本文介绍: 如果说钢铁侠中的(贾维斯)是一个AGI通用人工智能的话,那么现阶段的AI Agent只是做到了感知任务、规划任务、执行任务。下面这张图的这个过程,看上去和强化学习是一模一样的。Agent结构图——参考视频[1]参考文章或视频链接[1]【动画科普AI Agent:大模型之后为何要卷它?[2]【【卢菁老师说】Agent就是一场彻头彻尾的AI泡沫】- bilibili[3]《读懂AI Agent:基于大模型的人工智能代理》[4]
一、理论
1.1 理论研读
1.2 什么是AI Agent?
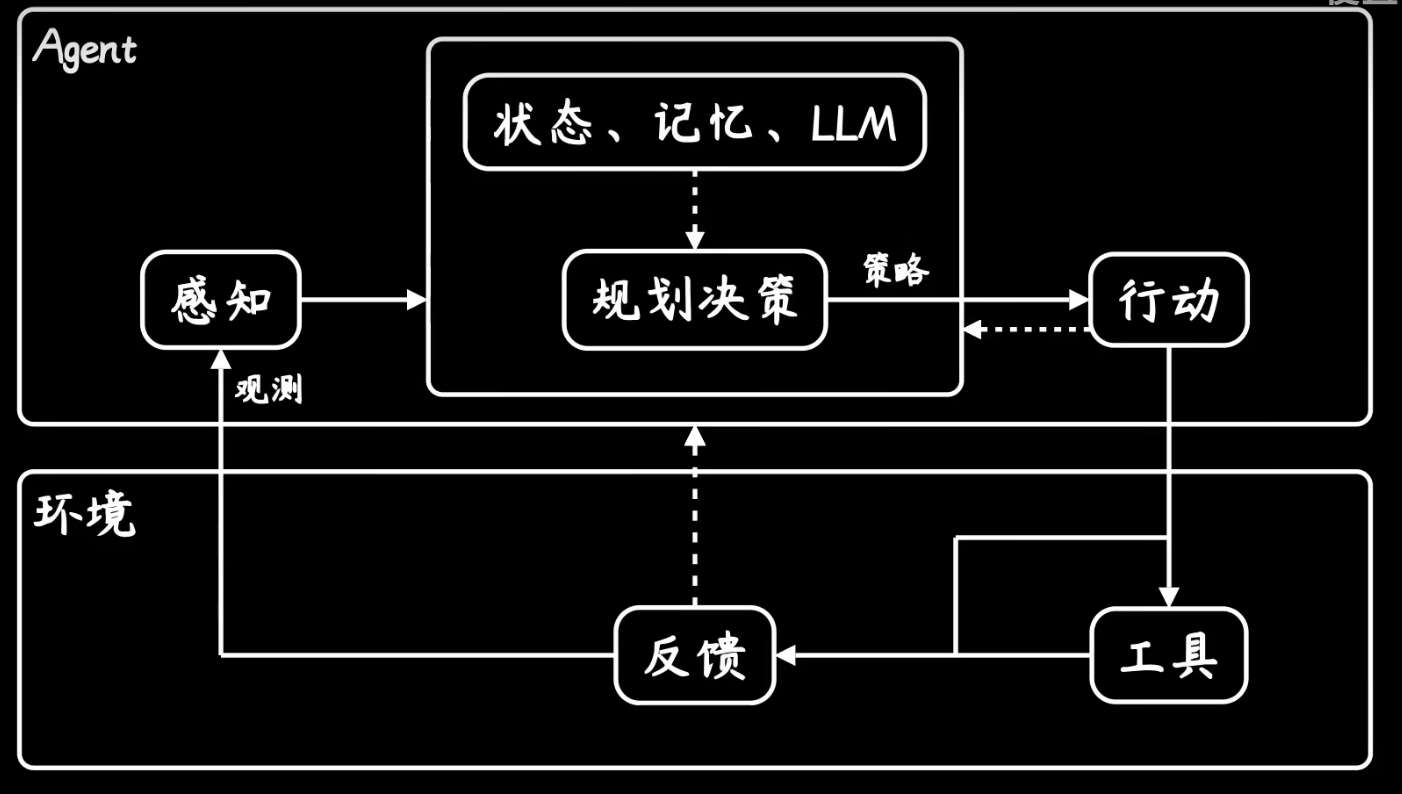
Agent结构图——参考视频[1]
二、实战
2.1 先导知识
2.1.1 tensor的创建与使用
对于一维的tensor,它是没有形状而言的,你不能准确的称它为行向量row vector或列向量col vector,只有你明确的指定之后,它才有准确的形状。
但是,在数学中肯定是要有明确的意义的,要么n*1,要么1*n,总得有个说法,说法就是,认为是列向量n*1,见参考文章[2]。
2.1.2 PyTorch的模块
2.1.2.1 torch.nn.Module类的继承与使用
强调一点,你自己实现的所有模块,应该都是继承了nn.Module这个Class的(这也是PyTorch官方文档所强调的),不要觉得可以去掉nn.Module的继承,继承了这个类,才会有一些便捷的方法可供调用,否则你都要自己实现一遍。
2.1.2.2 torch.nn.Linear类
关于Linear层有一点问题,就是它的权重矩阵,nn.Linear(4,3)中的4表示输入特征的维度,3表示输出特征的维度,按理来说是一个4 * 3的矩阵才对,但是输出结果偏不,这是因为常规的线性运算是写成这样的(假设维度已知),

2.2 Transformer代码实现
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。