本文介绍: 本节主要介绍基本 SIMD 及其他的指令流与数据流的处理方式,NEON 的基本原理、指令以及与其他平台及硬件的对比。期望大家都能有所收获。
目录
1. SISD(Single Instruction Single Data)
2. MISD(Multiple Instruction Single Data)
一、SIMD

A. 指令流与数据流

1. SISD(Single Instruction Single Data)
2. MISD(Multiple Instruction Single Data)
3. MIMD(Mutiple Instruction Mutiple Data)
4. SIMT(Single Instruction Multiple Threads)
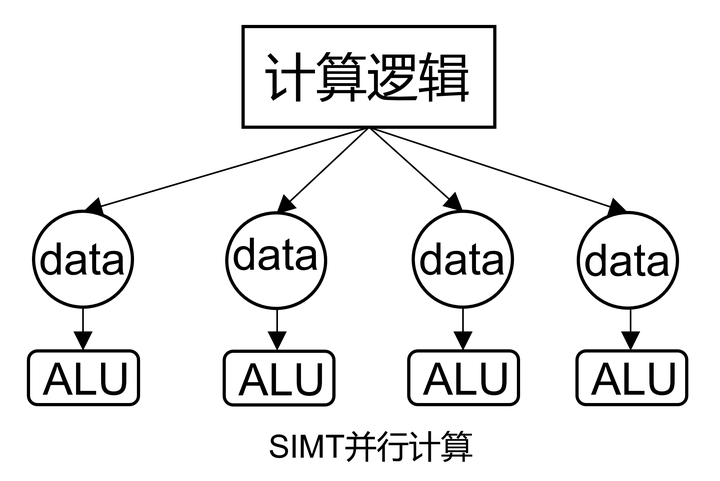
B. SIMD 特点及发展趋势
1. SIMD 优势与不足
2. SIMD发展趋势

二、 ARM 的 SIMD 指令集
1. ARM 处理器的 SIMD 支持 – NEON

2. ARM 处理器的 SIMD 支持检查
2.1 编译阶段检查
2.2 运行阶段检查
3. 指令集关系
三、NEON
1. NEON基本原理
1.1 NEON 指令执行流程

1.2 NEON 计算资源
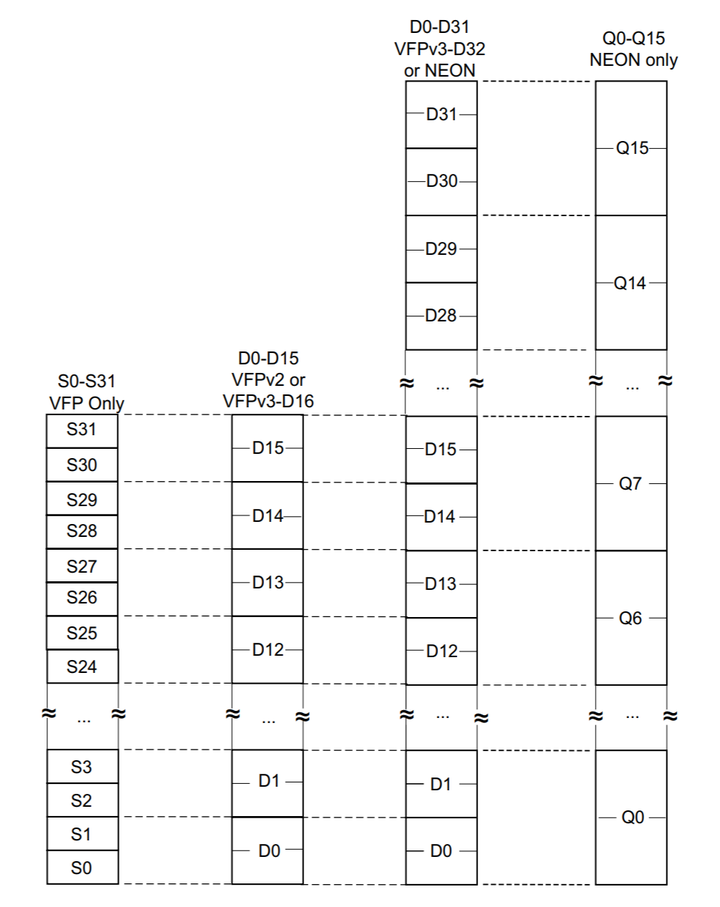
2. NEON指令
2.1 自动矢量化
2.2 NEON汇编

2.3 NEON Intrinsics
四、其他 SIMD 技术
1. 其他平台上的 SIMD 技术
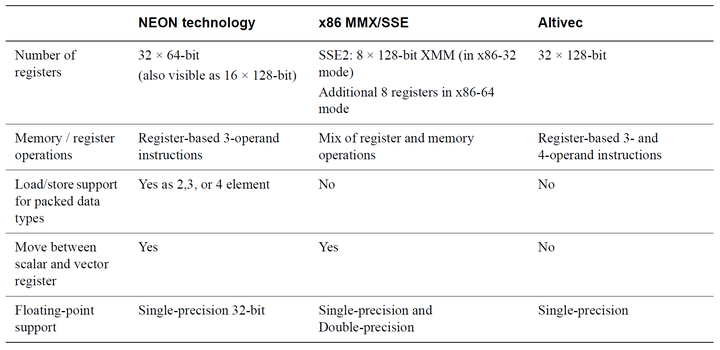
2. 与专用 DSP 对比
四、总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)