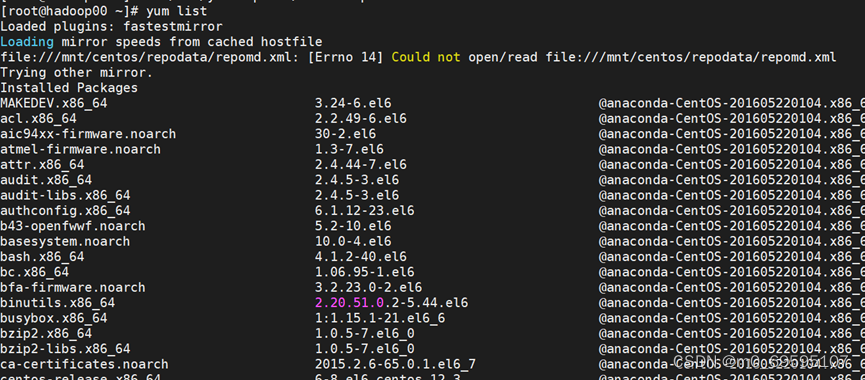
8、验证YUM源,出现如下可用包,表示本地YUM源配置成功。
C、SSH无密码配置
1、查看软件openssh与rsync安装状态
2、安装openssh与rsync
3、切换到hadoop用户
4、生成SSH密码对
5、将id_dsa.pub追加到授权的key文件中
6、设置授权key文件权限
7、测试ssh连接

无需输入密码,即可完成登录,表示SSH配置成功。
D、Hadoop安装与配置
1、将Hadoop安装压缩包hadoop-2.7.3.tar.gz,上传至/root目录
2、将压缩包解压至/usr目录
3、修改文件夹名称
4、将hadoop文件夹授权给hadoop用户
5、设置环境变量
6、使环境变量生效
7、测试环境变量设置

E、配置HDFS
1、切换至Hadoop用户
2、修改hadoop-env.sh
3、修改core-site.xml
4、修改hdfs-site.xml
5、格式化hdfs
6、启动hdfs
7、查看进程
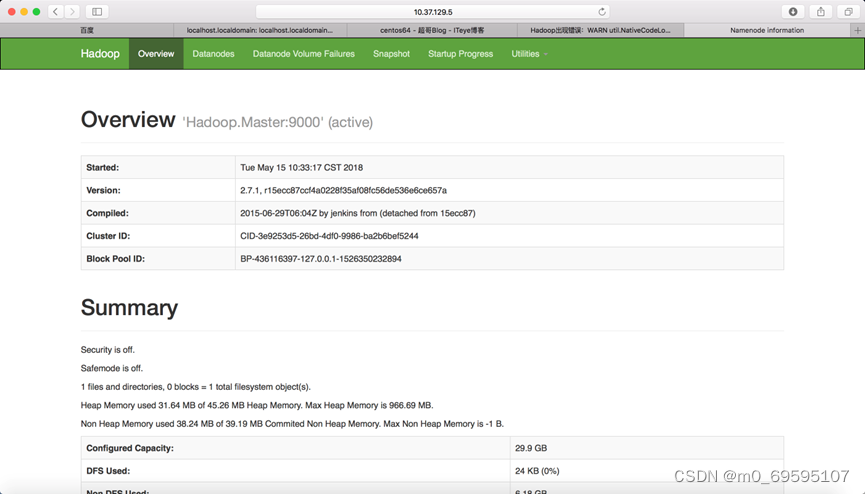
8、使用web浏览器查看Hadoop运行状态
http://你的服务器ip地址:50070/
9、在HDFS上运行WordCount:
1)创建HDFS用户目录
2)复制输入文件(要处理的文件)到HDFS上
3)查看我们复制到HDFS上的文件
4)运行单词检索(grep)程序
5)查看运行结果
10、配置YARN
1)修改mapred-site.xml
2)修改yarn-site.xml
3)启动YARN
4)查看当前java进程
5)(输出如下)
6)运行你的mapReduce程序
7)使用web查看Yarn运行状态
http://你的服务器ip地址:8088/
F、HDFS常用命令参考
1、创建HDFS文件夹
1)在根目录创建input文件夹
[hadoop@hadoop00 ~]$ hdfs dfs -mkdir -p /input
2)在用户目录创建input文件夹
说明:如果不指定“/目录”,则默认在用户目录创建文件夹
[hadoop@hadoop00 ~]$ hdfs dfs -mkdir -p input
2、查看HDFS文件夹
1)查看HDFS根文件夹
[hadoop@hadoop00 ~]$ hdfs dfs -ls /
2)查看HDFS用户目录文件夹
3)查看HDFS用户目录文件夹下input文件夹
[hadoop@hadoop00 ~]$ hdfs dfs -ls input
3、复制文件到HDFS
[hadoop@hadoop00 ~]$ hdfs dfs -put /usr/hadoop/etc/hadoop input
4、删除文件夹
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





