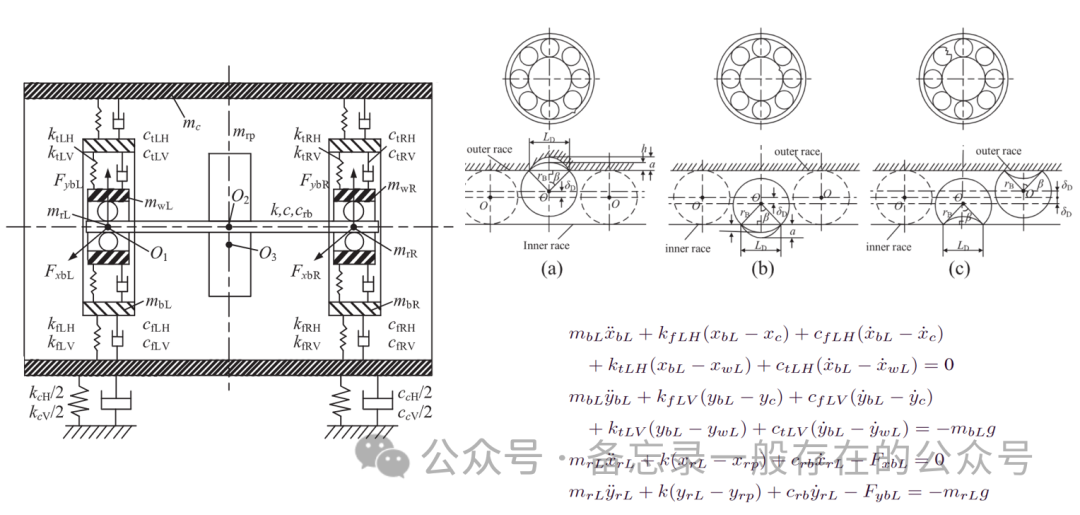
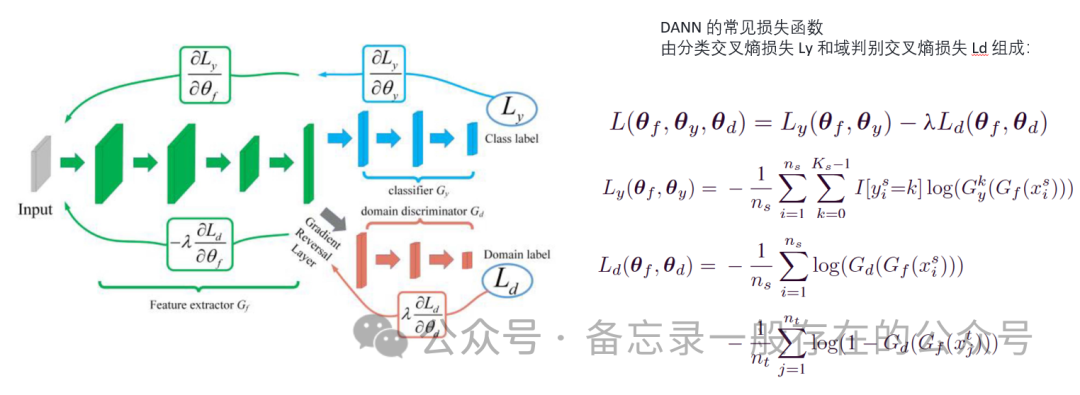
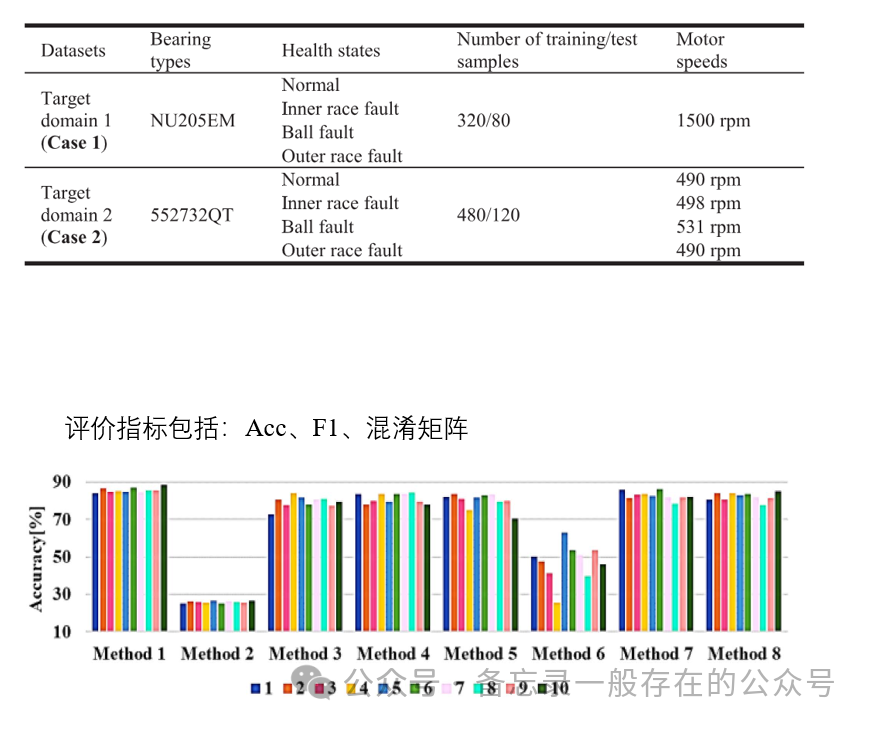
本文介绍: 得到的仿真数据时域图如下,可以看到仿真数据与试验台得到的数据的形态是非常非常不一致的,但是细看的话他们是有略微相似之处。比如以内圈为例,一股一股的跟仿真的一股一股的在大体上的轮廓上是有一定相似度的,同样,这个滚子也是一样的,一股一股一股。这就是说这个物理的模型确实是蕴含了实验数据中的一些特征信息的,说明他们的领域适配是有一定道理的。②JMMD对齐源域和目标域的联合分布,DANN减少边缘分布差异,这两个可以同时帮助在无监督场景中调整他们的条件分布,克服了单独边缘分布对齐的局限性。8:仅使用权重分配机制。
标题:Novel Joint Transfer Network for Unsupervised Bearing Fault Diagnosis From Simulation Domain to Experimental Domain
期刊:IEEE-ASME TRANSACTIONS ON MECHATRONICS (2022)
作者:Yiming Xiao, Haidong Shao,SongYu Han, Zhiqiang Huo,and Jiafu Wan
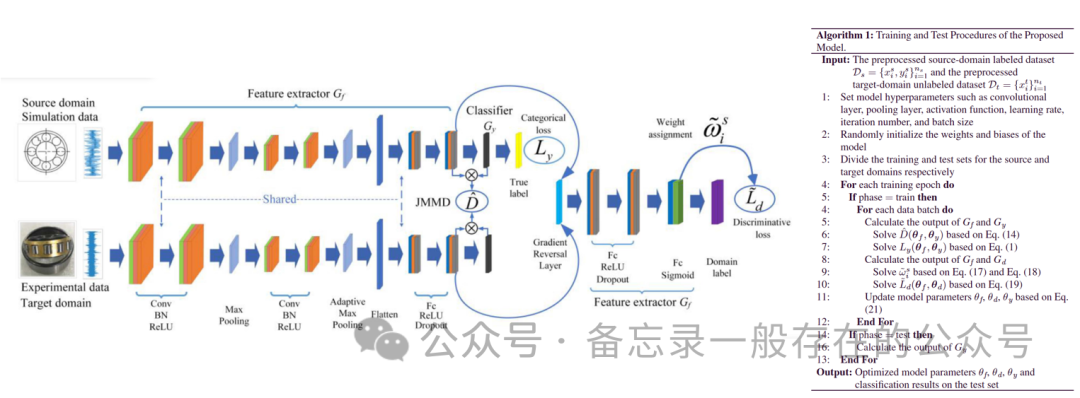
解决的问题:迁移诊断场景仅限于实验域,跨域边缘分布和条件分布难以同时对齐,每个源域样本在域自适应过程中被分配同等重要。



声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。