《Linux设备驱动开发详解》读书笔记
本书主要介绍linux设备驱动开发的方法,共有21章:
- linux设备驱动概述及开发环境搭建
- 驱动设计的硬件基础
- linux内核及内核编程
- linux内核模块
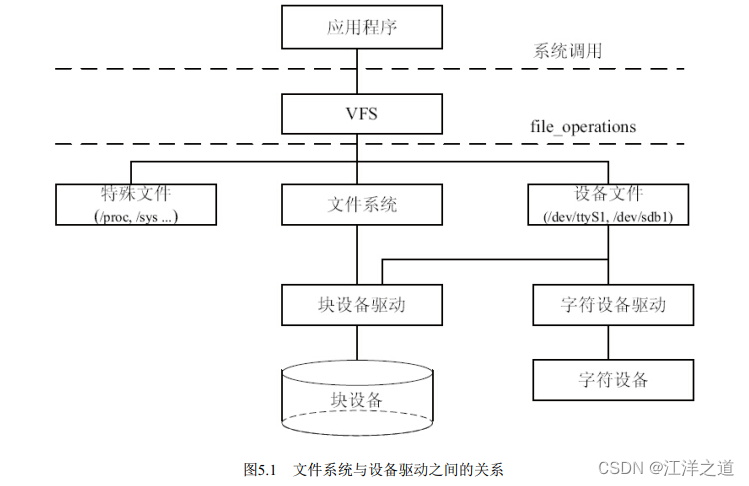
- linux文件系统与设备文件
- 字符设备驱动
- linux设备驱动中的并发控制
- linux设备驱动中的阻塞与非阻塞I/O
- linux设备驱动中的异步通知与异步I/O
- 中断与时钟
- 内存与I/O访问
- linux设备驱动的软件架构思想
- linux块设备驱动
- linux网络设备驱动
- I2c核心、总线与设备驱动
- USB主机、设备与Gadget驱动
- I2C/SPI/USB驱动架构类比
- ARM linux设备树
- linux电源管理的系统架构和驱动
- linux芯片级移植及底层驱动
- linux设备驱动的调试
linux设备驱动概述及开发环境搭建
linux将存储器和外设分为3个基础大类:
- 字符设备
- 块设备
- 网络设备
字符设备是指那些必须以串行顺序依次进行访问的设备。
块设备可以按任意顺序进行访问,以块为单位进行操作。
网络设备面向数据包的接收和发送而设计,并不倾向于对应于文件系统的节点。
(开发环境搭建部分在书里是用QEMU模拟的硬件,我这里是有实际的板子,因此没有仔细研究)
驱动设计的硬件基础
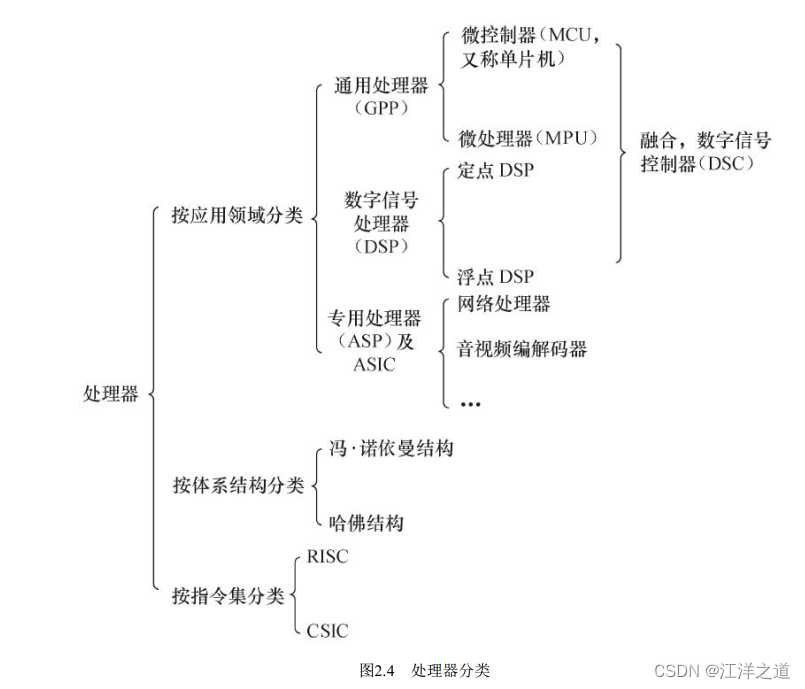
处理器
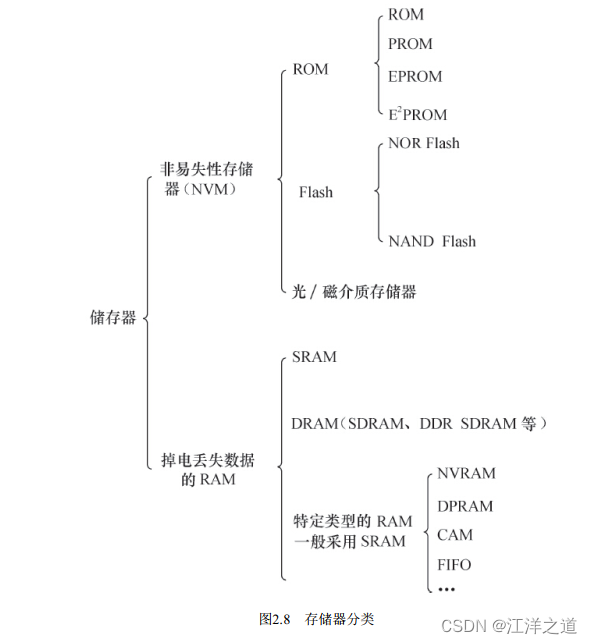
存储器
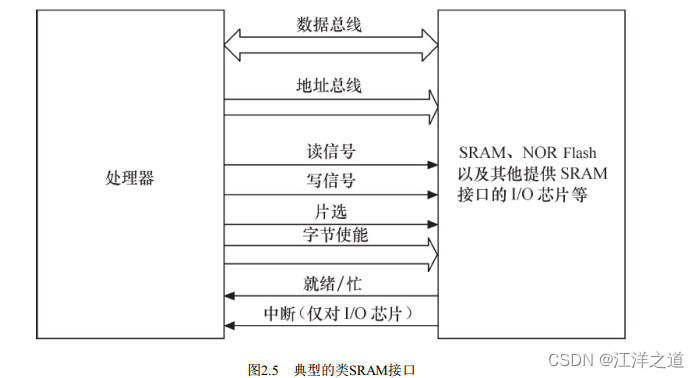
接口与总线
串口
1969年发布的RS-232修改版RS-232C是嵌入式系统中应用最广泛的串行接口, 它为连接DTE(数据终端设备) 与
DCE(数据通信设备) 而制定。 RS-232C标准接口有25条线(4条数据线、 11条控制线、 3条定时线、 7条备用和未定
义线) , 常用的只有9根, 它们是RTS/CTS(请求发送/清除发送流控制) 、 RxD/TxD(数据收发) 、 DSR/DTR(数
据终端就绪/数据设置就绪流控制) 、 DCD(数据载波检测, 也称RLSD, 即接收线信号检出) 、 Ringing-RI(振铃指
示) 、 SG(信号地) 信号。 RTS/CTS、 RxD/TxD、 DSR/DTR等信号的定义如下:
·RTS: 用来表示DTE请求DCE发送数据, 当终端要发送数据时, 使该信号有效。
·CTS: 用来表示DCE准备好接收DTE发来的数据, 是对RTS的响应信号。
·RxD: DTE通过RxD接收从DCE发来的串行数据。
·TxD: DTE通过TxD将串行数据发送到DCE。
·DSR: 有效(ON状态) 表明DCE可以使用。
·DTR: 有效(ON状态) 表明DTE可以使用。
·DCD: 当本地DCE设备收到对方DCE设备送来的载波信号时, 使DCD有效, 通知DTE准备接收, 并且由DCE将接收到的载波信号解调为数字信号, 经RxD线送给DTE。
·Ringing-RI: 当调制解调器收到交换台送来的振铃呼叫信号时, 使该信号有效(ON状态) , 通知终端, 已被呼叫。
最简单的RS-232C串口只需要连接RxD、 TxD、 SG这3个信号, 并使用XON/XOFF软件流控。
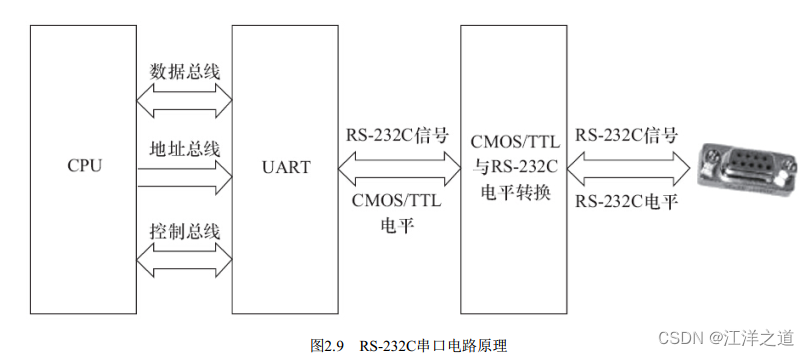
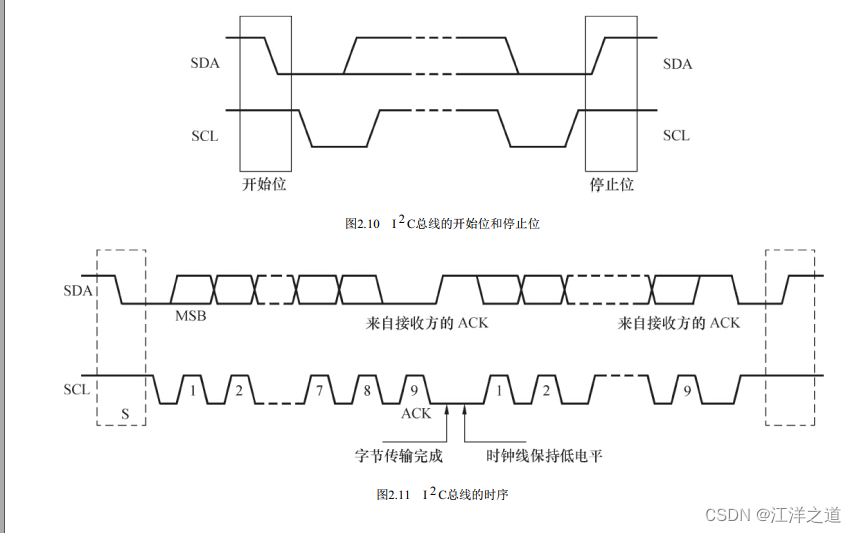
I2C
I2C总线支持多主控( Multi-Mastering) 模式, 任何能够进行发送和接收的设备都可以成为主设备。 主控能够控制数据的传输和时钟频率, 在任意时刻只能有一个主控。
组成I2C总线的两个信号为数据线SDA和时钟SCL。 为了避免总线信号的混乱, 要求各设备连接到总线的输出端必须是开漏输出或集电极开路输出的结构。 总线空闲时, 上拉电阻使SDA和SCL线都保持高电平。 根据开漏输出或集电极开路输出信号的“线与”逻辑, I2C总线上任意器件输出低电平都会使相应总线上的信号线变低。
“线与”逻辑指的是两个或两个以上的输出直接互连就可以实现“与”的逻辑功能, 只有输出端是开漏( 对于CMOS器件) 输出或集电极开路( 对于TTL器件) 输出时才满足此条件。 工程师一般以“OC门”简称开漏或集电极开路。
SPI
SPI( Serial Peripheral Interface, 串行外设接口) 总线系统是一种同步串行外设接口, 它可以使CPU与各种外围设备以串行方式进行通信以交换信息。 一般主控SoC作为SPI的“主”, 而外设作为SPI的“从”。
SPI接口一般使用4条线: 串行时钟线( SCLK) 、 主机输入/从机输出数据线MISO、 主机输出/从机输入数据线MOSI和低电平有效的从机选择线SS.
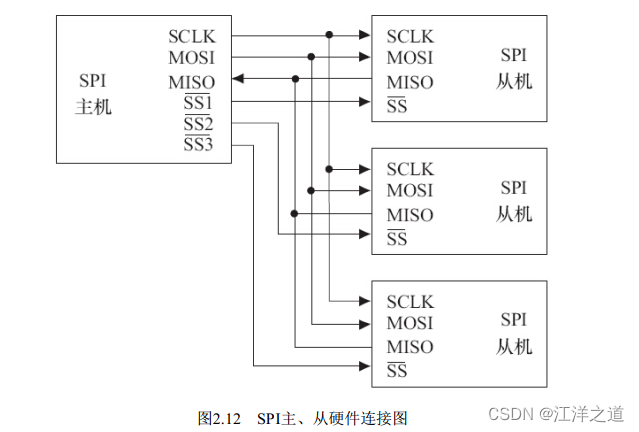
在SPI总线的传输中, SS信号是低电平有效的, 当我们要与某外设通信的时候, 需要将该外设上的SS线置低。 此外, 特别要注意SPI从设备支持的SPI总线最高时钟频率( 决定了SCK的频率) 以及外设的CPHA、 CPOL模式, 这决定了数据与时钟之间的偏移、 采样的时刻以及触发的边沿是上升沿还是下降沿。
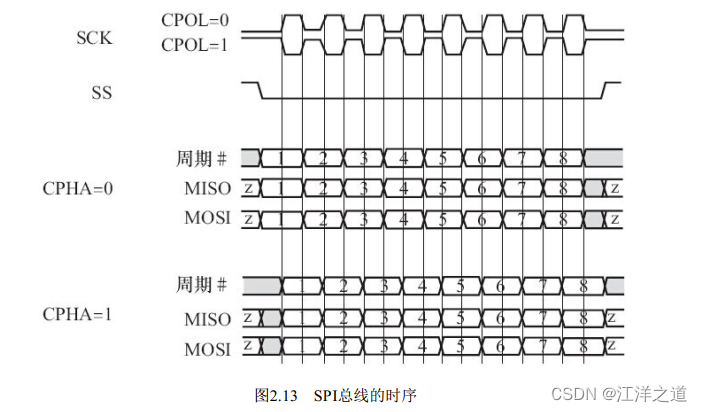 SPI模块为了和外设进行数据交换, 根据外设工作要求, 其输出串行同步时钟极性( CPOL) 和相位( CPHA) 可以进行配置。 如果CPOL=0, 串行同步时钟的空闲状态为低电平; 如果CPOL=1, 串行同步时钟的空闲状态为高电平。 如果CPHA=0, 在串行同步时钟的第一个跳变沿( 上升或下降) 数据被采样; 如果CPHA=1, 在串行同步时钟的第二个跳变沿( 上升或下降) 数据被采样.
SPI模块为了和外设进行数据交换, 根据外设工作要求, 其输出串行同步时钟极性( CPOL) 和相位( CPHA) 可以进行配置。 如果CPOL=0, 串行同步时钟的空闲状态为低电平; 如果CPOL=1, 串行同步时钟的空闲状态为高电平。 如果CPHA=0, 在串行同步时钟的第一个跳变沿( 上升或下降) 数据被采样; 如果CPHA=1, 在串行同步时钟的第二个跳变沿( 上升或下降) 数据被采样.
USB
USB( 通用串行总线)1.1包含全速和低速两种模式, 低速方式的速率为1.5Mbit/s, 支持一些不需要很大数据吞吐量和很高实时性的设备, 如鼠标等。 全速模式为12Mbit/s, 可以外接速率更高的外设。 在USB 2.0中, 增加了一种高速方式, 数据传输率达到480Mbit/s, 半双工, 可以满足更高速外设的需要。 而USB 3.0( 也被认为是Super Speed USB) 的最大传输带宽高达5.0Gbit/s( 即640MB/s) , 全双工。
USB 2.0总线的机械连接非常简单, 采用4芯的屏蔽线, 一对差分线( D+、 D-) 传送信号, 另一对( VBUS、 电源地) 传送+5V的直流电。 USB 3.0线缆则设计了8条内部线路, 除VBUS、 电源地之外, 其余3对均为数据传输线路。 其中保留了D+与D-这两条兼容USB 2.0的线路, 新增了SSRX与SSTX专为USB 3.0所设的线路。
在嵌入式系统中, 电路板若需要挂接USB设备, 则需提供USB主机( Host) 控制器和连接器; 若电路板需要作为USB设备, 则需提供USB设备适配器和连接器。 目前, 大多数SoC集成了USB主机控制器( 以连接USB外设) 和
设备适配器( 以将本嵌入式系统作为其他计算机系统的USB外设, 如手机充当U盘) 。
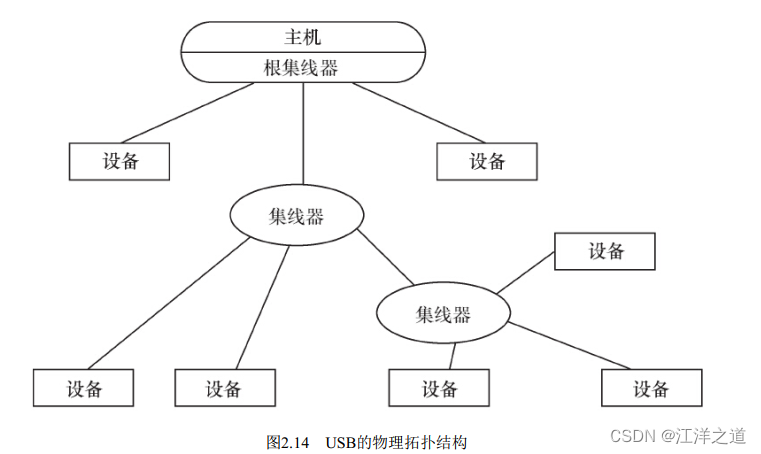
每一个USB设备会有一个或者多个逻辑连接点在里面, 每个连接点叫端点。 USB提供了多种传输方式以适应各种设备的需要, 一个端点可以选择如下一种传输方式。
1.控制( Control) 传输方式
控制传输是双向传输, 数据量通常较小, 主要用来进行查询、 配置和给USB设备发送通用命令。 所有USB设备必须支持标准请求( Standard Request) , 控制传输方式和端点0。
2.同步( Isochronous) 传输方式
同步传输提供了确定的带宽和间隔时间, 它用于时间要求严格并具有较强容错性的流数据传输, 或者用于要求恒定数据传送率的即时应用。 例如进行语音业务传输时, 使用同步传输方式是很好的选择。 同步传输也常称
为“Streaming Real-time”传输。
3.中断( Interrupt) 传输方式
中断方式传送是单向的, 对于USB主机而言, 只有输入。 中断传输方式主要用于定时查询设备是否有中断数据要传送, 该传输方式应用在少量分散的、 不可预测的数据传输场合, 键盘、 游戏杆和鼠标属于这一类型。
4.批量( Bulk) 传输方式批量传输主要应用在没有带宽、 间隔时间要求的批量数据的传送和接收中, 它要求保证传输。 打印机和扫描仪属于这种类型。
而USB 3.0则增加了一种Bulk Streams传输模式, USB 2.0的Bulk模式只支持1个数据流, 而Bulk Streams传输模式则可以支持多个数据流, 每个数据流被分配一个Stream ID(SID) , 每个SID与一个主机缓冲区对应。
在USB架构中, 集线器负责检测设备的连接和断开, 利用其中断IN端点(Interrupt IN Endpoint) 来向主机报告。一旦获悉有新设备连接上来, 主机就会发送一系列请求给设备所挂载的集线器, 再由集线器建立起一条连接主机和设备之间的通信通道。 然后主机以控制传输的方式, 通过端点0对设备发送各种请求, 设备收到主机发来的请求后回复相应的信息, 进行枚举(Enumerate) 操作。 因此USB总线具备热插拔的能力。
以太网接口
以太网接口由MAC(以太网媒体接入控制器) 和PHY(物理接口收发器) 组成。 以太网MAC由IEEE 802.3以太网标准定义, 实现了数据链路层。 常用的MAC支持10Mbit/s或100Mbit/s两种速率。 吉比特以太网(也称为千兆位以太网) 是快速以太网的下一代技术, 将网速提高到了1000Mbit/s。 千兆位以太网以IEEE 802.3z和802.3ab发布, 作为IEEE 802.3标准的补充。
MAC和PHY之间采用MII(媒体独立接口) 连接, 它是IEEE-802.3定义的以太网行业标准, 包括1个数据接口与MAC和PHY之间的1个管理接口。 数据接口包括分别用于发送和接收的两条独立信道, 每条信道都有自己的数据、 时钟和控制信号, MII数据接口总共需要16个信号。 MII管理接口包含两个信号, 一个是时钟信号, 另一个是数据信号。 通过管理接口, 上层能监视和控制PHY。
一个以太网接口的硬件电路原理如图2.15所示, 从CPU到最终接口依次为CPU、 MAC、 PHY、 以太网隔离变压器、 RJ45插座。 以太网隔离变压器是以太网收发芯片与连接器之间的磁性组件, 在其两者之间起着信号传输、 阻抗匹配、 波形修复、 信号杂波抑制和高电压隔离作用。
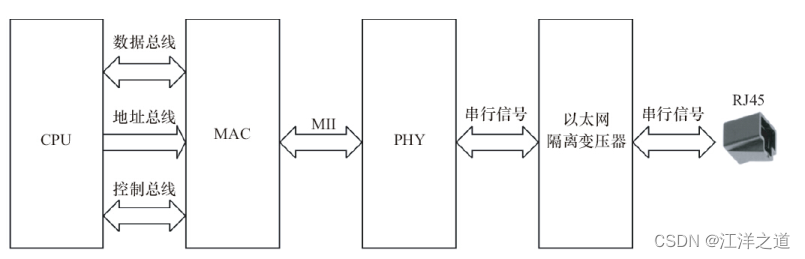
许多处理器内部集成了MAC或同时集成了MAC和PHY, 另有许多以太网控制芯片也集成了MAC和PHY。
PCI和PCI-E
PCI(外围部件互连) 是由Intel于1991年推出的一种局部总线, 作为一种通用的总线接口标准, 它在目前的计算
机系统中得到了非常广泛应用。 PCI总线具有如下特点。
·数据总线为32位, 可扩充到64位。
·可进行突发(Burst) 模式传输。 突发方式传输是指取得总线控制权后连续进行多个数据的传输。 突发传输时,只需要给出目的地的首地址, 访问第1个数据后, 第2~n个数据会在首地址的基础上按一定规则自动寻址和传输。 与突发方式对应的是单周期方式, 它在1个总线周期只传送1个数据。
·总线操作与处理器—存储器子系统操作并行。
·采用中央集中式总线仲裁。
·支持全自动配置、 资源分配, PCI卡内有设备信息寄存器组为系统提供卡的信息, 可实现即插即用。
·PCI总线规范独立于微处理器, 通用性好。
·PCI设备可以完全作为主控设备控制总线。
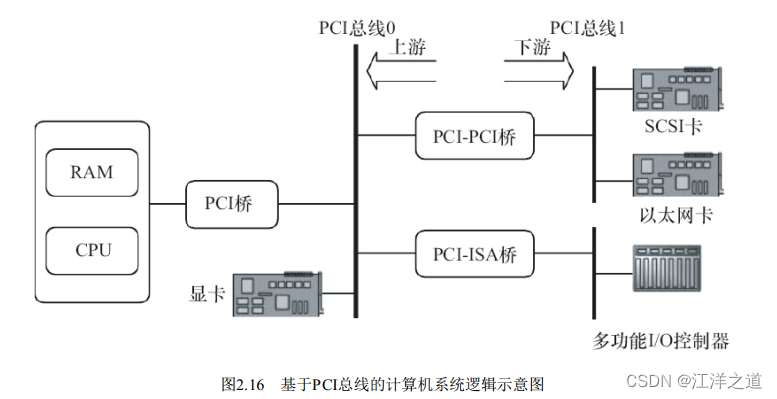
图2.16给出了一个典型的基于PCI总线的计算机系统逻辑示意图, 系统的各个部分通过PCI总线和PCI-PCI桥连接在一起。 CPU和RAM通过PCI桥连接到PCI总线0(即主PCI总线) , 而具有PCI接口的显卡则可以直接连接到主PCI总线上。 PCI-PCI桥是一个特殊的PCI设备, 它负责将PCI总线0和PCI总线1(即从PCI主线) 连接在一起, 通常PCI总线1称为PCI-PCI桥的下游(Downstream) , 而PCI总线0则称为PCI-PCI桥的上游(Upstream) 。 为了兼容旧的ISA总线标准, PCI总线还可以通过PCI-ISA桥来连接ISA总线, 从而支持以前的ISA设备。
 当PCI卡刚加电时, 卡上配置空间即可以被访问。 PCI配置空间保存着该卡工作时所需的所有信息, 如厂家、 卡
当PCI卡刚加电时, 卡上配置空间即可以被访问。 PCI配置空间保存着该卡工作时所需的所有信息, 如厂家、 卡
功能、 资源要求、 处理能力、 功能模块数量、 主控卡能力等。 通过对这个空间信息的读取与编程, 可完成对PCI
卡的配置。 如图2.17所示, PCI配置空间共为256字节, 主要包括如下信息。
·制造商标识(Vendor ID) : 由PCI组织分配给厂家。
·设备标识(Device ID) : 按产品分类给本卡的编号。
·分类码(Class Code) : 本卡功能的分类码, 如图卡、 显示卡、 解压卡等。
·申请存储器空间: PCI卡内有存储器或以存储器编址的寄存器和I/O空间, 为使驱动程序和应用程序能访问它
们, 需申请CPU的一段存储区域以进行定位。 配置空间的基地址寄存器用于此目的。
·申请I/O空间: 配置空间中的基地址寄存器用来进行系统I/O空间的申请。
·中断资源申请: 配置空间中的中断引脚和中断线用来向系统申请中断资源。 偏移3Dh处为中断引脚寄存器, 其
值表明PCI设备使用了哪一个中断引脚, 对应关系为1—INTA#、 2—INTB#、 3—INTC#、 4—INTD#。
 PCI-E(PCI Express) 是Intel公司提出的新一代的总线接口, PCI Express采用了目前业内流行的点对点串行连接, 比起PCI以及更早的计算机总线的共享并行架构, 每个设备都有自己的专用连接, 采用串行方式传输数据,不需要向整个总线请求带宽, 并可以把数据传输率提高到一个很高的频率, 达到PCI所不能提供的高带宽。
PCI-E(PCI Express) 是Intel公司提出的新一代的总线接口, PCI Express采用了目前业内流行的点对点串行连接, 比起PCI以及更早的计算机总线的共享并行架构, 每个设备都有自己的专用连接, 采用串行方式传输数据,不需要向整个总线请求带宽, 并可以把数据传输率提高到一个很高的频率, 达到PCI所不能提供的高带宽。
PCI Express在软件层面上兼容目前的PCI技术和设备, 支持PCI设备和内存模组的初始化, 也就是说无须推倒目前的驱动程序、 操作系统, 就可以支持PCI Express设备。
SD和SDIO
SD(Secure Digital) 是一种关于Flash存储卡的标准, 也就是一般常见的SD记忆卡, 在设计上与MMC(Multi-Media Card) 保持了兼容。
SDHC(SD High Capacity) 是大容量SD卡, 支持的最大容量为32GB。 2009年发布的SDXC(SD eXtended Capacity) 则支持最大2TB大小的容量。
SDIO(Secure Digital Input and Output Card, 安全数字输入输出卡) 在SD标准的基础上, 定义了除存储卡以外的外设接口。 SDIO主要有两类应用——可移动和不可移动。 不可移动设备遵循相同的电气标准, 但不要求符合物理标准。 现在已经有非常多的手机或者手持装置都支持SDIO的功能, 以连接WiFi、 蓝牙、 GPS等模块。
一般情况下, 芯片内部集成的SD控制器同时支持MMC、 SD卡, 又支持SDIO卡, 但是SD和SDIO的协议还是有不一样的地方, 支持的命令也会有不同。
SD/SDIO的传输模式有:
·SPI模式
·1位模式
·4位模式
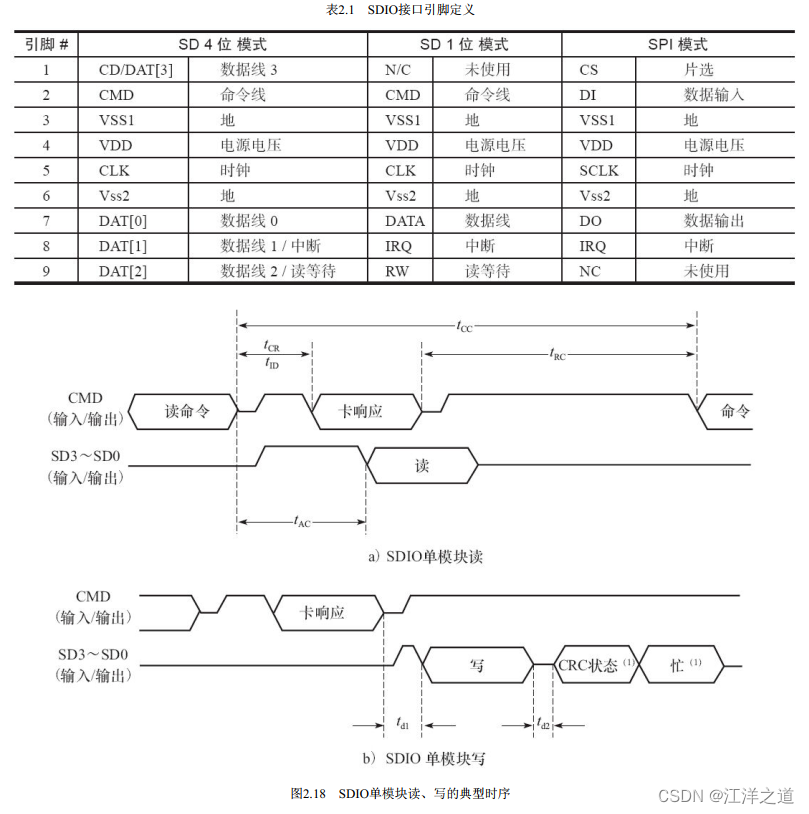
表2.1显示了SDIO接口的引脚定义。 其中CLK为时钟引脚, 每个时钟周期传输一个命令或数据位; CMD是命令引脚, 命令在CMD线上串行传输, 是双向半双工的(命令从主机到从卡, 而命令的响应是从卡发送到主机) ; DAT[0]~DAT[3]为数据线引脚; 在SPI模式中, 第8脚位被当成中断信号。 图2.18给出了一个SDIO单模块读、 写的典型时序。
eMMC( Embedded Multi Media Card) 是当前移动设备本地存储的主流解决方案, 目的在于简化手机存储器的设计。 eMMC就是NAND Flash、 闪存控制芯片和标准接口封装的集合, 它把NAND和控制芯片直接封装在一起成为一个多芯片封装( Multi-Chip Package, MCP) 芯片。 eMMC支持DAT[0]~DAT[7]8位的数据线。 上电或者复位后, 默认处于1位模式, 只使用DAT[0], 后续可以配置为4位或者8位模式。
CPLD和FPGA
CPLD(复杂可编程逻辑器件) 由完全可编程的与或门阵列以及宏单元构成。
CPLD中的基本逻辑单元是宏单元, 宏单元由一些“与或”阵列加上触发器构成, 其中“与或”阵列完成组合逻辑功能, 触发器完成时序逻辑功能。 宏单元中与阵列的输出称为乘积项, 其数量标示着CPLD的容量。 乘积项阵列实际上就是一个“与或”阵列, 每一个交叉点都是一个可编程熔丝, 如果导通就是实现“与”逻辑。 在“与”阵列后一般还有一个“或”阵列, 用以完成最小逻辑表达式中的“或”关系。 图2.19所示为非常典型的CPLD的单个宏单元结构。
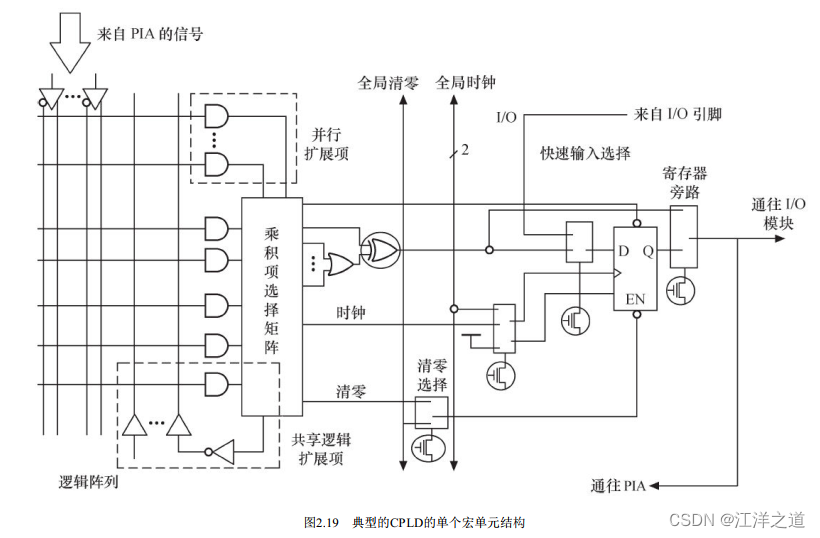
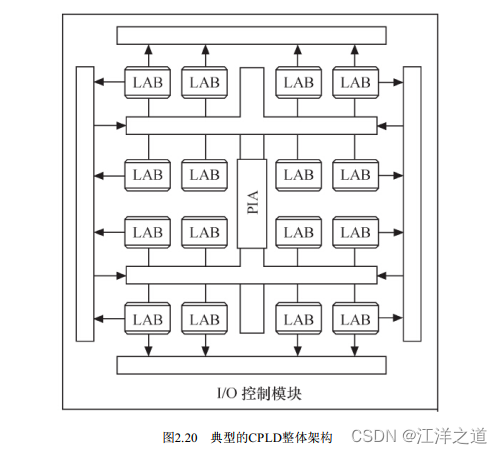
图2.20给出了一个典型CPLD的整体结构。 这个CPLD由LAB(逻辑阵列模块, 由多个宏单元组成) 通过PIA(可编程互连阵列) 互连组成,而CPLD与外部的接口则由I/O控制模块提供。宏单元的输出会经I/O控制块送至I/O引脚, I/O控制块控制每一个I/O引脚的工作模式, 决定其为输入、 输出还是双向引脚, 并决定其三态输出的使能端控制。
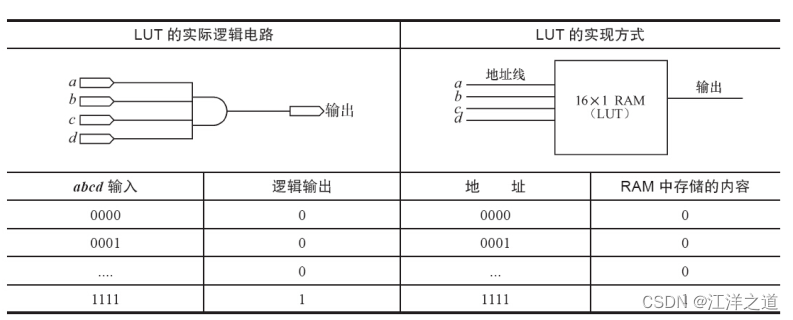
与CPLD不同, FPGA(现场可编程门阵列) 基于LUT(查找表) 工艺。 查找表本质上是一片RAM, 当用户通过原理图或HDL(硬件描述语言) 描述了一个逻辑电路以后, FPGA开发软件会自动计算逻辑电路所有可能的结果, 并把结果事先写入RAM。 这样, 输入一组信号进行逻辑运算就等于输入一个地址进行查表以输出对应地址的内容。
图2.21所示为一个典型FPGA的内部结构。 这个FPGA由IOC(输入/输出控制模块) 、 EAB(嵌入式阵列块) 、 LAB和快速通道互连构成。
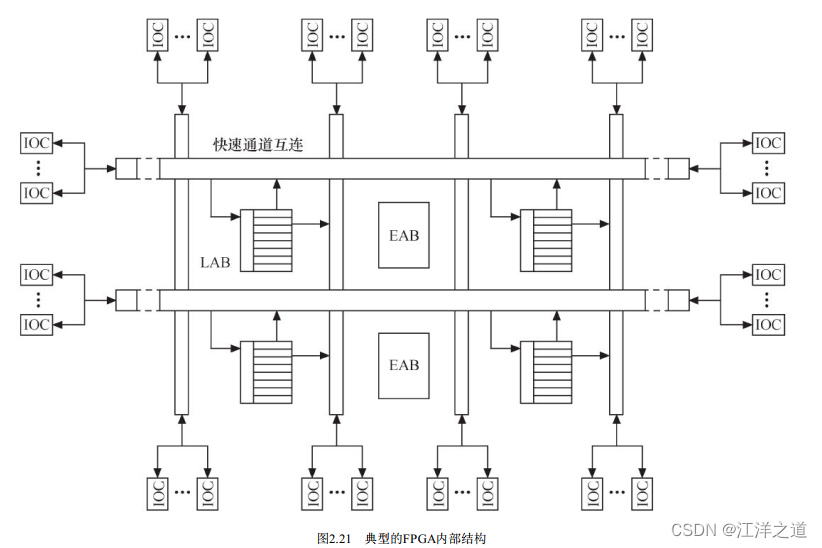 IOC是内部信号到I/O引脚的接口, 它位于快速通道的行和列的末端, 每个IOC包含一个双向I/O缓冲器和一个既可作为输入寄存器也可作为输出寄存器的触发器。
IOC是内部信号到I/O引脚的接口, 它位于快速通道的行和列的末端, 每个IOC包含一个双向I/O缓冲器和一个既可作为输入寄存器也可作为输出寄存器的触发器。
EAB(嵌入式存储块) 是一种输入输出端带有寄存器的非常灵活的RAM。 EAB不仅可以用作存储器, 还可以事先写入查表值以用来构成如乘法器、 纠错逻辑等电路。 当用于RAM时, EAB可配制成8位、 4位、 2位和1位长度的数据格式。
LAB主要用于逻辑电路设计, 一个LAB包括多个LE(逻辑单元) , 每个LE包括组合逻辑及一个可编程触发器。 一系列LAB构成的逻辑阵列可实现普通逻辑功能, 如计数器、 加法器、 状态机等。
器件内部信号的互连和器件引出端之间的信号互连由快速通道连线提供, 快速通道遍布于整个FPGA器件中, 是一系列水平和垂直走向的连续式布线通道。
表2.2所示为一个4输入LUT的实际逻辑电路与LUT实现方式的对应关系。
 CPLD和FPGA的主要厂商有Altera、 Xilinx和Lattice等, 它们采用专门的开发流程, 在设计阶段使用HDL(如VHDL、 Verilog HDL) 编程。 它们可以实现许多复杂的功能, 如实现UART、 I 2 C等I/O控制芯片、 通信算法、 音视频编解码算法等, 甚至还可以直接集成ARM等CPU内核和外围电路。
CPLD和FPGA的主要厂商有Altera、 Xilinx和Lattice等, 它们采用专门的开发流程, 在设计阶段使用HDL(如VHDL、 Verilog HDL) 编程。 它们可以实现许多复杂的功能, 如实现UART、 I 2 C等I/O控制芯片、 通信算法、 音视频编解码算法等, 甚至还可以直接集成ARM等CPU内核和外围电路。
对于驱动工程师而言, 我们只需要这样看待CPLD和FPGA: 如果它完成的是特定的接口和控制功能, 我们就直接把它当成由很多逻辑门(与、 非、 或、 D触发器) 组成的可完成一系列时序逻辑和组合逻辑的ASIC; 如果它完成的是CPU的功能, 我们就直接把它当成CPU。 驱动工程师眼里的硬件比IC设计师要宏观。
值得一提的是, Xilinx公司还推出了ZYNQ芯片, 内部同时集成了两个Cortex-A9ARM多处理器子系统和可编程逻辑FPGA, 同时可编程逻辑可由用户配置。
原理图分析
原理图的分析方法是以主CPU为中心向存储器和外设辐射, 步骤如下:
1) 阅读CPU部分, 获知CPU的哪些片选、 中断和集成的外设控制器在使用, 列出这些元素a、 b、 c、 …。
2) 对第1步中列出的元素, 从原理图中对应的外设和存储器电路中分析出实际的使用情况。
硬件时序分析
对驱动工程师或硬件工程师而言, 时序分析的意思是让芯片之间的访问满足芯片数据手册中时序图信号有效的先后顺序、 采样建立时间(Setup Time) 和保持时间(Hold Time) 的要求, 在电路板工作不正常的时候, 准确地定位时序方面的问题。
芯片数据手册阅读方法
以S3C6410A的数据手册为例来分析阅读方法
数据手册的第1章“PRODUCT OVERVIEW”(产品综述) 是必读的, 通过阅读这一部分可以获知整个芯片的组成。这一章往往会给出一个芯片的整体结构图, 并对芯片内的主要模块进行一个简洁的描述。
第2章“MemoryMap”(内存映射) 比较关键, 对于定位存储器和外设所对应的基址有直接指导意义, 这一部分应该细看。
第3~34章对应于CPU内部集成的外设或总线控制器, 当具体编写某接口的驱动时, 应该详细阅读, 主要是分析数据、 控制、地址寄存器(数据手册中一般会以表格列出) 的访问控制和具体设备的操作流程(数据手册中会给出步骤, 有的还会给出流程图) 。
第44章“ELECTRICAL DATA”(对于电气数据, 在图2.28中未画出) , 描述芯片的电气特性, 如电压、 电流和各种工作模式下的时序、 建立时间和保持时间的要求。 所有的数据手册都会包含类似章节, 这一章对于硬件工程师比较关键, 但是, 一般来说, 驱动工程师并不需要阅读。
第45章“MECHANICAL DATA”(机械数据) 描述芯片的物理特性、 尺寸和封装, 硬件工程师会依据这一章绘制芯片的封装(Footprint) , 但是, 驱动工程师无须阅读。
仪器仪表的使用
万用表
在电路板调试过程中主要使用万用表的两个功能。
·测量电平。
·使用二极管挡测量电路板上网络的连通性。
偶尔也会用来测量电流等
示波器
使用示波器时应主要注意调节垂直偏转因数选择(VOLTS/DIV) 和微调、 时基选择(TIME/DIV) 和微调以及触发方式。
逻辑分析仪
逻辑分析仪的波形可以显示地址、 数据、 控制信号及任意外部探头信号的变化轨迹, 在使用之前应先编辑每个探头的信号名。 之后, 根据波形还原出总线的工作时序, 图2.34给出了一个I 2 C的例子。 目前, 很多逻辑分析仪都自带了协议分析能力, 可以自动分析出总线上传输的命令、 地址和数据等信息。
Linux内核及内核编程
Linux内核的组成
linux内核源代码的目录结构
Linux内核源代码包含如下目录。
·arch: 包含和硬件体系结构相关的代码, 每种平台占一个相应的目录, 如i386、 arm、 arm64、 powerpc、 mips等。 Linux内核目前已经支持30种左右的体系结构。 在arch目录下, 存放的是各个平台以及各个平台的芯片对Linux内核进程调度、 内存管理、 中断等的支持, 以及每个具体的SoC和电路板的板级支持代码。
·block: 块设备驱动程序I/O调度。
·crypto: 常用加密和散列算法(如AES、 SHA等) , 还有一些压缩和CRC校验算法。
·documentation: 内核各部分的通用解释和注释。
·drivers: 设备驱动程序, 每个不同的驱动占用一个子目录, 如char、 block、 net、 mtd、 i2c等。
·fs: 所支持的各种文件系统, 如EXT、 FAT、 NTFS、 JFFS2等。
·include: 头文件, 与系统相关的头文件放置在include/linux子目录下。
·init: 内核初始化代码。 著名的start_kernel() 就位于init/main.c文件中。
·ipc: 进程间通信的代码。
·kernel: 内核最核心的部分, 包括进程调度、 定时器等, 而和平台相关的一部分代码放在arch//kernel目录下。
·lib: 库文件代码。
·mm: 内存管理代码, 和平台相关的一部分代码放在arch//mm目录下。
·net: 网络相关代码, 实现各种常见的网络协议。
·scripts: 用于配置内核的脚本文件。
·security: 主要是一个SELinux的模块。
·sound: ALSA、 OSS音频设备的驱动核心代码和常用设备驱动。
·usr: 实现用于打包和压缩的cpio等。
·include: 内核API级别头文件。
内核一般要做到drivers与arch的软件架构分离, 驱动中不包含板级信息, 让驱动跨平台。 同时内核的通用部分(如kernel、 fs、 ipc、 net等) 则与具体的硬件(arch和drivers) 剥离。
linux内核的组成部分
Linux内核主要由进程调度(SCHED) 、 内存管理(MM) 、 虚拟文件系统(VFS) 、 网络接口(NET) 和进程间通信(IPC) 5个子系统组成。
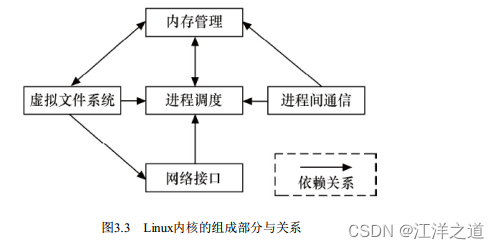
进程调度
在Linux内核中, 使用task_struct结构体来描述进程, 该结构体中包含描述该进程内存资源、 文件系统资源、 文件资源、 tty资源、 信号处理等的指针。 Linux的线程采用轻量级进程模型来实现, 在用户空间通过pthread_create() API创建线程的时候, 本质上内核只是创建了一个新的task_struct, 并将新task_struct的所有资源指针都指向创建它的那个task_struct的资源指针。
绝大多数进程(以及进程中的多个线程) 是由用户空间的应用创建的, 当它们存在底层资源和硬件访问的需求时, 会通过系统调用进入内核空间。 有时候, 在内核编程中, 如果需要几个并发执行的任务, 可以启动内核线程, 这些线程没有用户空间。 启动内核线程的函数为:
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags);
内存管理
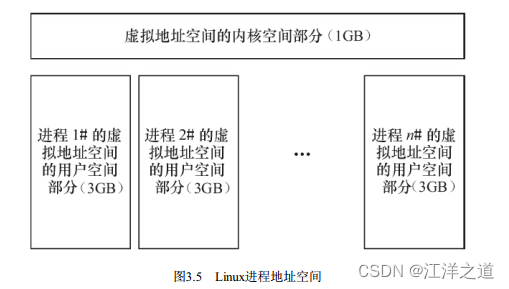
内存管理的主要作用是控制多个进程安全地共享主内存区域。 当CPU提供内存管理单元(MMU) 时, Linux内存管理对于每个进程完成从虚拟内存到物理内存的转换。 Linux 2.6引入了对无MMU CPU的支持。
如图3.5所示, 一般而言, 32位处理器的Linux的每个进程享有4GB的内存空间, 0~3GB属于用户空间, 3~4GB属于内核空间, 内核空间对常规内存、 I/O设备内存以及高端内存有不同的处理方式。 当然, 内核空间和用户空间的具体界限是可以调整的, 在内核配置选项Kernel Features→Memory split下, 可以设置界限为2GB或者3GB。
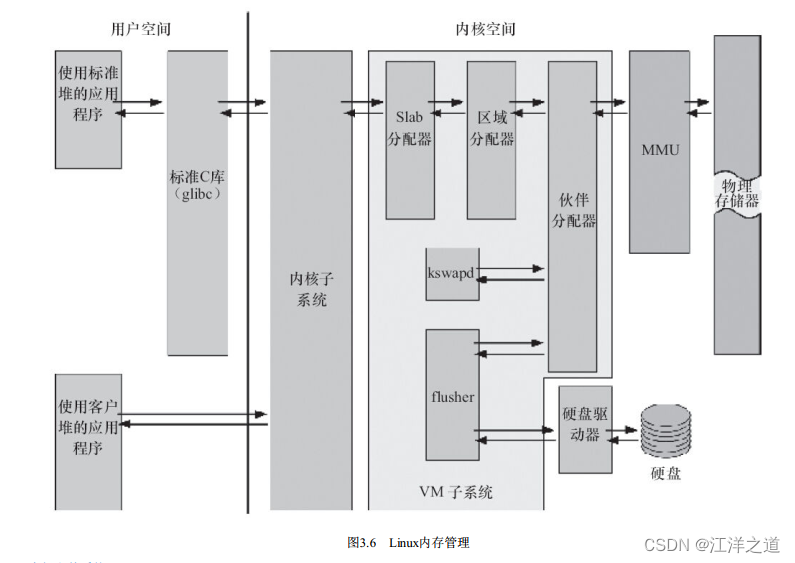
 如图3.6所示, Linux内核的内存管理总体比较庞大, 包含底层的Buddy算法, 它用于管理每个页的占用情况, 内核空间的slab以及用户空间的C库的二次管理。 另外, 内核也提供了页缓存的支持, 用内存来缓存磁盘, per-BDI flusher线程用于刷回脏的页缓存到磁盘。 Kswapd(交换进程) 则是Linux中用于页面回收(包括file-backed的页和匿名页) 的内核线程, 它采用最近最少使用(LRU) 算法进行内存回收。
如图3.6所示, Linux内核的内存管理总体比较庞大, 包含底层的Buddy算法, 它用于管理每个页的占用情况, 内核空间的slab以及用户空间的C库的二次管理。 另外, 内核也提供了页缓存的支持, 用内存来缓存磁盘, per-BDI flusher线程用于刷回脏的页缓存到磁盘。 Kswapd(交换进程) 则是Linux中用于页面回收(包括file-backed的页和匿名页) 的内核线程, 它采用最近最少使用(LRU) 算法进行内存回收。
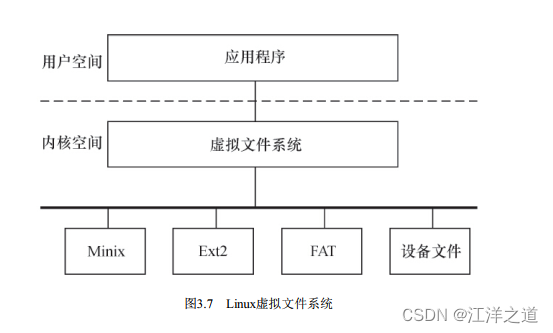
虚拟文件系统
网络接口
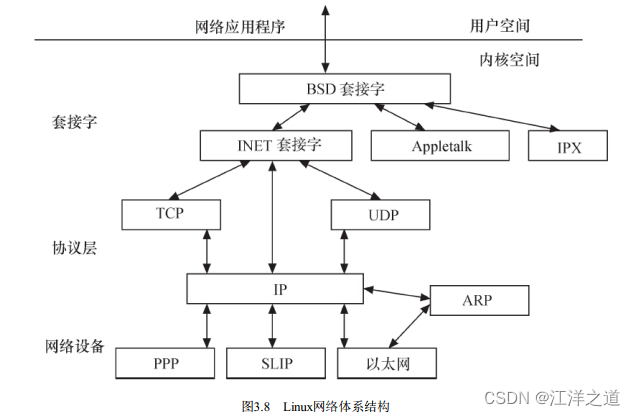 Linux内核支持的协议栈种类较多, 如Internet、 UNIX、 CAN、 NFC、 Bluetooth、 WiMAX、 IrDA等, 上层的应用程序统一使用套接字接口。
Linux内核支持的协议栈种类较多, 如Internet、 UNIX、 CAN、 NFC、 Bluetooth、 WiMAX、 IrDA等, 上层的应用程序统一使用套接字接口。
进程间通信
Linux支持进程间的多种通信机制, 包含信号量、 共享内存、 消息队列、 管道、 UNIX域套接字等, 这些机制可协助多个进程、 多资源的互斥访问、 进程间的同步和消息传递。 在实际的Linux应用中, 人们更多地趋向于使用UNIX域套接字, 而不是System V IPC中的消息队列等机制。 Android内核则新增了Binder进程间通信方式。
linux内核空间与用户空间
现代CPU内部往往实现了不同操作模式(级别) , 不同模式有不同功能, 高层程序往往不能访问低级功能, 而必须以某种方式切换到低级模式。
例如, ARM处理器分为7种工作模式。
·用户模式(usr) : 大多数应用程序运行在用户模式下, 当处理器运行在用户模式下时, 某些被保护的系统资源是不能访问的。
·快速中断模式(fiq) : 用于高速数据传输或通道处理。
·外部中断模式(irq) : 用于通用的中断处理。
·管理模式(svc) : 操作系统使用的保护模式。
·数据访问中止模式(abt) : 当数据或指令预取中止时进入该模式, 可用于虚拟存储及存储保护。
·系统模式(sys) : 运行具有特权的操作系统任务。
·未定义指令中止模式(und) : 当未定义的指令执行时进入该模式, 可用于支持硬件协处理器的软件仿真。
ARM Linux的系统调用实现原理是采用swi软中断从用户(usr) 模式陷入管理模式(svc) 。
又如, x86处理器包含4个不同的特权级, 称为Ring 0~Ring 3。 在Ring0下, 可以执行特权级指令, 对任何I/O设备都有访问权等, 而Ring3则被限制很多操作。
Linux系统可充分利用CPU的这一硬件特性, 但它只使用了两级。 在Linux系统中, 内核可进行任何操作, 而应用程序则被禁止对硬件的直接访问和对内存的未授权访问。 例如, 若使用x86处理器, 则用户代码运行在特权级3, 而系统内核代码则运行在特权级0。
内核空间和用户空间这两个名词用来区分程序执行的两种不同状态, 它们使用不同的地址空间。 Linux只能通过系统调用和硬件中断完成从用户空间到内核空间的控制转移。
linux内核的编译及加载
linux内核的编译
在配置Linux内核所使用的make config、 make menuconfig、 make xconfig和make gconfig这4种方式中, 最值得推荐的是make menuconfig, 它不依赖于QT或GTK+, 且非常直观。
Linux内核的配置系统由以下3个部分组成。·Makefile: 分布在Linux内核源代码中, 定义Linux内核的编译规则。
·配置文件( Kconfig) : 给用户提供配置选择的功能。
·配置工具: 包括配置命令解释器( 对配置脚本中使用的配置命令进行解释) 和配置用户界面( 提供字符界面和图形界面) 。 这些配置工具使用的都是脚本语言, 如用Tcl/TK、 Perl等。
使用make config、 make menuconfig等命令后, 会生成一个.config配置文件, 记录哪些部分被编译入内核、 哪些部分被编译为内核模块。
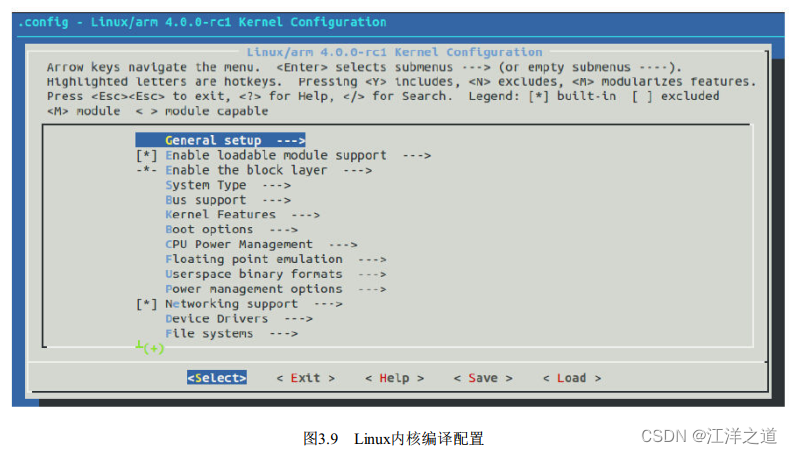
运行make menuconfig等时, 配置工具首先分析与体系结构对应的/arch/xxx/Kconfig文件( xxx即为传入的ARCH参数) , /arch/xxx/Kconfig文件中除本身包含一些与体系结构相关的配置项和配置菜单以外, 还通过source语句引入了一系列Kconfig文件, 而这些Kconfig又可能再次通过source引入下一层的Kconfig, 配置工具依据Kconfig包含的菜单和条目即可描绘出一个如图3.9所示的分层结构。
 编译内核实践总结:
编译内核实践总结:
1.下载内核
官网链接:
https://www.kernel.org/
HTTP
https://www.kernel.org/pub/
GIT
https://git.kernel.org/
官网下载经常速度太慢,无法下载,提供另一个链接:
http://ftp.sjtu.edu.cn/sites/ftp.kernel.org/pub/linux/kernel/
下载了5.18.12内核
2.运行make ARCH=arm menuconfig
什么都不用改,save,然后,exit
3.make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- zImage 编译内核
报错, 原因是交叉编译链工具版本太低;
sudo apt-get install gcc-arm-linux-gnueabihf
sudo apt-get install g+±arm-linux-gnueabihf
安装最新交叉编译工具;
编译通过
Kconfig和Makefile
在Linux内核中增加程序需要完成以下3项工作。
·将编写的源代码复制到Linux内核源代码的相应目录中。
·在目录的Kconfig文件中增加关于新源代码对应项目的编译配置选项。
·在目录的Makefile文件中增加对新源代码的编译条目。
实例引导:TTY_PRINTK字符设备
一般而言, 驱动开发者会在内核源代码的drivers目录内的相应子目录中增加新设备驱动的源代码或者在arch/arm/mach-xxx下新增加板级支持的代码, 同时增加或修改Kconfig配置脚本和Makefile脚本
Makefile
这里主要对内核源代码各级子目录中的kbuild(内核的编译系统) Makefile进行简单介绍, 这部分是内核模块或
设备驱动开发者最常接触到的。
Makefile的语法包括如下几个方面。
(1) 目标定义目标定义就是用来定义哪些内容要作为模块编译, 哪些要编译并链接进内核。
例如:
obj-y += foo.o
表示要由foo.c或者foo.s文件编译得到foo.o并链接进内核(无条件编译, 所以不需要Kconfig配置选项) , 而obj-m则表示该文件要作为模块编译。 obj-n形式的目标不会被编译。
更常见的做法是根据make menuconfig后生成的config文件的CONFIG_变量来决定文件的编译方式, 如:
obj-$(CONfiG_ISDN) += isdn.o
obj-$(CONfiG_ISDN_PPP_BSDCOMP) += isdn_bsdcomp.o
除了具有obj-形式的目标以外, 还有lib-y library库、 hostprogs-y主机程序等目标, 但是这两类基本都应用在特定的目录和场合下。
多文件模块的定义。
最简单的Makefile仅需一行代码就够了。 如果一个模块由多个文件组成, 会稍微复杂一些, 这时候应采用模块名
加-y或-objs后缀的形式来定义模块的组成文件, 如下:
obj-$(CONfiG_EXT2_FS) += ext2.o
ext2-y := balloc.o dir.o file.o fsync.o ialloc.o inode.o
ioctl.o namei.o super.o symlink.o
ext2-$(CONfiG_EXT2_FS_XATTR) += xattr.o xattr_user.o xattr_trusted.o
ext2-$(CONfiG_EXT2_FS_POSIX_ACL) += acl.o
ext2-$(CONfiG_EXT2_FS_SECURITY) += xattr_security.o
ext2-$(CONfiG_EXT2_FS_XIP) += xip.o
模块的名字为ext2, 由balloc.o、 dir.o、 file.o等多个目标文件最终链接生成ext2.o直至ext2.ko文件, 并且是否包括xattr.o、 acl.o等则取决于内核配置文件的配置情况, 例如, 如果CONFIG_EXT2_FS_POSIX_ACL被选择, 则编译acl.c得到acl.o并最终链接进ext2。
(3) 目录层次的迭代
如下例:
obj-$(CONfiG_EXT2_FS) += ext2/
当CONFIG_EXT2_FS的值为y或m时, kbuild将会把ext2目录列入向下迭代的目标中。
Kconfig
内核配置脚本文件的语法也比较简单, 主要包括如下几个方面。
(1) 配置选项
大多数内核配置选项都对应Kconfig中的一个配置选项(config) :
config MODVERSIONS
bool "Module versioning support"
help
Usually, you have to use modules compiled with your kernel.
Saying Y here makes it ...
“config”关键字定义新的配置选项, 之后的几行代码定义了该配置选项的属性。 配置选项的属性包括类型、 数据范围、 输入提示、 依赖关系、 选择关系及帮助信息、 默认值等。
·每个配置选项都必须指定类型, 类型包括bool、 tristate、 string、 hex和int, 其中tristate和string是两种基本类型,其他类型都基于这两种基本类型。
类型定义后可以紧跟输入提示, 下面两段脚本是等价的:
bool “ Networking support ”
和
bool
prompt "Networking support"
·输入提示的一般格式为:
prompt <prompt> [if <expr>]
其中, 可选的if用来表示该提示的依赖关系。
·默认值的格式为:
default <expr> [if <expr>]
如果用户不设置对应的选项, 配置选项的值就是默认值。
·依赖关系的格式为:
depends on (或者 requires ) <expr>
如果定义了多重依赖关系, 它们之间用“&&”间隔。 依赖关系也可以应用到该菜单中所有的其他选项(同样接受if表达式) 内, 下面两段脚本是等价的:
bool "foo" if BARdefault y if BAR
和
depends on BAR
bool "foo"
default y
·选择关系(也称为反向依赖关系) 的格式为:
select <symbol> [if <expr>]
A如果选择了B, 则在A被选中的情况下, B自动被选中。
·数据范围的格式为:
range <symbol> <symbol> [if <expr>]
·Kconfig中的expr(表达式) 定义为:
<expr> ::= <symbol>
<symbol> '=' <symbol>
<symbol> '!=' <symbol>
'(' <expr> ')'
'!' <expr>
<expr> '&&' <expr>
<expr> '||' <expr>
也就是说, expr是由symbol、 两个symbol相等、 两个symbol不等以及expr的赋值、 非、 与或运算构成。
而symbol分为两类, 一类是由菜单入口配置选项定义的非常数symbol, 另一类是作为expr组成部分的常数symbol。 比如, SHDMA_R8A73A4是一个布尔配置选项, 表达式“ARCH_R8A73A4&&SH_DMAE! =n”暗示只有当ARCH_R8A73A4被选中且SH_DMAE没有被选中的时候, 才可能出现这个SHDMA_R8A73A4。
config SHDMA_R8A73A4
def_bool y
depends on ARCH_R8A73A4 && SH_DMAE != n
·为int和hex类型的选项设置可以接受的输入值范围, 用户只能输入大于等于第一个symbol, 且小于等于第二个symbol的值。
·帮助信息的格式为:
help (或 ---help--- )
开始
…
结束
帮助信息完全靠文本缩进识别结束。 “—help—”和“help”在作用上没有区别, 设计“—help—”的初衷在于将文件中的配置逻辑与给开发人员的提示分开。
(2) 菜单结构
配置选项在菜单树结构中的位置可由两种方法决定。 第一种方式为:
menu "Network device support"
depends on NET
config NETDEVICES
…
endmenu
所有处于“menu”和“endmenu”之间的配置选项都会成为“Network device support”的子菜单, 而且, 所有子菜单(config) 选项都会继承父菜单(menu) 的依赖关系, 比如, “Network device support”对“NET”的依赖会被加到配置选项NETDEVICES的依赖列表中。
注意: menu后面跟的“Network device support”项仅仅是1个菜单, 没有对应真实的配置选项, 也不具备3种不同的状态。 这是它和config的区别。
另一种方式是通过分析依赖关系生成菜单结构。 如果菜单项在一定程度上依赖于前面的选项, 它就能成为该选项的子菜单。 如果父选项为“n”, 子选项不可见; 如果父选项可见, 子选项才可见。 例如:
config MODULES
bool "Enable loadable module support"
config MODVERSIONS
bool "Set version information on all module symbols"
depends on MODULES
comment "module support disabled"
depends on !MODULES
MODVERSIONS直接依赖MODULES, 只有MODULES不为“n”时, 该选项才可见。
除此之外, Kconfig中还可能使用“choices…endchoice”、 “comment”、 “if…endif”这样的语法结构。 其中“choices…endchoice”的结构为:
choice
<choice options>
<choice block>
endchoice"
它定义一个选择群, 其接受的选项(choice options) 可以是前面描述的任何属性, 例如, LDD6410的VGA输出分辨率可以是1024×768或者800×600, 在drivers/video/samsung/Kconfig中就定义了如下choice:
choice
depends on FB_S3C_VGA
prompt "Select VGA Resolution for S3C Framebuffer"
default FB_S3C_VGA_1024_768
config FB_S3C_VGA_1024_768
bool "1024*768@60Hz"
---help---
TBA
config FB_S3C_VGA_640_480
bool "640*480@60Hz"
---help---
TBA
endchoice
上述例子中, prompt配合choice起到提示作用。
用Kconfig配置脚本和Makefile脚本编写的更详细信息, 可以分别参见内核文档Documentation目录内的kbuild子目录下的Kconfig-language.txt和Makefiles.txt文件。
应用实例:在内核中新增驱动代码目录和子目录
在内核中增加目录和子目录时, 我们需为相应的新增目录创建Makefile和Kconfig文件, 而新增目录的父目录中的Kconfig和Makefile也需修改:
source "drivers/test/Kconfig"
直接修改Kconfig文件之后,运行make ARCH=arm menuconfig,就可以看到效果。
Linux内核的引导
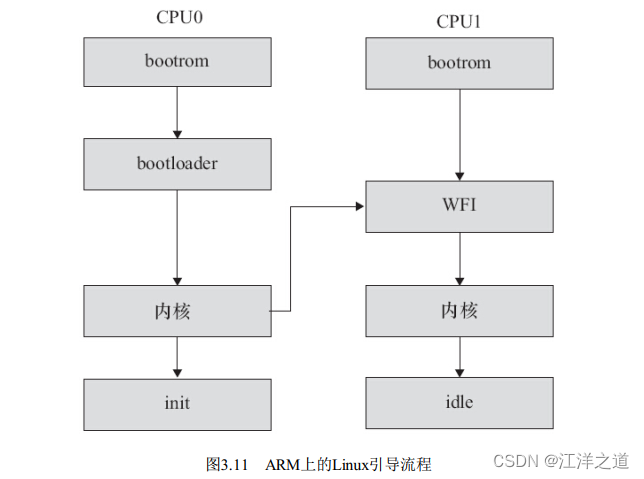
引导Linux系统的过程包括很多阶段, 这里将以引导ARM Linux为例来进行讲解(见图3.11) 。 一般的SoC内嵌入了bootrom, 上电时bootrom运行。 对于CPU0而言, bootrom会去引导bootloader, 而其他CPU则判断自己是不是CPU0, 进入WFI的状态等待CPU0来唤醒它。 CPU0引导bootloader, bootloader引导Linux内核, 在内核启动阶段, CPU0会发中断唤醒CPU1, 之后CPU0和CPU1都投入运行。 CPU0导致用户空间的init程序被调用, init程序再派生其他进程, 派生出来的进程再派生其他进程。 CPU0和CPU1共担这些负载, 进行负载均衡。
GNU C与ANSI C
Linux上可用的C编译器是GNU C编译器, 它建立在自由软件基金会的编程许可证的基础上, 因此可以自由发布。 GNU C对标准C进行一系列扩展, 以增强标准C的功能。
零长度和变量长度数组
GNU C允许使用零长度数组, 在定义变长对象的头结构时, 这个特性非常有用。 例如:
struct var_data {
int len;
char data[0];
};
char data[0]仅仅意味着程序中通过var_data结构体实例的data[index]成员可以访问len之后的第index个地址, 它并没有为data[]数组分配内存, 因此sizeof(struct var_data) =sizeof(int) 。
假设struct var_data的数据域就保存在struct var_data紧接着的内存区域中, 则通过如下代码可以遍历这些数据:
struct var_data s;
...
for (i = 0; i < s.len; i++)
printf("%02x", s.data[i]);
GNU C中也可以使用1个变量定义数组, 例如如下代码中定义的“double x[n]”:
int main (int argc, char *argv[])
{
int i, n = argc;
double x[n];
for (i = 0; i < n; i++)
x[i] = i;
return 0;
}
case范围
GNU C支持case x…y这样的语法, 区间[x, y]中的数都会满足这个case的条件, 请看下面的代码:
switch (ch) {
case '0'... '9': c -= '0';
break;
case 'a'... 'f': c -= 'a' - 10;
break;
case 'A'... 'F': c -= 'A' - 10;
break;
}
代码中的case’0’…’9’等价于标准C中的:
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
语句表达式
GNU C把包含在括号中的复合语句看成是一个表达式, 称为语句表达式, 它可以出现在任何允许表达式的地方。 我们可以在语句表达式中使用原本只能在复合语句中使用的循环、 局部变量等, 例如:
#define min_t(type,x,y)
( { type _ _x =(x);type _ _y = (y); _ _x<_ _y _ _x: _ _y; })
int ia, ib, mini;
float fa, fb, minf;
mini = min_t(int, ia, ib);
minf = min_t(float, fa, fb);
因为重新定义了__xx和__y这两个局部变量, 所以用上述方式定义的宏将不会有副作用。 在标准C中, 对应的如下宏则会产生副作用:
#define min(x,y) ((x) < (y) (x) : (y))
代码min(++ia, ++ib) 会展开为((++ia) <(++ib) (++ia) : (++ib) ) , 传入宏的“参数”增加两次。
typeof关键字
typeof(x) 语句可以获得x的类型, 因此, 可以借助typeof重新定义min这个宏:
#define min(x,y) ({
const typeof(x) _x = (x);
const typeof(y) _y = (y);
(void) (&_x == &_y);
_x < _y _x : _y; })
我们不需要像min_t(type, x, y) 那个宏那样把type传入, 因为通过typeof(x) 、 typeof(y) 可以获得type。 代码行(void) (&_x==&_y) 的作用是检查_x和_y的类型是否一致。
可变参数宏
标准C就支持可变参数函数, 意味着函数的参数是不固定的, 例如printf() 函数的原型为:
int printf( const char *format [, argument]... );
而在GNU C中, 宏也可以接受可变数目的参数, 例如:
#define pr_debug(fmt,arg...)
printk(fmt,##arg)
这里arg表示其余的参数, 可以有零个或多个参数, 这些参数以及参数之间的逗号构成arg的值, 在宏扩展时替换arg, 如下列代码:
pr_debug("%s:%d",filename,line)
会被扩展为:
printk("%s:%d", filename, line)
使用“##”是为了处理arg不代表任何参数的情况, 这时候, 前面的逗号就变得多余了。 使用“##”之后, GNU C预处理器会丢弃前面的逗号, 这样, 下列代码:
pr_debug("success!n")
会被正确地扩展为:
printk("success!n")
而不是:
printk("success!n",)
这正是我们希望看到的。
标号元素
标准C要求数组或结构体的初始化值必须以固定的顺序出现, 在GNU C中, 通过指定索引或结构体成员名, 允许初始化值以任意顺序出现。
指定数组索引的方法是在初始化值前添加“[INDEX]=”, 当然也可以用“[FIRST…LAST]=”的形式指定一个范围。
例如, 下面的代码定义了一个数组, 并把其中的所有元素赋值为0:
unsigned char data[MAX] = { [0 ... MAX-1] = 0 };
下面的代码借助结构体成员名初始化结构体:
struct file_operations ext2_file_operations = {
llseek: generic_file_llseek,
read: generic_file_read,
write: generic_file_write,
ioctl: ext2_ioctl,
mmap: generic_file_mmap,
open: generic_file_open,
release: ext2_release_file,
fsync: ext2_sync_file,
};
但是, Linux 2.6推荐类似的代码应该尽量采用标准C的方式:
struct file_operations ext2_file_operations = {
.llseek = generic_file_llseek,
.read = generic_file_read,
.write = generic_file_write,
.aio_read = generic_file_aio_read,
.aio_write = generic_file_aio_write,
.ioct = ext2_ioctl,
.mmap = generic_file_mmap,
.open = generic_file_open,
.release = ext2_release_file,
.fsync = ext2_sync_file,
.readv = generic_file_read
}
当前函数名
GNU C预定义了两个标识符保存当前函数的名字, __FUNCTION__保存函数在源码中的名字__PRETTY_FUNCTION__保存带语言特色的名字。 在C函数中, 这两个名字是相同的。
void example()
{
printf("This is function:%s", __FUNCTION__);
}
代码中的__FUNCTION__意味着字符串“example”。 C99已经支持__func__宏, 因此建议在Linux编程中不再使用
__FUNCTION__, 而转而使用__func__:
void example(void)
{
printf("This is function:%s", __func__);
}
特殊属性声明
GNU C允许声明函数、 变量和类型的特殊属性, 以便手动优化代码和定制代码检查的方法。 要指定一个声明的属性, 只需要在声明后添加__attribute__((ATTRIBUTE) ) 。 其中ATTRIBUTE为属性说明, 如果存在多个属性, 则以逗号分隔。 GNU C支持noreturn、 format、 section、 aligned、 packed等十多个属性。
noreturn属性作用于函数, 表示该函数从不返回。 这会让编译器优化代码, 并消除不必要的警告信息。 例如:
# define ATTRIB_NORET __attribute__((noreturn)) ....
asmlinkage NORET_TYPE void do_exit(long error_code) ATTRIB_NORET;
format属性也用于函数, 表示该函数使用printf、 scanf或strftime风格的参数, 指定format属性可以让编译器根据格式串检查参数类型。 例如:
asmlinkage int printk(const char * fmt, ...) __attribute__ ((format (printf, 1, 2)));
上述代码中的第1个参数是格式串, 从第2个参数开始都会根据printf() 函数的格式串规则检查参数。
unused属性作用于函数和变量, 表示该函数或变量可能不会用到, 这个属性可以避免编译器产生警告信息。
aligned属性用于变量、 结构体或联合体, 指定变量、 结构体或联合体的对齐方式, 以字节为单位, 例如:
struct example_struct {
char a;
int b;
long c;
} __attribute__((aligned(4)));
表示该结构类型的变量以4字节对齐。
packed属性作用于变量和类型, 用于变量或结构体成员时表示使用最小可能的对齐, 用于枚举、 结构体或联合体
类型时表示该类型使用最小的内存。 例如:
struct example_struct {
char a;
int b;
long c __attribute__((packed));
};
编译器对结构体成员及变量对齐的目的是为了更快地访问结构体成员及变量占据的内存。 例如, 对于一个32位的整型变量, 若以4字节方式存放(即低两位地址为00) , 则CPU在一个总线周期内就可以读取32位; 否则, CPU需要两个总线周期才能读取32位。
内建函数
GNU C提供了大量内建函数, 其中大部分是标准C库函数的GNU C编译器内建版本, 例如memcpy() 等, 它们与对应的标准C库函数功能相同。
不属于库函数的其他内建函数的命名通常以__builtin开始, 如下所示。
- 内建函数__builtin_return_address(LEVEL) 返回当前函数或其调用者的返回地址, 参数LEVEL指定调用栈的级数, 如0表示当前函数的返回地址, 1表示当前函数的调用者的返回地址。
- 内建函数__builtin_constant_p(EXP) 用于判断一个值是否为编译时常数, 如果参数EXP的值是常数, 函数返回1, 否则返回0。
例如, 下面的代码可检测第1个参数是否为编译时常数以确定采用参数版本还是非参数版本:
#define test_bit(nr,addr)
(__builtin_constant_p(nr)
constant_test_bit((nr),(addr)) :
variable_test_bit((nr),(addr)))
- 内建函数__builtin_expect(EXP, C) 用于为编译器提供分支预测信息, 其返回值是整数表达式EXP的值, C的值必须是编译时常数。
Linux内核编程时常用的likely() 和unlikely() 底层调用的likely_notrace() 、 unlikely_notrace() 就是基于__builtin_expect(EXP, C) 实现的。
#define likely_notrace(x) __builtin_expect(!!(x), 1)
#define unlikely_notrace(x) __builtin_expect(!!(x), 0)
若代码中出现分支, 则即可能中断流水线, 我们可以通过likely() 和unlikely() 暗示分支容易成立还是不容易成立, 例如:
if (likely(!IN_DEV_ROUTE_LOCALNET(in_dev)))if (ipv4_is_loopback(saddr))
goto e_inval;
在使用gcc编译C程序的时候, 如果使用“-ansi–pedantic”编译选项, 则会告诉编译器不使用GNU扩展语法。 例如对
于如下C程序test.c:
struct var_data {
int len;
char data[0];
};
struct var_data a;
直接编译可以通过:
gcc -c test.c
如果使用“-ansi–pedantic”编译选项, 编译会报警:
gcc -ansi -pedantic -c test.c
test.c:3: warning: ISO C forbids zero-size array ‘data’
linux内核模块
模块具有这样的特点:
- 模块本身不被编译入内核映像, 从而控制了内核的大小。
- 模块一旦被加载, 它就和内核中的其他部分完全一样。
一个最简单的Linux内核模块
1 /*
2 * a simple kernel module: hello
3 *
4 * Copyright (C) 2014 Barry Song (baohua@kernel.org)
5 *
6 * Licensed under GPLv2 or later.
7 */
8
9 #include <linux/init.h>
10 #include <linux/module.h>
11
12 static int __init hello_init(void)
13 {
14 printk(KERN_INFO "Hello World entern");
15 return 0;
16 }
17 module_init(hello_init);
18
19 static void __exit hello_exit(void)
20 {
21 printk(KERN_INFO "Hello World exitn ");
22 }
23 module_exit(hello_exit);
24
25 MODULE_AUTHOR("Barry Song <21cnbao@gmail.com>");
26 MODULE_LICENSE("GPL v2");
27 MODULE_DESCRIPTION("A simple Hello World Module");
28 MODULE_ALIAS("a simplest module");
这个最简单的内核模块只包含内核模块加载函数、 卸载函数和对GPL v2许可权限的声明以及一些描述信息。 编译它会产生hello.ko目标文件, 通过“insmod./hello.ko”命令可以加载它, 通过“rmmod hello”命令可以卸载它, 加载时输出“Hello World enter”, 卸载时输出“Hello World exit”。
实测,加载之后,使用dmesg命令可以看到“Hello World enter”,卸载时,看不到“Hello World exit”,需要在下次加载之后,才能看到
在Linux中, 使用lsmod命令可以获得系统中已加载的所有模块以及模块间的依赖关系,lsmod命令实际上是读取并分析“/proc/modules”文件
内核中已加载模块的信息也存在于/sys/module目录下, 加载hello.ko后, 内核中将包含/sys/module/hello目录
modprobe命令比insmod命令要强大, 它在加载某模块时, 会同时加载该模块所依赖的其他模块。 使用modprobe命令加载的模块若以“modprobe-r filename”的方式卸载, 将同时卸载其依赖的模块。 模块之间的依赖关系存放在根文件系统的/lib/modules/<kernel-version>/modules.dep文件中, 实际上是在整体编译内核的时候由depmod工具生成的。
用modprobe 加载模块时,提示模块找不到的问题,如在/home目录下有个编译好的模块:helloworld.ko,
当我们运行 sudo modprobe /home/helloworld.ko时,会提示“FATAL: Module helloworld not found.”
modprobe是在/lib/module/uname -r下寻找加载的模块的,并且modprobe需要一个最新的modules.dep文件,
这个modules.dep文件内容是些各个模块之间的依赖等信息,此文件是由depmod命令来更新的。
所以我们需要做的事情:
1.将编译好的模块放入/lib/module/uname -r下,
2. 用depmod更新modules.dep文件
3. modprobe helloworld.ko
使用modinfo<模块名>命令可以获得模块的信息, 包括模块作者、 模块的说明、 模块所支持的参数以及vermagic
neowayxbw@ubuntu:~/linux/linux-5.18.12/drivers/xbw_module$ modinfo xbw_module.ko
filename: /home/neowayxbw/linux/linux-5.18.12/drivers/xbw_module/xbw_module.ko
author: Barry Song <21cnbao@gmail.com>
license: GPL v2
description: A simple Hello World Module
alias: a simplest module
srcversion: 081230411494509792BD4A3
depends:
retpoline: Y
name: xbw_module
vermagic: 5.4.0-122-generic SMP mod_unload modversions
Linux内核模块程序结构
一个Linux内核模块主要由如下几个部分组成。
(1) 模块加载函数
当通过insmod或modprobe命令加载内核模块时, 模块的加载函数会自动被内核执行, 完成本模块的相关初始化工作。
(2) 模块卸载函数
当通过rmmod命令卸载某模块时, 模块的卸载函数会自动被内核执行, 完成与模块卸载函数相反的功能。
(3) 模块许可证声明
许可证(LICENSE) 声明描述内核模块的许可权限, 如果不声明LICENSE, 模块被加载时, 将收到内核被污染(Kernel Tainted) 的警告。
在Linux内核模块领域, 可接受的LICENSE包括“GPL”、 “GPL v2”、 “GPL and additional rights”、 “Dual BSD/GPL”、 “Dual MPL/GPL”和“Proprietary”(关于模块是否可以采用非GPL许可权, 如“Proprietary”, 这个在学术界和法律界都有争议) 。
大多数情况下, 内核模块应遵循GPL兼容许可权。 Linux内核模块最常见的是以MODULE_LICENSE(“GPLv2”) 语句声明模块采用GPL v2。
(4) 模块参数(可选)
模块参数是模块被加载的时候可以传递给它的值, 它本身对应模块内部的全局变量。
(5) 模块导出符号(可选)
内核模块可以导出的符号(symbol, 对应于函数或变量) , 若导出, 其他模块则可以使用本模块中的变量或函数。
(6) 模块作者等信息声明(可选)
模块加载函数
Linux内核模块加载函数一般以__init标识声明, 典型的模块加载函数的形式如:
1 static int __init initialization_function(void)
2 {
3 /* 初始化代码 */
4 }
5 module_init(initialization_function);
模块加载函数以“module_init(函数名) ”的形式被指定。 它返回整型值, 若初始化成功, 应返回0。 而在初始化失败时, 应该返回错误编码。 在Linux内核里, 错误编码是一个接近于0的负值, 在<linux/errno.h>中定义, 包含-ENODEV、 -ENOMEM之类的符号值。
在Linux内核中, 可以使用request_module(const char*fmt, …) 函数加载内核模块, 驱动开发人员可以通过调用下列代码:
request_module(module_name);
灵活地加载其他内核模块。
在Linux中, 所有标识为__init的函数如果直接编译进入内核, 成为内核镜像的一部分, 在连接的时候都会放在.init.text这个区段内。
#define __init __attribute__ ((__section__ (".init.text")))
所有的__init函数在区段.initcall.init中还保存了一份函数指针, 在初始化时内核会通过这些函数指针调用这些__init函数, 并在初始化完成后, 释放init区段(包括.init.text、 .initcall.init等) 的内存。
除了函数以外, 数据也可以被定义为__initdata, 对于只是初始化阶段需要的数据, 内核在初始化完后, 也可以释
放它们占用的内存。 例如, 下面的代码将hello_data定义为__initdata:
static int hello_data __initdata = 1;
static int __init hello_init(void)
{
printk(KERN_INFO "Hello, world %dn", hello_data);
return 0;
}
module_init(hello_init);
static void __exit hello_exit(void)
{
printk(KERN_INFO "Goodbye, worldn");
}
module_exit(hello_exit);
模块卸载函数
Linux内核模块加载函数一般以__exit标识声明, 典型的模块卸载函数的形式如代码清单4.3所示。
代码清单4.3 内核模块卸载函数
1 static void _ _exit cleanup_function(void)
2 {
3 /* 释放代码 */
4 }
5 module_exit(cleanup_function);
模块卸载函数在模块卸载的时候执行, 而不返回任何值, 且必须以“module_exit(函数名) ”的形式来指定。 通常来说, 模块卸载函数要完成与模块加载函数相反的功能。
我们用__exit来修饰模块卸载函数, 可以告诉内核如果相关的模块被直接编译进内核(即built-in) , 则cleanup_function() 函数会被省略, 直接不链进最后的镜像。 既然模块被内置了, 就不可能卸载它了, 卸载函数也就没有存在的必要了。 除了函数以外, 只是退出阶段采用的数据也可以用__exitdata来形容。
模块参数
我们可以用“module_param(参数名, 参数类型, 参数读/写权限) ”为模块定义一个参数, 例如下列代码定义了1个整型参数和1个字符指针参数:
static char *book_name = "dissecting Linux Device Driver";
module_param(book_name, charp, S_IRUGO);
static int book_num = 4000;
module_param(book_num, int, S_IRUGO);
在装载内核模块时, 用户可以向模块传递参数, 形式为“insmode(或modprobe) 模块名参数名=参数值”, 如果不传递, 参数将使用模块内定义的缺省值。 如果模块被内置, 就无法insmod了, 但是bootloader可以通过在bootargs
里设置“模块名.参数名=值”的形式给该内置的模块传递参数。
参数类型可以是byte、 short、 ushort、 int、 uint、 long、 ulong、 charp(字符指针) 、 bool或invbool(布尔的反) ,在模块被编译时会将module_param中声明的类型与变量定义的类型进行比较, 判断是否一致。
除此之外, 模块也可以拥有参数数组, 形式为“module_param_array(数组名, 数组类型, 数组长, 参数读/写权限) ”。
模块被加载后, 在/sys/module/目录下将出现以此模块名命名的目录。 当“参数读/写权限”为0时, 表示此参数不存在sysfs文件系统下对应的文件节点, 如果此模块存在“参数读/写权限”不为0的命令行参数, 在此模块的目录下还将出现parameters目录, 其中包含一系列以参数名命名的文件节点, 这些文件的权限值就是传入module_param() 的“参数读/写权限”, 而文件的内容为参数的值。
导出符号
Linux的“/proc/kallsyms”文件对应着内核符号表, 它记录了符号以及符号所在的内存地址。
模块可以使用如下宏导出符号到内核符号表中:
EXPORT_SYMBOL( 符号名 );
EXPORT_SYMBOL_GPL( 符号名 );
导出的符号可以被其他模块使用, 只需使用前声明一下即可。 EXPORT_SYMBOL_GPL() 只适用于包含GPL许可权的模块。
模块声明与描述
在Linux内核模块中, 我们可以用MODULE_AUTHOR、 MODULE_DESCRIPTION、 MODULE_VERSION、MODULE_DEVICE_TABLE、 MODULE_ALIAS分别声明模块的作者、 描述、 版本、 设备表和别名,对于USB、 PCI等设备驱动, 通常会创建一个MODULE_DEVICE_TABLE, 以表明该驱动模块所支持的设备。
模块的使用计数
Linux 2.6以后的内核提供了模块计数管理接口try_module_get(&module) 和module_put(&module) , 从而取代Linux 2.4内核中的模块使用计数管理宏。 模块的使用计数一般不必由模块自身管理, 而且模块计数管理还考虑了SMP与PREEMPT机制的影响。
int try_module_get(struct module *module);
该函数用于增加模块使用计数; 若返回为0, 表示调用失败, 希望使用的模块没有被加载或正在被卸载中。
void module_put(struct module *module);
该函数用于减少模块使用计数。
Linux 2.6以后的内核为不同类型的设备定义了struct module*owner域, 用来指向管理此设备的模块。 当开始使用某个设备时,内核使用try_module_get(dev->owner) 去增加管理此设备的owner模块的使用计数; 当不再使用此设备时, 内核使用module_put(dev->owner) 减少对管理此设备的管理模块的使用计数。 这样, 当设备在使用时, 管理此设备的模块将不能被卸载。 只有当设备不再被使用时, 模块才允许被卸载。
在Linux 2.6以后的内核下, 对于设备驱动而言, 很少需要亲自调用try_module_get() 与module_put() , 因为此时开发人员所写的驱动通常为支持某具体设备的管理模块, 对此设备owner模块的计数管理由内核里更底层的代
码(如总线驱动或是此类设备共用的核心模块) 来实现, 从而简化了设备驱动开发。
模块的编译
我们可以为holle模块编写一个简单的Makefile:
KVERS = $(shell uname -r)
# Kernel modules
obj-m += hello.o
# Specify flags for the module compilation.
#EXTRA_CFLAGS=-g -O0
build: kernel_modules
kernel_modules:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) modules
clean:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean
该Makefile文件应该与源代码hello.c位于同一目录, 开启其中的EXTRA_CFLAGS=-g -O0, 可以得到包含调试信息的hello.ko模块。 运行make命令得到的模块可直接在PC上运行。如果一个模块包括多个.c文件(如file1.c、 file2.c) , 则应该以如下方式编写Makefile:
obj-m := modulename.o
modulename-objs := file1.o file2.o
linux文件操作
Linux用5个数字来表示文件的各种权限: 第一位表示设置用户ID; 第二位表示设置组ID; 第三位表示用户自己的权限位; 第四位表示组的权限; 最后一位表示其他人的权限。 每个数字可以取1(执行权限) 、 2(写权限) 、 4(读权限) 、 0(无) 或者是这些值的和。 例如, 要创建一个用户可读、 可写、 可执行, 但是组没有权限, 其他人可以读、 可以执行的文件, 并设置用户ID位, 那么应该使用的模式是1(设置用户ID) 、 0(不设置组ID) 、 7(1+2+4, 读、
写、 执行) 、 0(没有权限) 、 5(1+4, 读、 执行) 即10705:
open("test", O_CREAT, 10 705);
上述语句等价于:
open("test", O_CREAT, S_IRWXU | S_IROTH | S_IXOTH | S_ISUID );
linux文件系统
Linux文件系统目录结构
进入Linux根目录(即“/”, Linux文件系统的入口, 也是处于最高一级的目录) , 运行“ls–l”命令, 看到Linux包含以下目录。
1./bin
包含基本命令, 如ls、 cp、 mkdir等, 这个目录中的文件都是可执行的。
2./sbin
包含系统命令, 如modprobe、 hwclock、 ifconfig等, 大多是涉及系统管理的命令, 这个目录中的文件都是可执行的。
3./dev
设备文件存储目录, 应用程序通过对这些文件的读写和控制以访问实际的设备。
4./etc
系统配置文件的所在地, 一些服务器的配置文件也在这里, 如用户账号及密码配置文件。 busybox的启动脚本也存放在该目录。
5./lib
系统库文件存放目录等。
6./mnt
/mnt这个目录一般是用于存放挂载储存设备的挂载目录, 比如含有cdrom等目录。 可以参看/etc/fstab的定义。 有时我们可以让系统开机自动挂载文件系统, 并把挂载点放在这里。
7./opt
opt是“可选”的意思, 有些软件包会被安装在这里。
8./proc
操作系统运行时, 进程及内核信息(比如CPU、 硬盘分区、 内存信息等) 存放在这里。 /proc目录为伪文件系统proc的挂载目录, proc并不是真正的文件系统, 它存在于内存之中。
9./tmp
用户运行程序的时候, 有时会产生临时文件, /tmp用来存放临时文件。
10./usr
这个是系统存放程序的目录, 比如用户命令、 用户库等。
11./var
var表示的是变化的意思, 这个目录的内容经常变动, 如/var的/var/log目录被用来存放系统日志。
12./sys
Linux 2.6以后的内核所支持的sysfs文件系统被映射在此目录上。 Linux设备驱动模型中的总线、 驱动和设备都可以在sysfs文件系统中找到对应的节点。 当内核检测到在系统中出现了新设备后, 内核会在sysfs文件系统中为该新设备生成一项新的记录。
linux文件系统与设备驱动
在设备驱动程序的设计中, 一般而言, 会关心file和inode这两个结构体。
1.file结构体
file结构体代表一个打开的文件, 系统中每个打开的文件在内核空间都有一个关联的struct file。 它由内核在打开文件时创建, 并传递给在文件上进行操作的任何函数。 在文件的所有实例都关闭后, 内核释放这个数据结构。 在内核和驱动源代码中, struct file的指针通常被命名为file或filp(即file pointer) 。
2.inode结构体
VFS inode包含文件访问权限、 属主、 组、 大小、 生成时间、 访问时间、 最后修改时间等信息。 它是Linux管理文件系统的最基本单位, 也是文件系统连接任何子目录、 文件的桥梁。
udev用户空间设备管理
Linux设计中强调的一个基本观点是机制和策略的分离。 机制是做某样事情的固定步骤、 方法, 而策略就是每一个步骤所采取的不同方式。 机制是相对固定的, 而每个步骤采用的策略是不固定的。 机制是稳定的, 而策略则是灵活的, 因此, 在Linux内核中, 不应该实现策略。
udev完全在用户态工作, 利用设备加入或移除时内核所发送的热插拔事件(Hotplug Event) 来工作。 在热插拔时, 设备的详细信息会由内核通过netlink套接字发送出来, 发出的事情叫uevent。 udev的设备命名策略、 权限控制和事件处理都是在用户态下完成的, 它利用从内核收到的信息来进行创建设备文件节点等工作。
冷插拔的设备在开机时就存在, 在udev启动前已经被插入了。 对于冷插拔的设备, Linux内核提供了sysfs下面一个uevent节点, 可以往该节点写一个“add”, 导致内核重新发送netlink,之后udev就可以收到冷插拔的netlink消息了。
ysfs文件系统与Linux设备模型
Linux 2.6以后的内核引入了sysfs文件系统, sysfs被看成是与proc、 devfs和devpty同类别的文件系统, 该文件系统是一个虚拟的文件系统, 它可以产生一个包括所有系统硬件的层级视图, 与提供进程和状态信息的proc文件系统十分类似。
sysfs把连接在系统上的设备和总线组织成为一个分级的文件, 它们可以由用户空间存取, 向用户空间导出内核数据结构以及它们的属性。
sysfs的一个目的就是展示设备驱动模型中各组件的层次关系, 其顶级目录包括block、 bus、 dev、 devices、 class、 fs、 kernel、 power和firmware
等。
block目录包含所有的块设备; devices目录包含系统所有的设备, 并根据设备挂接的总线类型组织成层次结构; bus目录包含系统中所有的总线类型; class目录包含系统中的设备类型(如网卡设备、 声卡设备、 输入设备等) 。 在/sys目录下运行tree会得到一个相当长的树形目录。
在/sys/bus的pci等子目录下, 又会再分出drivers和devices目录, 而devices目录中的文件是对/sys/devices目录中文件的符号链接。 同样地, /sys/class目录下也包含许多对/sys/devices下文件的链接。 如图5.3所示, Linux设备模型与设备、 驱动、 总线和类的现实状况是直接对应的, 也正符合Linux 2.6以后内核的设备模型。
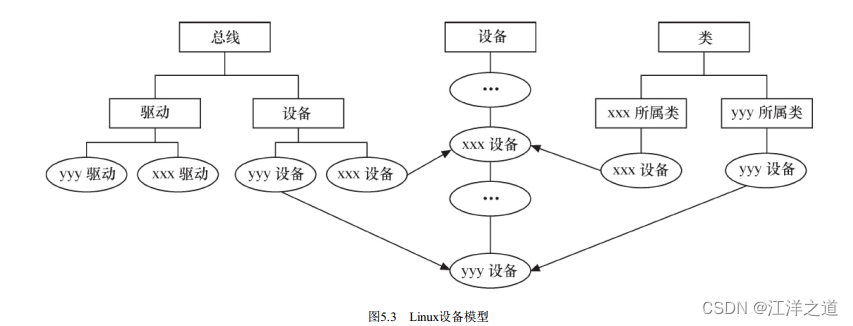
大多数情况下, Linux 2.6以后的内核中的设备驱动核心层代码作为“幕后大佬”可处理好这些关系, 内核中的总线和其他内核子系统会完成与设备模型的交互, 这使得驱动工程师在编写底层驱动的时候几乎不需要关心设备模型, 只需要按照每个框架的要求, “填鸭式”地填充xxx_driver里面的各种回调函数, xxx是总线的名字。
在Linux内核中, 分别使用bus_type、 device_driver和device来描述总线、 驱动和设备, 这3个结构体定义于include/linux/device.h头文件中。
device_driver和device分别表示驱动和设备, 而这两者都必须依附于一种总线, 因此都包含struct bus_type指针。 在Linux内核中, 设备和驱动是分开注册的, 注册1个设备的时候, 并不需要驱动已经存在, 而1个驱动被注册的时候, 也不需要对应的设备已经被注册。 设备和驱动各自涌向内核, 而每个设备和驱动涌入内核的时候, 都会去寻找自己的另一半, 而正是bus_type的match() 成员函数将两者捆绑在一起。 简单地说, 设备和驱动就是红尘中漂浮的男女, 而bus_type的match() 则是牵引红线的月老, 它可以识别什么设备与什么驱动是可配对的。 一旦配对成功, xxx_driver的probe() 就被执行(xxx是总线名, 如platform、 pci、 i2c、 spi、 usb等) 。注意: 总线、 驱动和设备最终都会落实为sysfs中的1个目录, 因为进一步追踪代码会发现, 它们实际上都可以认为是kobject的派生类, kobject可看作是所有总线、 设备和驱动的抽象基类, 1个kobject对应sysfs中的1个目录。
总线、 设备和驱动中的各个attribute则直接落实为sysfs中的1个文件, attribute会伴随着show() 和store() 这两个函数, 分别用于读写该attribute对应的sysfs文件。
udev的组成
udev目前和systemd项目合并在一起了, 见位于 https://lwn.net/Articles/490413/ 的文档《Udev and systemd to merge》 , 可以从 http://cgit.freedesktop.org/systemd/ 、 https://github.com/systemd/systemd 等位置下载最新的代码。
udev在用户空间中执行, 动态建立/删除设备文件, 允许每个人都不用关心主/次设备号而提供LSB(Linux标准规范, Linux Standard Base) 名称, 并且可以根据需要固定名称。 udev的工作过程如下。
1) 当内核检测到系统中出现了新设备后, 内核会通过netlink套接字发送uevent。
2) udev获取内核发送的信息, 进行规则的匹配。 匹配的事物包括SUBSYSTEM、 ACTION、 atttribute、 内核提供的名称(通过KERNEL=) 以及其他的环境变量。
假设在Linux系统上插入一个Kingston的U盘, 我们可以通过udev的工具“udevadm monitor–kernel–property–udev”捕获到的uevent包含的信息。
我们可以根据这些信息, 创建一个规则, 以便每次插入的时候, 为该盘创建一个/dev/kingstonUD的符号链接
udev规则文件
udev的规则文件以行为单位, 以“#”开头的行代表注释行。 其余的每一行代表一个规则。 每个规则分成一个或多个匹配部分和赋值部分。 匹配部分用匹配专用的关键字来表示, 相应的赋值部分用赋值专用的关键字来表示。
匹配关键字包括: ACTION(行为) 、 KERNEL(匹配内核设备名) 、 BUS(匹配总线类型) 、SUBSYSTEM(匹配子系统名) 、 ATTR(属性) 等, 赋值关键字包括: NAME(创建的设备文件名) 、SYMLINK(符号创建链接名) 、 OWNER(设置设备的所有者) 、 GROUP(设置设备的组) 、 IMPORT(调用外部程序) 、 MODE(节点访问权限) 等。
udev规则的写法非常灵活, 在匹配部分, 可以通过“*”、 “? ”、 [a~c]、 [1~9]等shell通配符来灵活匹配多个项目。 *类似于shell中的*通配符, 代替任意长度的任意字符串, ? 代替一个字符。 此外, %k就是KERNEL, %n则是设备的KERNEL序号(如存储设备的分区号) 。
可以借助udev中的udevadm info工具查找规则文件能利用的内核信息和sysfs属性信息。
在嵌入式系统中, 也可以用udev的轻量级版本mdev, mdev集成于busybox中。 在编译busybox的时候, 选中mdev相关项目即可。
Android也没有采用udev, 它采用的是vold。 vold的机制和udev是一样的, 理解了udev, 也就理解了vold。 Android的源代码NetlinkManager.cpp同样是监听基于netlink的套接字, 并解析收到的消息。
总结
Linux用户空间的文件编程有两种方法, 即通过Linux API和通过C库函数访问文件。 用户空间看不到设备驱动,能看到的只有与设备对应的文件, 因此文件编程也就是用户空间的设备编程。
Linux按照功能对文件系统的目录结构进行了良好的规划。 /dev是设备文件的存放目录, devfs和udev分别是Linux2.4和Linux 2.6以后的内核生成设备文件节点的方法, 前者运行于内核空间, 后者运行于用户空间。
Linux 2.6以后的内核通过一系列数据结构定义了设备模型, 设备模型与sysfs文件系统中的目录和文件存在一种对应关系。 设备和驱动分离, 并通过总线进行匹配。
udev可以利用内核通过netlink发出的uevent信息动态创建设备文件节点。
字符设备驱动
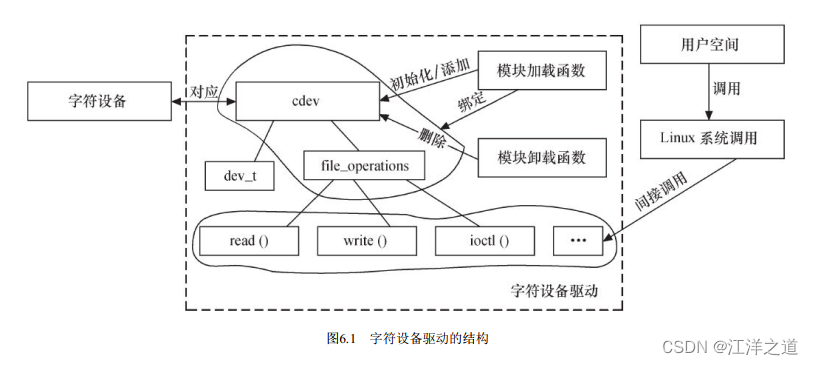
linux字符设备驱动结构
cdev结构体
struct cdev {
struct kobject kobj; /* 内嵌的 kobject 对象 */
struct module *owner; /* 所属模块 */
struct file_operations *ops; /* 文件操作结构体 */
struct list_head list;
dev_t dev; /* 设备号 */
unsigned int count;
};
Linux内核提供了一组函数以用于操作cdev结构体:
void cdev_init(struct cdev *, struct file_operations *);
struct cdev *cdev_alloc(void);
void cdev_put(struct cdev *p);
int cdev_add(struct cdev *, dev_t, unsigned);
void cdev_del(struct cdev *);
cdev_init() 函数用于初始化cdev的成员, 并建立cdev和file_operations之间的连接
cdev_alloc() 函数用于动态申请一个cdev内存
cdev_add() 函数和cdev_del() 函数分别向系统添加和删除一个cdev, 完成字符设备的注册和注销。 对cdev_add() 的调用通常发生在字符设备驱动模块加载函数中, 而对cdev_del() 函数的调用则通常发生在字符设备驱动模块卸载函数中。
分配和释放设备号
在调用cdev_add() 函数向系统注册字符设备之前, 应首先调用register_chrdev_region() 或 alloc_chrdev_region() 函数向系统申请设备号,register_chrdev_region() 函数用于已知起始设备的设备号的情况, 而alloc_chrdev_region() 用于设备号未知,向系统动态申请未被占用的设备号的情况, 函数调用成功之后, 会把得到的设备号放入第一个参数dev中。
alloc_chrdev_region() 相比于register_chrdev_region() 的优点在于它会自动避开设备号重复的冲突。
相应地, 在调用cdev_del() 函数从系统注销字符设备之后, unregister_chrdev_region() 应该被调用以释放原先申请的设备号
file_operations结构体
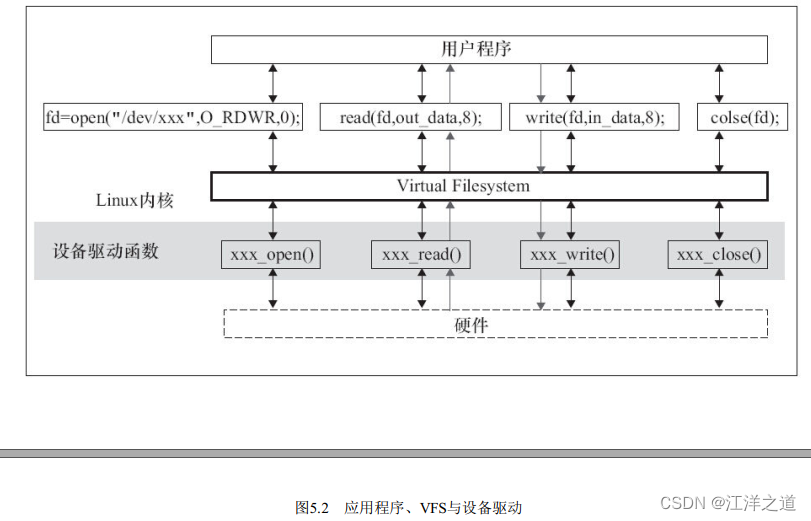
file_operations结构体中的成员函数是字符设备驱动程序设计的主体内容, 这些函数实际会在应用程序进行Linux的open() 、 write() 、 read() 、 close() 等系统调用时最终被内核调用。
llseek() 函数用来修改一个文件的当前读写位置, 并将新位置返回, 在出错时, 这个函数返回一个负值。
read() 函数用来从设备中读取数据, 成功时函数返回读取的字节数, 出错时返回一个负值。 它与用户空间应用程序中的ssize_t read(int fd, voidbuf, size_t count) 和size_t fread(voidptr, size_t size, size_t nmemb, FILE*stream) 对应。
write() 函数向设备发送数据, 成功时该函数返回写入的字节数。 如果此函数未被实现, 当用户进行write()系统调用时, 将得到-EINVAL返回值。 它与用户空间应用程序中的ssize_t write(int fd, const voidbuf, size_t count) 和size_t fwrite(const voidptr, size_t size, size_t nmemb, FILE*stream) 对应。
read() 和write() 如果返回0, 则暗示end-of-file(EOF) 。
unlocked_ioctl() 提供设备相关控制命令的实现(既不是读操作, 也不是写操作) , 当调用成功时, 返回给调用程序一个非负值。 它与用户空间应用程序调用的int fcntl(int fd, int cmd, …/*arg*/) 和int ioctl(int d, int request, …) 对应。
mmap() 函数将设备内存映射到进程的虚拟地址空间中, 如果设备驱动未实现此函数, 用户进行mmap() 系统调用时将获得-ENODEV返回值。 这个函数对于帧缓冲等设备特别有意义, 帧缓冲被映射到用户空间后, 应用程序可以直接访问它而无须在内核和应用间进行内存复制。 它与用户空间应用程序中的
voidmmap(voidaddr, size_t length, int prot, int flags, int fd, off_t offset) 函数对应。
当用户空间调用Linux API函数open() 打开设备文件时, 设备驱动的open() 函数最终被调用。 驱动程序可以不实现这个函数, 在这种情况下, 设备的打开操作永远成功。 与open() 函数对应的是release() 函数。
poll() 函数一般用于询问设备是否可被非阻塞地立即读写。 当询问的条件未触发时, 用户空间进行select() 和poll() 系统调用将引起进程的阻塞。
aio_read() 和aio_write() 函数分别对与文件描述符对应的设备进行异步读、 写操作。 设备实现这两个函数后, 用户空间可以对该设备文件描述符执行SYS_io_setup、 SYS_io_submit、 SYS_io_getevents、 SYS_io_destroy等系统调用进行读写
linux字符设备驱动的组成
在Linux中, 字符设备驱动由如下几个部分组成。
-
字符设备驱动模块加载与卸载函数
在字符设备驱动模块加载函数中应该实现设备号的申请和cdev的注册, 而在卸载函数中应实现设备号的释放和cdev的注销。
Linux内核的编码习惯是为设备定义一个设备相关的结构体, 该结构体包含设备所涉及的cdev、 私有数据及锁等信息。 -
字符设备驱动的file_operations结构体中的成员函数
file_operations结构体中的成员函数是字符设备驱动与内核虚拟文件系统的接口, 是用户空间对Linux进行系统调用最终的落实者。 大多数字符设备驱动会实现read() 、 write() 和ioctl() 函数。
由于用户空间不能直接访问内核空间的内存, 因此借助了函数copy_from_user() 完成用户空间缓冲区到内核空间的复制, 以及copy_to_user() 完成内核空间到用户空间缓冲区的复制。
内核空间虽然可以访问用户空间的缓冲区, 但是在访问之前, 一般需要先检查其合法性, 通过access_ok(type, addr, size) 进行判断, 以确定传入的缓冲区的确属于用户空间
globalmem虚拟设备实例描述
globalmem意味着“全局内存”, 在globalmem字符设备驱动中会分配一片大小为GLOBALMEM_SIZE(4KB) 的内存空间, 并在驱动中提供针对该片内存的读写、 控制和定位函数, 以供用户空间的进程能通过Linux系统调用获取或设置这片内存的内容。
实际上, 这个虚拟的globalmem设备几乎没有任何实用价值, 仅仅是一种为了讲解问题的方便而凭空制造的设备。
globalmem设备驱动
ioctl函数
Linux建议以如图6.2所示的方式定义ioctl() 的命令。
 命令码的设备类型字段为一个“幻数”, 可以是0~0xff的值, 内核中的ioctl-number.txt给出了一些推荐的和已经被使用的“幻数”, 新设备驱动定义“幻数”的时候要避免与其冲突。
命令码的设备类型字段为一个“幻数”, 可以是0~0xff的值, 内核中的ioctl-number.txt给出了一些推荐的和已经被使用的“幻数”, 新设备驱动定义“幻数”的时候要避免与其冲突。
命令码的序列号也是8位宽。
命令码的方向字段为2位, 该字段表示数据传送的方向, 可能的值是_IOC_NONE(无数据传输) 、_IOC_READ(读) 、 _IOC_WRITE(写) 和_IOC_READ|_IOC_WRITE(双向) 。 数据传送的方向是从应用程序的角度来看的。
命令码的数据长度字段表示涉及的用户数据的大小, 这个成员的宽度依赖于体系结构, 通常是13或者14位。
内核还定义了_IO() 、 _IOR() 、 _IOW() 和_IOWR() 这4个宏来辅助生成命令, 这4个宏的通用定义如下所示:
#define _IO(type,nr) _IOC(_IOC_NONE,(type),(nr),0)
#define _IOR(type,nr,size) _IOC(_IOC_READ,(type),(nr),
(_IOC_TYPECHECK(size)))
#define _IOW(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),
(_IOC_TYPECHECK(size)))
#define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),
(_IOC_TYPECHECK(size)))
/* _IO 、 _IOR 等使用的 _IOC 宏 */
#define _IOC(dir,type,nr,size)
(((dir) << _IOC_DIRSHIFT) |
((type) << _IOC_TYPESHIFT) |
((nr) << _IOC_NRSHIFT) |
((size) << _IOC_SIZESHIFT))
由此可见, 这几个宏的作用是根据传入的type(设备类型字段) 、 nr(序列号字段) 、 size(数据长度字段) 和宏名隐含的方向字段移位组合生成命令码。
在container_of(inode->i_cdev, struct globalmem_dev, cdev) 语句中, 传给
container_of() 的第1个参数是结构体成员的指针, 第2个参数为整个结构体的类型, 第3个参数为传入的第1个
参数即结构体成员的类型, container_of() 返回值为整个结构体的指针。
总结
字符设备是3大类设备(字符设备、 块设备和网络设备) 中的一类, 其驱动程序完成的主要工作是初始化、 添加和删除cdev结构体, 申请和释放设备号, 以及填充file_operations结构体中的操作函数, 实现file_operations结构体中的read() 、 write() 和ioctl() 等函数是驱动设计的主体工作。
Linux设备驱动中的并发控制
中断屏蔽、 原子操作、 自旋锁、信号量、 互斥体等是Linux设备驱动中可采用的互斥途径。
编译乱序与执行乱序
代码语句运行的顺序会有编译乱序和执行乱序
编译乱序属于编译器优化问题,可以用barrie()编译屏障解决;
#define barrier() __asm__ __volatile__("": : :"memory")
关于解决编译乱序的问题, C语言volatile关键字的作用较弱, 它更多的只是避免内存访问行为的合并, 对C编译器而言, volatile是暗示除了当前的执行线索以外, 其他的执行线索也可能改变某内存, 所以它的含义是“易变的”。 换句话说, 就是如果线程A读取var这个内存中的变量两次而没有修改var, 编译器可能觉得读一次就行了,第2次直接取第1次的结果。 但是如果加了volatile关键字来形容var, 则就是告诉编译器线程B、 线程C或者其他执行实体可能把var改掉了, 因此编译器就不会再把线程A代码的第2次内存读取优化掉了。 另外, volatile也不具备保护临界资源的作用。 总之, Linux内核明显不太喜欢volatile。
执行乱序属于处理器运行时优化问题,高级的CPU可以根据自己缓存的组织特性, 将访存指令重新排序执行。 连续地址的访问可能会先执行, 因为这样缓存命中率高。 有的还允许访存的非阻塞, 即如果前面一条访存指令因为缓存不命中, 造成长延时的存储访问时, 后面的访存指令可以先执行, 以便从缓存中取数。 因此, 即使是从汇编上看顺序正确的指令, 其执行的顺序也是不可预知的。
处理器为了解决多核间一个核的内存行为对另外一个核可见的问题, 引入了一些内存屏障的指令。 譬如, ARM处理器的屏障指令包括:
DMB(数据内存屏障) : 在DMB之后的显式内存访问执行前, 保证所有在DMB指令之前的内存访问完成;
DSB(数据同步屏障) : 等待所有在DSB指令之前的指令完成(位于此指令前的所有显式内存访问均完成, 位于此指令前的所有缓存、 跳转预测和TLB维护操作全部完成) ;
ISB(指令同步屏障) : Flush流水线, 使得所有ISB之后执行的指令都是从缓存或内存中获得的。
Linux内核的自旋锁、 互斥体等互斥逻辑, 需要用到上述指令: 在请求获得锁时, 调用屏障指令; 在解锁时, 也需要调用屏障指令
中断屏蔽
local_irq_disable() 和local_irq_enable() 都只能禁止和使能本CPU内的中断, 因此, 并不能解决SMP多CPU引发的竞态。 因此, 单独使用中断屏蔽通常不是一种值得推荐的避免竞态的方法(换句话说, 驱动中使用local_irq_disable/enable() 通常意味着一个bug) , 它适合与下文将要介绍的自旋锁联合使用。对于ARM处理器而言, 其底层的实现是屏蔽ARM CPSR的I位。
与local_irq_disable() 不同的是, local_irq_save(flags) 除了进行禁止中断的操作以外, 还保存目前CPU的中断位信息, local_irq_restore(flags) 进行的是与local_irq_save(flags) 相反的操作。 对于ARM处理器而言, 其实就是保存和恢复CPSR。
如果只是想禁止中断的底半部, 应使用local_bh_disable() , 使能被local_bh_disable() 禁止的底半部应该调用local_bh_enable() 。
原子操作
原子操作可以保证对一个整型数据的修改是排他性的。 Linux内核提供了一系列函数来实现内核中的原子操作,这些函数又分为两类, 分别针对位和整型变量进行原子操作。 位和整型变量的原子操作都依赖于底层CPU的原子操作, 因此所有这些函数都与CPU架构密切相关。 对于ARM处理器而言, 底层使用LDREX和STREX指令
ldrex指令跟strex配对使用, 可以让总线监控ldrex到strex之间有无其他的实体存取该地址, 如果有并发的访问, 执行strex指令时, 第一个寄存器的值被设置为1(Non-Exclusive Access) 并且存储的行为也不成功; 如果没有并发的存取, strex在第一个寄存器里设置0(Exclusive Access) 并且存储的行为也是成功的。
整型原子操作
1.设置原子变量的值
void atomic_set(atomic_t *v, int i); /* 设置原子变量的值为 i */
atomic_t v = ATOMIC_INIT(0); /* 定义原子变量 v 并初始化为 0 */
2.获取原子变量的值
atomic_read(atomic_t *v); /* 返回原子变量的值 */
3.原子变量加/减
void atomic_add(int i, atomic_t *v); /* 原子变量增加 i */
void atomic_sub(int i, atomic_t *v); /* 原子变量减少 i */
4.原子变量自增/自减
void atomic_inc(atomic_t *v); /* 原子变量增加 1 */
void atomic_dec(atomic_t *v); /* 原子变量减少 1 */
5.操作并测试
int atomic_inc_and_test(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_sub_and_test(int i, atomic_t *v);
上述操作对原子变量执行自增、 自减和减操作后(注意没有加) , 测试其是否为0, 为0返回true, 否则返回false。
6.操作并返回
int atomic_add_return(int i, atomic_t *v);
int atomic_sub_return(int i, atomic_t *v);
int atomic_inc_return(atomic_t *v);
int atomic_dec_return(atomic_t *v);
上述操作对原子变量进行加/减和自增/自减操作, 并返回新的值。
位原子操作
1.设置位
void set_bit(nr, void *addr);
上述操作设置addr地址的第nr位, 所谓设置位即是将位写为1。
2.清除位
void clear_bit(nr, void *addr);
上述操作清除addr地址的第nr位, 所谓清除位即是将位写为0。
3.改变位
void change_bit(nr, void *addr);
上述操作对addr地址的第nr位进行反置。
4.测试位
test_bit(nr, void *addr);
上述操作返回addr地址的第nr位。
5.测试并操作位
int test_and_set_bit(nr, void *addr);
int test_and_clear_bit(nr, void *addr);
int test_and_change_bit(nr, void *addr);
上述test_and_xxx_bit(nr, void*addr) 操作等同于执行test_bit(nr, void*addr) 后再执行xxx_bit(nr, void*addr) 。
使用原子变量使设备只能被一个进程打开
static atomic_t xxx_available = ATOMIC_INIT(1); /* 定义原子变量 */
static int xxx_open(struct inode *inode, struct file *filp)
{
...
if (!atomic_dec_and_test(&xxx_available)) {
atomic_inc(&xxx_available);
return - EBUSY; /* 已经打开 */
}
...
return 0; /* 成功 */
}
static int xxx_release(struct inode *inode, struct file *filp)
{
atomic_inc(&xxx_available); /* 释放设备 */
return 0;
}
自旋锁的使用
自旋锁(Spin Lock) 是一种典型的对临界资源进行互斥访问的手段, 其名称来源于它的工作方式。 为了获得一个自旋锁, 在某CPU上运行的代码需先执行一个原子操作, 该操作测试并设置(Test-And-Set) 某个内存变量。 由于它是原子操作, 所以在该操作完成之前其他执行单元不可能访问这个内存变量。 如果测试结果表明锁已经空闲, 则程序获得这个自旋锁并继续执行; 如果测试结果表明锁仍
被占用, 程序将在一个小的循环内重复这个“测试并设置”操作, 即进行所谓的“自旋”, 通俗地说就是“在原地打转”。 当自旋锁的持有者通过重置该变量释放这个自旋锁后, 某个等待的“测试并设置”操作向其调用者报告锁已释放。
理解自旋锁最简单的方法是把它作为一个变量看待, 该变量把一个临界区标记为“我当前在运行, 请稍等一会”或者标记为“我当前不在运行, 可以被使用”。 如果A执行单元首先进入例程, 它将持有自旋锁; 当B执行单元试图进入同一个例程时, 将获知自旋锁已被持有, 需等到A执行单元释放后才能进入。
在ARM体系结构下, 自旋锁的实现借用了ldrex指令、 strex指令、 ARM处理器内存屏障指令dmb和dsb、 wfe指令和sev指令。 可以说既要保证排他性, 也要处理好内存屏障。
Linux中与自旋锁相关的操作主要有以下4种。
1.定义自旋锁
spinlock_t lock;
2.初始化自旋锁
spin_lock_init(lock)
该宏用于动态初始化自旋锁lock。
3.获得自旋锁
spin_lock(lock)
该宏用于获得自旋锁lock, 如果能够立即获得锁, 它就马上返回, 否则, 它将在那里自旋, 直到该自旋锁的保持者释放。
spin_trylock(lock)
该宏尝试获得自旋锁lock, 如果能立即获得锁, 它获得锁并返回true, 否则立即返回false, 实际上不再“在原地打转”。
4.释放自旋锁
spin_unlock(lock)
该宏释放自旋锁lock, 它与spin_trylock或spin_lock配对使用。
自旋锁一般这样被使用:
/* 定义一个自旋锁 */
spinlock_t lock;
spin_lock_init(&lock);
spin_lock (&lock) ; /* 获取自旋锁, 保护临界区 */
. . ./* 临界区 */
spin_unlock (&lock) ; /* 解锁 */
在多核SMP的情况下, 任何一个核拿到了自旋锁, 该核上的抢占调度也暂时禁止
了, 但是没有禁止另外一个核的抢占调度。
尽管用了自旋锁可以保证临界区不受别的CPU和本CPU内的抢占进程打扰, 但是得到锁的代码路径在执行临界区的时候, 还可能受到中断和底半部(BH, 稍后的章节会介绍) 的影响。 为了防止这种影响, 就需要用到自旋锁的衍生。
spin_lock() /spin_unlock() 是自旋锁机制的基础, 它们和关中断local_irq_disable() /开中断local_irq_enable() 、 关底半部local_bh_disable() /开底半部local_bh_enable() 、 关中断并保存状态字local_irq_save() /开中断并恢复状态字local_irq_restore() 结合就形成了整套自旋锁机制,
关系如下:
spin_lock_irq() = spin_lock() + local_irq_disable()
spin_unlock_irq() = spin_unlock() + local_irq_enable()
spin_lock_irqsave() = spin_lock() + local_irq_save()
spin_unlock_irqrestore() = spin_unlock() + local_irq_restore()
spin_lock_bh() = spin_lock() + local_bh_disable()
spin_unlock_bh() = spin_unlock() + local_bh_enable()
spin_lock_irq() 、 spin_lock_irqsave() 、 spin_lock_bh() 类似函数会为自旋锁的使用系好“安全带”以避免突如其来的中断驶入对系统造成的伤害。
在多核编程的时候, 如果进程和中断可能访问同一片临界资源, 我们一般需要在进程上下文中调用spin_lock_irqsave() /spin_unlock_irqrestore() , 在中断上下文中调用spin_lock() /spin_unlock() , 如图7.8所示。
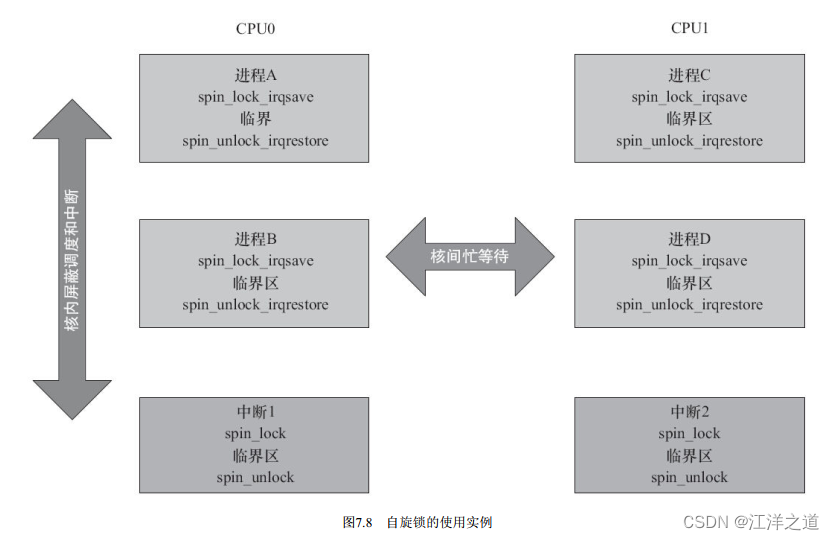
这样, 在CPU0上, 无论是进程上下文, 还是中断上下文获得了自旋锁, 此后, 如果CPU1无论是进程上下文, 还是中断上下文, 想获得同一自旋锁, 都必须忙等待, 这避免一切核间并发的可能性。 同时, 由于每个核的进程上下文持有锁的时候用的是spin_lock_irqsave() , 所以该核上的中断是不可能进入的, 这避免了核内并发的可能性。
驱动工程师应谨慎使用自旋锁, 而且在使用中还要特别注意如下几个问题。
1) 自旋锁实际上是忙等锁, 当锁不可用时, CPU一直循环执行“测试并设置”该锁直到可用而取得该锁, CPU在等待自旋锁时不做任何有用的工作, 仅仅是等待。 因此, 只有在占用锁的时间极短的情况下, 使用自旋锁才是合理的。 当临界区很大, 或有共享设备的时候, 需要较长时间占用锁, 使用自旋锁会降低系统的性能。
2) 自旋锁可能导致系统死锁。 引发这个问题最常见的情况是递归使用一个自旋锁, 即如果一个已经拥有某个自旋锁的CPU想第二次获得这个自旋锁, 则该CPU将死锁。
3) 在自旋锁锁定期间不能调用可能引起进程调度的函数。 如果进程获得自旋锁之后再阻塞, 如调用copy_from_user() 、copy_to_user() 、 kmalloc() 和msleep() 等函数, 则可能导致内核的崩溃。
4) 在单核情况下编程的时候, 也应该认为自己的CPU是多核的, 驱动特别强调跨平台的概念。 比如, 在单CPU的情况下, 若中断和进程可能访问同一临界区, 进程里调用spin_lock_irqsave() 是安全的, 在中断里其实不调用spin_lock() 也没有问题, 因为spin_lock_irqsave() 可以保证这个CPU的中断服务程序不可能执行。 但是, 若CPU变成多核, spin_lock_irqsave() 不能屏蔽另外一个
核的中断, 所以另外一个核就可能造成并发问题。 因此, 无论如何, 我们在中断服务程序里也应该调用spin_lock() 。
使用自旋锁使设备只能被一个进程打开
int xxx_count = 0;/* 定义文件打开次数计数 */
static int xxx_open(struct inode *inode, struct file *filp)
{
...
spinlock(&xxx_lock);
if (xxx_count) {/* 已经打开 */
spin_unlock(&xxx_lock);
return -EBUSY;
}
xxx_count++;/* 增加使用计数 */
spin_unlock(&xxx_lock);
...
return 0;/* 成功 */
}
static int xxx_release(struct inode *inode, struct file *filp)
{
...
spinlock(&xxx_lock);
xxx_count--;/* 减少使用计数 */
spin_unlock(&xxx_lock);
return 0;
}
读写自旋锁
读写自旋锁一般这样被使用:
rwlock_t lock; /* 定义 rwlock */
rwlock_init(&lock); /* 初始化 rwlock */
/* 读时获取锁 */
read_lock(&lock);
... /* 临界资源 */
read_unlock(&lock);
/* 写时获取锁 */
write_lock_irqsave(&lock, flags);
... /* 临界资源 */
write_unlock_irqrestore(&lock, flags);
顺序锁
顺序锁(seqlock) 是对读写锁的一种优化, 若使用顺序锁, 读执行单元不会被写执行单元阻塞, 也就是说, 读执行单元在写执行单元对被顺序锁保护的共享资源进行写操作时仍然可以继续读, 而不必等待写执行单元完成写操作, 写执行单元也不需要等待所有读执行单元完成读操作才去进行写操作。 但是, 写执行单元与写执行单元之间仍然是互斥的, 即如果有写执行单元在进行写操作, 其他写执行单元必须自旋在那里, 直到写执行单元释放了顺序锁。
对于顺序锁而言, 尽管读写之间不互相排斥, 但是如果读执行单元在读操作期间, 写执行单元已经发生了写操作, 那么, 读执行单元必须重新读取数据, 以便确保得到的数据是完整的。 所以, 在这种情况下, 读端可能反复读多次同样的区域才能读到有效的数据
在Linux内核中, 写执行单元涉及的顺序锁操作如下。
1.获得顺序锁
void write_seqlock(seqlock_t *sl);
int write_tryseqlock(seqlock_t *sl);
write_seqlock_irqsave(lock, flags)
write_seqlock_irq(lock)
write_seqlock_bh(lock)
其中,
write_seqlock_irqsave() = loal_irq_save() + write_seqlock()
write_seqlock_irq() = local_irq_disable() + write_seqlock()
write_seqlock_bh() = local_bh_disable() + write_seqlock()
2.释放顺序锁
void write_sequnlock(seqlock_t *sl);
write_sequnlock_irqrestore(lock, flags)
write_sequnlock_irq(lock)
write_sequnlock_bh(lock)
其中,
write_sequnlock_irqrestore() = write_sequnlock() + local_irq_restore()
write_sequnlock_irq() = write_sequnlock() + local_irq_enable()
write_sequnlock_bh() = write_sequnlock() + local_bh_enable()
写执行单元使用顺序锁的模式如下:
write_seqlock(&seqlock_a);
.../* 写操作代码块 */
write_sequnlock(&seqlock_a);
因此, 对写执行单元而言, 它的使用与自旋锁相同。
读执行单元涉及的顺序锁操作如下。
1.读开始
unsigned read_seqbegin(const seqlock_t *sl);
read_seqbegin_irqsave(lock, flags)
读执行单元在对被顺序锁s1保护的共享资源进行访问前需要调用该函数, 该函数返回顺序锁s1的当前顺序号。 其中,
read_seqbegin_irqsave() = local_irq_save() + read_seqbegin()
2.重读
int read_seqretry(const seqlock_t *sl, unsigned iv);
read_seqretry_irqrestore(lock, iv, flags)
读执行单元在访问完被顺序锁s1保护的共享资源后需要调用该函数来检查, 在读访问期间是否有写操作。 如果有
写操作, 读执行单元就需要重新进行读操作。 其中,
read_seqretry_irqrestore() = read_seqretry() + local_irq_restore()
读执行单元使用顺序锁的模式如下:
do {
seqnum = read_seqbegin(&seqlock_a);
/* 读操作代码块 */
...
} while (read_seqretry(&seqlock_a, seqnum))
顺序锁比读写锁的优势:读写可以同时进行,只是,在读的过程中发生了写的话,需要重新读
读-复制-更新
RCU(Read-Copy-Update, 读-复制-更新),不同于自旋锁, 使用RCU的读端没有锁、 内存屏障、 原子指令类的开销, 几乎可以认为是直接读(只是简单地
标明读开始和读结束) , 而RCU的写执行单元在访问它的共享资源前首先复制一个副本, 然后对副本进行修改, 最后使用一个回调机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据, 这个时机就是所有引用该数据的CPU都退出对共享数据读操作的时候。 等待适当时机的这一时期称为宽限期(Grace Period) 。
RCU可以看作读写锁的高性能版本, 相比读写锁, RCU的优点在于既允许多个读执行单元同时访问被保护的数据, 又允许多个读执行单元和多个写执行单元同时访问被保护的数据。 但是, RCU不能替代读写锁, 因为如果写比较多时, 对读执行单元的性能提高不能弥补写执行单元同步导致的损失。 因为使用RCU时, 写执行单元之间的同步开销会比较大, 它需要延迟数据结构的释放, 复制被修改的数据结构, 它也必须使用某种锁机制来同步并发的其他写执行单元的修改操作
Linux中提供的RCU操作包括如下4种。
1.读锁定
rcu_read_lock()
rcu_read_lock_bh()
2.读解锁
rcu_read_unlock()
rcu_read_unlock_bh()
使用RCU进行读的模式如下:
rcu_read_lock()
.../* 读临界区 */
rcu_read_unlock()
3.同步RCU
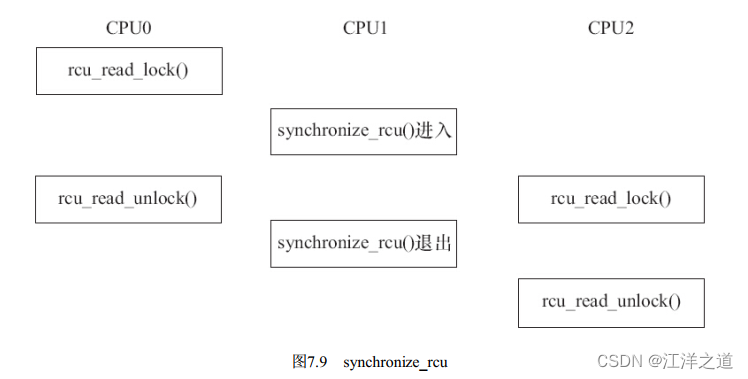
synchronize_rcu()
该函数由RCU写执行单元调用, 它将阻塞写执行单元, 直到当前CPU上所有的已经存在(Ongoing) 的读执行单元完成读临界区, 写执行单元才可以继续下一步操作。 synchronize_rcu() 并不需要等待后续(Subsequent) 读临界区的完成, 如图7.9所示。
void call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu));
函数call_rcu() 也由RCU写执行单元调用, 与synchronize_rcu() 不同的是, 它不会使写执行单元阻塞, 因而可以在中断上下文或软中断中使用。 该函数把函数func挂接到RCU回调函数链上, 然后立即返回。 挂接的回调函数会在一个宽限期结束(即所有已经存在的RCU读临界区完成) 后被执行。
rcu_assign_pointer(p, v)
给RCU保护的指针赋一个新的值。
rcu_dereference(p)
读端使用rcu_dereference() 获取一个RCU保护的指针, 之后既可以安全地引用它(访问它指向的区域) 。 一般需要在rcu_read_lock() /rcu_read_unlock() 保护的区间引用这个指针
rcu_access_pointer(p)
读端使用rcu_access_pointer() 获取一个RCU保护的指针, 之后并不引用它。 这种情况下, 我们只关心指针本身的值, 而不关心指针指向的内容。 比如我们可以使用该API来判断指针是否为NULL。
把rcu_assign_pointer() 和rcu_dereference() 结合起来使用, 写端分配一个新的struct foo内存, 并初始化其中的成员, 之后把该结构体的地址赋值给全局的gp指针:
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gp, p);
读端访问该片区域:
rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
在上述代码中, 我们可以把写端rcu_assign_pointer() 看成发布(Publish) 了gp, 而读端rcu_dereference() 看成订阅(Subscribe) 了gp。 它保证读端可以看到rcu_assign_pointer() 之前所有内存被设置的情况(即gp->a, gp->b, gp->c等于1、 2、 3对于读端可见) 。 由此可见, 与RCU相关的原语已经内嵌了相关的编译屏障或内存屏障。
对于链表数据结构而言, Linux内核增加了专门的RCU保护的链表操作API:
static inline void list_add_rcu(struct list_head *new, struct list_head *head);
该函数把链表元素new插入RCU保护的链表head的开头。
static inline void list_add_tail_rcu(struct list_head *new, struct list_head *head);
该函数类似于list_add_rcu() , 它将把新的链表元素new添加到被RCU保护的链表的末尾。
static inline void list_del_rcu(struct list_head *entry);
该函数从RCU保护的链表中删除指定的链表元素entry。
static inline void list_replace_rcu(struct list_head *old, struct list_head *new);
它使用新的链表元素new取代旧的链表元素old。
list_for_each_entry_rcu(pos, head)
该宏用于遍历由RCU保护的链表head, 只要在读执行单元临界区使用该函数, 它就可以安全地和其他RCU保护的链表操作函数(如list_add_rcu() ) 并发运行。
信号量
Linux中与信号量相关的操作主要有下面几种。
1.定义信号量
下列代码定义名称为sem的信号量:
struct semaphore sem;
2.初始化信号量
void sema_init(struct semaphore *sem, int val);
该函数初始化信号量, 并设置信号量sem的值为val。
3.获得信号量
void down(struct semaphore * sem);
该函数用于获得信号量sem, 它会导致睡眠, 因此不能在中断上下文中使用。
int down_interruptible(struct semaphore * sem);
该函数功能与down类似, 不同之处为, 因为down() 进入睡眠状态的进程不能被信号打断, 但因为down_interruptible() 进入睡眠状态的进程能被信号打断, 信号也会导致该函数返回, 这时候函数的返回值非0。
int down_trylock(struct semaphore * sem);
该函数尝试获得信号量sem, 如果能够立刻获得, 它就获得该信号量并返回0, 否则, 返回非0值。 它不会导致调用者睡眠, 可以在中断上下文中使用。
在使用down_interruptible() 获取信号量时, 对返回值一般会进行检查, 如果非0, 通常立即返回-ERESTARTSYS, 如:
if (down_interruptible(&sem))
return -ERESTARTSYS;
4.释放信号量
void up(struct semaphore * sem);
该函数释放信号量sem, 唤醒等待者。
作为一种可能的互斥手段, 信号量可以保护临界区, 它的使用方式和自旋锁类似。 与自旋锁相同, 只有得到信号量的进程才能执行临界区代码。
但是, 与自旋锁不同的是, 当获取不到信号量时, 进程不会原地打转而是进入休眠等待状态。
互斥体
尽管信号量已经可以实现互斥的功能, 但是“正宗”的mutex在Linux内核中还是真实地存在着。
下面代码定义了名为my_mutex的互斥体并初始化它:
struct mutex my_mutex;
mutex_init(&my_mutex);
下面的两个函数用于获取互斥体:
void mutex_lock(struct mutex *lock);
int mutex_lock_interruptible(struct mutex *lock);
int mutex_trylock(struct mutex *lock);
mutex_lock() 与mutex_lock_interruptible() 的区别和down() 与down_trylock() 的区别完全一致, 前者引起的睡眠不能被信号打断, 而后者可以。 mutex_trylock() 用于尝试获得mutex, 获取不到mutex时不会引起进程睡
眠。
下列函数用于释放互斥体:
void mutex_unlock(struct mutex *lock);
mutex的使用方法和信号量用于互斥的场合完全一样:
struct mutex my_mutex; /* 定义 mutex */
mutex_init(&my_mutex); /* 初始化 mutex */
mutex_lock(&my_mutex); /* 获取 mutex */
... /* 临界资源 */
mutex_unlock(&my_mutex); /* 释放 mutex */
1) 当锁不能被获取到时, 使用互斥体的开销是进程上下文切换时间, 使用自旋锁的开销是等待获取自旋锁( 由临界区执行时间决定) 。 若临界区比较小, 宜使用自旋锁, 若临界区很大, 应使用互斥体。
2) 互斥体所保护的临界区可包含可能引起阻塞的代码, 而自旋锁则绝对要避免用来保护包含这样代码的临界区。 因为阻塞意味着要进行进程的切换, 如果进程被切换出去后, 另一个进程企图获取本自旋锁, 死锁就会发生。
3) 互斥体存在于进程上下文, 因此, 如果被保护的共享资源需要在中断或软中断情况下使用, 则在互斥体和自旋锁之间只能选择自旋锁。 当然, 如果一定要使用互斥体, 则只能通过mutex_trylock( ) 方式进行, 不能获取就立即返回以避免阻塞。
完成量
Linux中与完成量相关的操作主要有以下4种。
1.定义完成量
下列代码定义名为my_completion的完成量:
struct completion my_completion;
2.初始化完成量
下列代码初始化或者重新初始化my_completion这个完成量的值为0(即没有完成的状态) :
i
nit_completion(&my_completion);
reinit_completion(&my_completion)
3.等待完成量
下列函数用于等待一个完成量被唤醒:
void wait_for_completion(struct completion *c);
4.唤醒完成量
下面两个函数用于唤醒完成量:
void complete(struct completion *c);
void complete_all(struct completion *c);
前者只唤醒一个等待的执行单元, 后者释放所有等待同一完成量的执行单元。
总结
并发和竞态广泛存在, 中断屏蔽、 原子操作、 自旋锁和互斥体都是解决并发问题的机制。 中断屏蔽很少单独被使用, 原子操作只能针对整数进行, 因此自旋锁和互斥体应用最为广泛。
自旋锁会导致死循环, 锁定期间不允许阻塞, 因此要求锁定的临界区小。 互斥体允许临界区阻塞, 可以适用于临界区大的情况。
linux设备驱动中的阻塞与费阻塞I/O
阻塞与费阻塞I/O
除了在打开文件时可以指定阻塞还是非阻塞方式以外, 在文件打开后, 也可以通过ioctl() 和fcntl() 改变读写的方式, 如从阻塞变更为非阻塞或者从非阻塞变更为阻塞。 例如, 调用fcntl(fd, F_SETFL, O_NONBLOCK) 可以设置fd对应的I/O为非阻塞。
等待队列
Linux内核提供了如下关于等待队列的操作。
1.定义“等待队列头部”
wait_queue_head_t my_queue;
wait_queue_head_t是__wait_queue_head结构体的一个typedef。
2.初始化“等待队列头部”
init_waitqueue_head(&my_queue);
而下面的DECLARE_WAIT_QUEUE_HEAD() 宏可以作为定义并初始化等待队列头部的“快捷方式”。
DECLARE_WAIT_QUEUE_HEAD (name)
3.定义等待队列元素
DECLARE_WAITQUEUE(name, tsk)
该宏用于定义并初始化一个名为name的等待队列元素。
4.添加/移除等待队列
void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
void remove_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
add_wait_queue() 用于将等待队列元素wait添加到等待队列头部q指向的双向链表中, 而remove_wait_queue() 用于将等待队列元素wait从由q头部指向的链表中移除。
5.等待事件
wait_event(queue, condition)
wait_event_interruptible(queue, condition)
wait_event_timeout(queue, condition, timeout)
wait_event_interruptible_timeout(queue, condition, timeout)
等待第1个参数queue作为等待队列头部的队列被唤醒, 而且第2个参数condition必须满足, 否则继续阻塞。 wait_event() 和
wait_event_interruptible() 的区别在于后者可以被信号打断, 而前者不能。 加上_timeout后的宏意味着阻塞等待的超时时间, 在第3个参数的timeout到达时, 不论condition是否满足, 均返回。
6.唤醒队列
void wake_up(wait_queue_head_t *queue);
void wake_up_interruptible(wait_queue_head_t *queue);
上述操作会唤醒以queue作为等待队列头部的队列中所有的进程。
wake_up() 应该与wait_event() 或wait_event_timeout() 成对使用, 而wake_up_interruptible() 则应与wait_event_interruptible()或wait_event_interruptible_timeout() 成对使用。 wake_up() 可唤醒处于TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE的进程, 而wake_up_interruptible() 只能唤醒处于TASK_INTERRUPTIBLE的进程。
7.在等待队列上睡眠
sleep_on(wait_queue_head_t *q );
interruptible_sleep_on(wait_queue_head_t *q );
sleep_on() 函数的作用就是将目前进程的状态置成TASK_UNINTERRUPTIBLE, 并定义一个等待队列元素, 之后把它挂到等待队
列头部q指向的双向链表, 直到资源可获得, q队列指向链接的进程被唤醒。
interruptible_sleep_on() 与sleep_on() 函数类似, 其作用是将目前进程的状态置成TASK_INTERRUPTIBLE, 并定义一个等待队列元素, 之后把它附属到q指向的队列, 直到资源可获得(q指引的等待队列被唤醒) 或者进程收到信号。
sleep_on() 函数应该与wake_up() 成对使用, interruptible_sleep_on() 应该与wake_up_interruptible() 成对使用。
在用户空间验证globalfifo的读写
个人例程(结合了之前第六章讲的多个设备):
/*
* a simple char device driver: globalfifo without mutex
*
* Copyright (C) 2014 Barry Song (baohua@kernel.org)
*
* Licensed under GPLv2 or later.
*/
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#include <linux/signal.h>
#define GLOBALFIFO_SIZE 0x1000
#define MEM_CLEAR 0x1
#define GLOBALFIFO_MAJOR 230
#define DEVICE_NUM 10
static int globalfifo_major = GLOBALFIFO_MAJOR;
module_param(globalfifo_major, int, S_IRUGO);
struct globalfifo_dev {
struct cdev cdev;
unsigned int current_len;
unsigned char mem[GLOBALFIFO_SIZE];
struct mutex mutex;
wait_queue_head_t r_wait;
wait_queue_head_t w_wait;
};
struct globalfifo_dev *globalfifo_devp;
static int globalfifo_open(struct inode *inode, struct file *filp)
{
struct globalfifo_dev *dev = container_of(inode->i_cdev, struct globalfifo_dev, cdev);
filp->private_data = dev;
return 0;
}
static int globalfifo_release(struct inode *inode, struct file *filp)
{
return 0;
}
static long globalfifo_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
struct globalfifo_dev *dev = filp->private_data;
switch (cmd) {
case MEM_CLEAR:
mutex_lock(&dev->mutex);
memset(dev->mem, 0, GLOBALFIFO_SIZE);
mutex_unlock(&dev->mutex);
printk(KERN_INFO "globalfifo is set to zeron");
break;
default:
return -EINVAL;
}
return 0;
}
static ssize_t globalfifo_read(struct file *filp, char __user * buf, size_t count,loff_t * ppos)
{
int ret = 0;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
mutex_lock(&dev->mutex);
add_wait_queue(&dev->r_wait, &wait);
while(dev->current_len == 0) {
if(filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE);
mutex_unlock(&dev->mutex);
schedule();
if(signal_pending(current)){
ret = - ERESTARTSYS;
goto out2;
}
mutex_lock(&dev->mutex);
}
if (count > dev->current_len)
count = dev->current_len;
if (copy_to_user(buf, dev->mem, count)) {
ret = -EFAULT;
goto out;
} else {
memcpy(dev->mem, dev->mem + count, dev->current_len - count);
dev->current_len -= count;
printk(KERN_INFO "read %u bytes(s) from %lun", count, dev->current_len);
wake_up_interruptible(&dev->w_wait);
ret = count;
}
out:
mutex_unlock(&dev->mutex);
out2:
remove_wait_queue(&dev->r_wait, &wait);
set_current_state(TASK_RUNING);
return ret;
}
static ssize_t globalfifo_write(struct file *filp, const char __user * buf, size_t count, loff_t * ppos)
{
int ret = 0;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
mutex_lock(&dev->mutex);
add_wait_queue(&dev->w_wait, &wait);
while(dev->current_len == GLOBALFIFO_SIZE){
if(filp->f_flags & O_NONBLOCK){
ret = -EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE);
mutex_unlock(&dev->mutex);
schedule();
if(signal_pending(current)){
ret = -ERESTARTSYS;
goto out2;
}
mutex_lock(&dev->mutex);
}
if (count > GLOBALFIFO_SIZE - dev->current_len)
count = GLOBALFIFO_SIZE - dev->current_len;
if (copy_from_user(dev->mem + dev->current_len, buf, count)){
ret = -EFAULT;
goto out;
} else {
dev->current_len += count;
printk(KERN_INFO "written %u bytes(s) from %lun", count, dev->current_len);
wake_up_interruptible(&dev->r_wait);
ret = count;
}
out:
mutex_unlock(&dev->mutex);
out2:
remove_wait_queue(&dev->w_wait, &wait);
set_current_state(TASK_RUNNING);
return ret;
}
static loff_t globalfifo_llseek(struct file *filp, loff_t offset, int orig)
{
loff_t ret = 0;
switch (orig) {
case 0: /* 从文件开头位置 seek */
if (offset< 0) {
ret = -EINVAL;
break;
}
if ((unsigned int)offset > GLOBALFIFO_SIZE) {
ret = -EINVAL;
break;
}
filp->f_pos = (unsigned int)offset;
ret = filp->f_pos;
break;
case 1: /* 从文件当前位置开始 seek */
if ((filp->f_pos + offset) > GLOBALFIFO_SIZE) {
ret = -EINVAL;
break;
}
if ((filp->f_pos + offset) < 0) {
ret = -EINVAL;
break;
}
filp->f_pos += offset;
ret = filp->f_pos;
break;
default:
ret = -EINVAL;
break;
}
return ret;
}
static const struct file_operations globalfifo_fops = {
.owner = THIS_MODULE,
.llseek = globalfifo_llseek,
.read = globalfifo_read,
.write = globalfifo_write,
.unlocked_ioctl = globalfifo_ioctl,
.open = globalfifo_open,
.release = globalfifo_release,
};
static void globalfifo_setup_cdev(struct globalfifo_dev *dev, int index)
{
int err, devno = MKDEV(globalfifo_major, index);
cdev_init(&dev->cdev, &globalfifo_fops);
dev->cdev.owner = THIS_MODULE;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_NOTICE "Error %d adding globalfifo%d", err, index);
}
static int __init globalfifo_init(void)
{
int ret;
dev_t devno = MKDEV(globalfifo_major, 0);
if (globalfifo_major)
ret = register_chrdev_region(devno, DEVICE_NUM, "globalfifo");
else {
ret = alloc_chrdev_region(&devno, 0, DEVICE_NUM, "globalfifo");
globalfifo_major = MAJOR(devno);
}
if (ret < 0)
return ret;
globalfifo_devp = kzalloc(sizeof(struct globalfifo_dev) * DEVICE_NUM, GFP_KERNEL);
if (!globalfifo_devp) {
ret = -ENOMEM;
goto fail_malloc;
}
int i = 0;
for (i = 0; i < DEVICE_NUM; i++)
{
mutex_init(&(globalfifo_devp + i)->mutex);
globalfifo_setup_cdev(globalfifo_devp + i, i);
init_waitqueue_head(&(globalfifo_devp + i)->r_wait);
init_waitqueue_head(&(globalfifo_devp + i)->w_wait);
}
return 0;
fail_malloc:
unregister_chrdev_region(devno, DEVICE_NUM);
return ret;
}
module_init(globalfifo_init);
static void __exit globalfifo_exit(void)
{
int i = 0;
for (i = 0; i < DEVICE_NUM; i++)
{
cdev_del(&globalfifo_devp->cdev);
}
kfree(globalfifo_devp);
unregister_chrdev_region(MKDEV(globalfifo_major, 0), DEVICE_NUM);
}
module_exit(globalfifo_exit);
MODULE_AUTHOR("Barry Song <baohua@kernel.org>");
MODULE_LICENSE("GPL v2");
Makefile:
KVERS = $(shell uname -r)
# Kernel modules
obj-m := xbw_globalfifo.o
xbw_globalfifo-objs := globalfifo.o
# Specify flags for the module compilation.
EXTRA_CFLAGS=-g -O0
build: kernel_modules
kernel_modules:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) modules
clean:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean
实际使用:
- make
得到xbw_globalfifo.ko - insmod xbw_globalfifo.ko
- mknod /dev/globalfifo0 c 230 0
- 剩余步骤与书籍保持一致:
启动两个进程, 一个进程cat/dev/globalfifo&在后台执行, 一个进程“echo字符串/dev/globalfifo”在前台执行

轮询操作
应用程序中的轮询编程
应用程序中最广泛用到的是BSD UNIX中引入的select() 系统调用, 其原型为:
int select(int numfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
其中readfds、 writefds、 exceptfds分别是被select() 监视的读、 写和异常处理的文件描述符集合, numfds的值是需要检查的号码最高的fd加1。 readfds文件集中的任何一个文件变得可读, select() 返回; 同理, writefds文件集中的任何一个文件变得可写, select也返回。
如图8.3所示, 第一次对n个文件进行select() 的时候, 若任何一个文件满足要求, select() 就直接返回; 第2次再进行select() 的时候, 没有文件满足读写要求, select() 的进程阻塞且睡眠。 由于调用select() 的时候, 每个驱动的poll() 接口都会被调用到, 实际上执行select() 的进程被挂到了每个驱动的等待队列上, 可以被任何一个驱动唤醒。 如果FDn变得可读写, select() 返回。
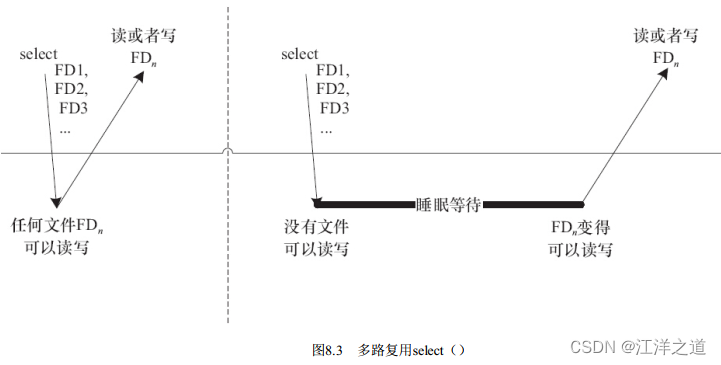
timeout参数是一个指向struct timeval类型的指针, 它可以使select() 在等待timeout时间后若仍然没有文件描述符准备好则超时返回。
poll() 的功能和实现原理与select() 相似, 其函数原型为:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
当多路复用的文件数量庞大、 I/O流量频繁的时候, 一般不太适合使用select() 和poll() , 此种情况下, select() 和poll() 的性能表现较差, 我们宜使用epoll。 epoll的最大好处是不会随着fd的数目增长而降低效率, select() 则会随着fd的数量增大性能下降明显。
与epoll相关的用户空间编程接口包括:
int epoll_create(int size);
创建一个epoll的句柄, size用来告诉内核要监听多少个fd。 需要注意的是, 当创建好epoll句柄后, 它本身也会占用一个fd值, 所以在使用完epoll后, 必须调用close() 关闭。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
告诉内核要监听什么类型的事件。 第1个参数是epoll_create() 的返回值, 第2个参数表示动作, 包含:
EPOLL_CTL_ADD: 注册新的fd到epfd中。
EPOLL_CTL_MOD: 修改已经注册的fd的监听事件。
EPOLL_CTL_DEL: 从epfd中删除一个fd。
第3个参数是需要监听的fd, 第4个参数是告诉内核需要监听的事件类型, struct epoll_event结构如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的“或”:
EPOLLIN: 表示对应的文件描述符可以读。
EPOLLOUT: 表示对应的文件描述符可以写。
EPOLLPRI: 表示对应的文件描述符有紧急的数据可读(这里应该表示的是有socket带外数据到来) 。
EPOLLERR: 表示对应的文件描述符发生错误。
EPOLLHUP: 表示对应的文件描述符被挂断。
EPOLLET: 将epoll设为边缘触发(Edge Triggered) 模式, 这是相对于水平触发(Level Triggered) 来说的。 LT(Level Triggered) 是缺省的工作方式, 在LT情况下, 内核告诉用户一个fd是否就绪了, 之后用户可以对这个就绪的fd进行I/O操作。 但是如果用户不进行任何操作, 该事件并不会丢失, 而ET(Edge-Triggered) 是高速工作方式, 在这种模式下, 当fd从未就绪变为就绪时, 内核通过epoll告诉用户, 然后它会假设用户知道fd已经就绪, 并且不会再为那个fd发送更多的就绪通知。
EPOLLONESHOT: 意味着一次性监听, 当监听完这次事件之后, 如果还需要继续监听这个fd的话, 需要再次把这个fd加入到epoll队列里。
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待事件的产生, 其中events参数是输出参数, 用来从内核得到事件的集合, maxevents告诉内核本次最多收多少事件, maxevents的值不能大于创建epoll_create() 时的size, 参数timeout是超时时间(以毫秒为单位, 0意味着立即返回, -1意味着永久等待) 。 该函数的返回值是需要处理的事件数目, 如返回0, 则表示已超时。
设备驱动中的轮询编程
设备驱动中poll() 函数的原型是:
unsigned int(*poll)(struct file * filp, struct poll_table* wait);
第1个参数为file结构体指针, 第2个参数为轮询表指针。 这个函数应该进行两项工作。
1) 对可能引起设备文件状态变化的等待队列调用poll_wait() 函数, 将对应的等待队列头部添加到poll_table中。
2) 返回表示是否能对设备进行无阻塞读、 写访问的掩码。
用于向poll_table注册等待队列的关键poll_wait() 函数的原型如下:
void poll_wait(struct file *filp, wait_queue_heat_t *queue, poll_table * wait);
poll_wait() 函数的名称非常容易让人产生误会, 以为它和wait_event() 等一样, 会阻塞地等待某事件的发生, 其实这个函数并不会引起阻塞。 poll_wait() 函数所做的工作是把当前进程添加到wait参数指定的等待列表(poll_table) 中, 实际作用是让唤醒参数queue对应的等待队列可以唤醒因select() 而睡眠的进程。
驱动程序poll() 函数应该返回设备资源的可获取状态, 即POLLIN、 POLLOUT、 POLLPRI、 POLLERR、POLLNVAL等宏的位“或”结果。 每个宏的含义都表明设备的一种状态, 如POLLIN(定义为0x0001) 意味着设备可以无阻塞地读, POLLOUT(定义为0x0004) 意味着设备可以无阻塞地写
支持轮询操作的globalfifo驱动
在globalfifo驱动中增加轮询操作
/*
* a simple char device driver: globalfifo without mutex
*
* Copyright (C) 2014 Barry Song (baohua@kernel.org)
*
* Licensed under GPLv2 or later.
*/
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#include <linux/signal.h>
#include <linux/sched/signal.h>
#include <linux/poll.h>
#define GLOBALFIFO_SIZE 0x1000
#define MEM_CLEAR 0x1
#define GLOBALFIFO_MAJOR 230
#define DEVICE_NUM 10
static int globalfifo_major = GLOBALFIFO_MAJOR;
module_param(globalfifo_major, int, S_IRUGO);
struct globalfifo_dev {
struct cdev cdev;
unsigned int current_len;
unsigned char mem[GLOBALFIFO_SIZE];
struct mutex mutex;
wait_queue_head_t r_wait;
wait_queue_head_t w_wait;
};
struct globalfifo_dev *globalfifo_devp;
static int globalfifo_open(struct inode *inode, struct file *filp)
{
struct globalfifo_dev *dev = container_of(inode->i_cdev, struct globalfifo_dev, cdev);
filp->private_data = dev;
return 0;
}
static int globalfifo_release(struct inode *inode, struct file *filp)
{
return 0;
}
static long globalfifo_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
struct globalfifo_dev *dev = filp->private_data;
switch (cmd) {
case MEM_CLEAR:
mutex_lock(&dev->mutex);
memset(dev->mem, 0, GLOBALFIFO_SIZE);
mutex_unlock(&dev->mutex);
printk(KERN_INFO "globalfifo is set to zeron");
break;
default:
return -EINVAL;
}
return 0;
}
static ssize_t globalfifo_read(struct file *filp, char __user * buf, size_t count,loff_t * ppos)
{
int ret = 0;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
mutex_lock(&dev->mutex);
add_wait_queue(&dev->r_wait, &wait);
while(dev->current_len == 0) {
if(filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE);
mutex_unlock(&dev->mutex);
schedule();
if(signal_pending(current)){
ret = - ERESTARTSYS;
goto out2;
}
mutex_lock(&dev->mutex);
}
if (count > dev->current_len)
count = dev->current_len;
if (copy_to_user(buf, dev->mem, count)) {
ret = -EFAULT;
goto out;
} else {
memcpy(dev->mem, dev->mem + count, dev->current_len - count);
dev->current_len -= count;
printk(KERN_INFO "read %u bytes(s) from %lun", count, dev->current_len);
wake_up_interruptible(&dev->w_wait);
ret = count;
}
out:
mutex_unlock(&dev->mutex);
out2:
remove_wait_queue(&dev->r_wait, &wait);
set_current_state(TASK_RUNNING);
return ret;
}
static ssize_t globalfifo_write(struct file *filp, const char __user * buf, size_t count, loff_t * ppos)
{
int ret = 0;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
mutex_lock(&dev->mutex);
add_wait_queue(&dev->w_wait, &wait);
while(dev->current_len == GLOBALFIFO_SIZE){
if(filp->f_flags & O_NONBLOCK){
ret = -EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE);
mutex_unlock(&dev->mutex);
schedule();
if(signal_pending(current)){
ret = -ERESTARTSYS;
goto out2;
}
mutex_lock(&dev->mutex);
}
if (count > GLOBALFIFO_SIZE - dev->current_len)
count = GLOBALFIFO_SIZE - dev->current_len;
if (copy_from_user(dev->mem + dev->current_len, buf, count)){
ret = -EFAULT;
goto out;
} else {
dev->current_len += count;
printk(KERN_INFO "written %u bytes(s) from %lun", count, dev->current_len);
wake_up_interruptible(&dev->r_wait);
ret = count;
}
out:
mutex_unlock(&dev->mutex);
out2:
remove_wait_queue(&dev->w_wait, &wait);
set_current_state(TASK_RUNNING);
return ret;
}
static loff_t globalfifo_llseek(struct file *filp, loff_t offset, int orig)
{
loff_t ret = 0;
switch (orig) {
case 0: /* 从文件开头位置 seek */
if (offset< 0) {
ret = -EINVAL;
break;
}
if ((unsigned int)offset > GLOBALFIFO_SIZE) {
ret = -EINVAL;
break;
}
filp->f_pos = (unsigned int)offset;
ret = filp->f_pos;
break;
case 1: /* 从文件当前位置开始 seek */
if ((filp->f_pos + offset) > GLOBALFIFO_SIZE) {
ret = -EINVAL;
break;
}
if ((filp->f_pos + offset) < 0) {
ret = -EINVAL;
break;
}
filp->f_pos += offset;
ret = filp->f_pos;
break;
default:
ret = -EINVAL;
break;
}
return ret;
}
static unsigned int globalfifo_poll(struct file *filp, poll_table * wait)
{
unsigned int mask = 0;
struct globalfifo_dev *dev = filp->private_data;
mutex_lock(&dev->mutex);;
poll_wait(filp, &dev->r_wait, wait);
poll_wait(filp, &dev->w_wait, wait);
if (dev->current_len != 0) {
mask |= POLLIN | POLLRDNORM;
}
if (dev->current_len != GLOBALFIFO_SIZE) {
mask |= POLLOUT | POLLWRNORM;
}
mutex_unlock(&dev->mutex);;
return mask;
}
static const struct file_operations globalfifo_fops = {
.owner = THIS_MODULE,
.llseek = globalfifo_llseek,
.read = globalfifo_read,
.write = globalfifo_write,
.unlocked_ioctl = globalfifo_ioctl,
.open = globalfifo_open,
.release = globalfifo_release,
.poll = globalfifo_poll,
};
static void globalfifo_setup_cdev(struct globalfifo_dev *dev, int index)
{
int err, devno = MKDEV(globalfifo_major, index);
cdev_init(&dev->cdev, &globalfifo_fops);
dev->cdev.owner = THIS_MODULE;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_NOTICE "Error %d adding globalfifo%d", err, index);
}
static int __init globalfifo_init(void)
{
int ret;
dev_t devno = MKDEV(globalfifo_major, 0);
if (globalfifo_major)
ret = register_chrdev_region(devno, DEVICE_NUM, "globalfifo");
else {
ret = alloc_chrdev_region(&devno, 0, DEVICE_NUM, "globalfifo");
globalfifo_major = MAJOR(devno);
}
if (ret < 0)
return ret;
globalfifo_devp = kzalloc(sizeof(struct globalfifo_dev) * DEVICE_NUM, GFP_KERNEL);
if (!globalfifo_devp) {
ret = -ENOMEM;
goto fail_malloc;
}
int i = 0;
for (i = 0; i < DEVICE_NUM; i++)
{
mutex_init(&(globalfifo_devp + i)->mutex);
globalfifo_setup_cdev(globalfifo_devp + i, i);
init_waitqueue_head(&(globalfifo_devp + i)->r_wait);
init_waitqueue_head(&(globalfifo_devp + i)->w_wait);
}
return 0;
fail_malloc:
unregister_chrdev_region(devno, DEVICE_NUM);
return ret;
}
module_init(globalfifo_init);
static void __exit globalfifo_exit(void)
{
int i = 0;
for (i = 0; i < DEVICE_NUM; i++)
{
cdev_del(&globalfifo_devp->cdev);
}
kfree(globalfifo_devp);
unregister_chrdev_region(MKDEV(globalfifo_major, 0), DEVICE_NUM);
}
module_exit(globalfifo_exit);
MODULE_AUTHOR("Barry Song <baohua@kernel.org>");
MODULE_LICENSE("GPL v2");
在用户空间中验证globalfifo设备的轮询
#include <stdio.h>
#include <fcntl.h>
#include <sys/select.h>
#define FIFO_CLEAR 0x1
#define BUFFER_LEN 20
void main(void)
{
int fd, num;
char rd_ch[BUFFER_LEN];
fd_set rfds, wfds; /* 读 / 写文件描述符集 */
/* 以非阻塞方式打开 /dev/globalfifo 设备文件 */
fd = open("/dev/globalfifo0", O_RDONLY | O_NONBLOCK);
if (fd != -1 ) {
/* FIFO 清 0 */
if (ioctl(fd, FIFO_CLEAR, 0 ) < 0)
printf("ioctl command failedn");
while ( 1) {
FD_ZERO(&rfds);
FD_ZERO(&wfds);
FD_SET(fd, &rfds);
FD_SET(fd, &wfds);
select(fd + 1 , &rfds, &wfds, NULL, NULL);
/* 数据可获得 */
if (FD_ISSET(fd, &rfds))
printf("Poll monitor:can be readn");
/* 数据可写入 */
if (FD_ISSET(fd, &wfds))
printf("Poll monitor:can be writtenn");
} } else {
printf("Device open failuren");
}
}
总结
阻塞与非阻塞访问是I/O操作的两种不同模式, 前者在暂时不可进行I/O操作时会让进程睡眠, 后者则不然。
在设备驱动中阻塞I/O一般基于等待队列或者基于等待队列的其他Linux内核API来实现, 等待队列可用于同步驱动中事件发生的先后顺序。 使用非阻塞I/O的应用程序也可借助轮询函数来查询设备是否能立即被访问, 用户空间调用select() 、poll() 或者epoll接口, 设备驱动提供poll() 函数。 设备驱动的poll() 本身不会阻塞, 但是与poll() 、 select() 和epoll相关的系统调用则会阻塞地等待至少一个文件描述符集合可访问或超时。
linux设备驱动中的异步通知与异步I/O
信号的接收
在用户程序中, 为了捕获信号, 可以使用signal() 函数来设置对应信号的处理函数:
void (*signal(int signum, void (*handler))(int)))(int);
该函数原型较难理解, 它可以分解为:
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler));
第一个参数指定信号的值, 第二个参数指定针对前面信号值的处理函数, 若为SIG_IGN, 表示忽略该信号; 若为SIG_DFL, 表示采用系统默认方式处理信号; 若为用户自定义的函数, 则信号被捕获到后, 该函数将被执行。
如果signal() 调用成功, 它返回最后一次为信号signum绑定的处理函数的handler值, 失败则返回SIG_ERR。
为了能在用户空间中处理一个设备释放的信号, 它必须完成3项工作。
1) 通过F_SETOWN IO控制命令设置设备文件的拥有者为本进程, 这样从设备驱动发出的信号才能被本进程接收到。
2) 通过F_SETFL IO控制命令设置设备文件以支持FASYNC, 即异步通知模式。
3) 通过signal() 函数连接信号和信号处理函数。
为了使设备支持异步通知机制, 驱动程序中涉及3项工作。
1) 支持F_SETOWN命令, 能在这个控制命令处理中设置filp->f_owner为对应进程ID。 不过此项工作已由内核完成, 设备驱动无须处理。
2) 支持F_SETFL命令的处理, 每当FASYNC标志改变时, 驱动程序中的fasync() 函数将得以执行。 因此, 驱动中应该实现fasync() 函数。
3) 在设备资源可获得时, 调用kill_fasync() 函数激发相应的信号。
支持异步通知的globalfifo驱动
/*
* a simple char device driver: globalfifo without mutex
*
* Copyright (C) 2014 Barry Song (baohua@kernel.org)
*
* Licensed under GPLv2 or later.
*/
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#include <linux/signal.h>
#include <linux/sched/signal.h>
#include <linux/poll.h>
#define GLOBALFIFO_SIZE 0x1000
#define MEM_CLEAR 0x1
#define GLOBALFIFO_MAJOR 230
#define DEVICE_NUM 10
static int globalfifo_major = GLOBALFIFO_MAJOR;
module_param(globalfifo_major, int, S_IRUGO);
struct globalfifo_dev {
struct cdev cdev;
unsigned int current_len;
unsigned char mem[GLOBALFIFO_SIZE];
struct mutex mutex;
wait_queue_head_t r_wait;
wait_queue_head_t w_wait;
struct fasync_struct *async_queue;
};
struct globalfifo_dev *globalfifo_devp;
static int globalfifo_fasync(int fd, struct file *filp, int mode)
{
struct globalfifo_dev *dev = filp->private_data;
return fasync_helper(fd, filp, mode, &dev->async_queue);
}
static int globalfifo_open(struct inode *inode, struct file *filp)
{
struct globalfifo_dev *dev = container_of(inode->i_cdev, struct globalfifo_dev, cdev);
filp->private_data = dev;
return 0;
}
static int globalfifo_release(struct inode *inode, struct file *filp)
{
globalfifo_fasync(-1, filp, 0);
return 0;
}
static long globalfifo_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
struct globalfifo_dev *dev = filp->private_data;
switch (cmd) {
case MEM_CLEAR:
mutex_lock(&dev->mutex);
memset(dev->mem, 0, GLOBALFIFO_SIZE);
mutex_unlock(&dev->mutex);
printk(KERN_INFO "globalfifo is set to zeron");
break;
default:
return -EINVAL;
}
return 0;
}
static ssize_t globalfifo_read(struct file *filp, char __user * buf, size_t count,loff_t * ppos)
{
int ret = 0;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
mutex_lock(&dev->mutex);
add_wait_queue(&dev->r_wait, &wait);
while(dev->current_len == 0) {
if(filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE);
mutex_unlock(&dev->mutex);
schedule();
if(signal_pending(current)){
ret = - ERESTARTSYS;
goto out2;
}
mutex_lock(&dev->mutex);
}
if (count > dev->current_len)
count = dev->current_len;
if (copy_to_user(buf, dev->mem, count)) {
ret = -EFAULT;
goto out;
} else {
memcpy(dev->mem, dev->mem + count, dev->current_len - count);
dev->current_len -= count;
printk(KERN_INFO "read %u bytes(s) from %lun", count, dev->current_len);
wake_up_interruptible(&dev->w_wait);
ret = count;
}
out:
mutex_unlock(&dev->mutex);
out2:
remove_wait_queue(&dev->r_wait, &wait);
set_current_state(TASK_RUNNING);
return ret;
}
static ssize_t globalfifo_write(struct file *filp, const char __user * buf, size_t count, loff_t * ppos)
{
int ret = 0;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
mutex_lock(&dev->mutex);
add_wait_queue(&dev->w_wait, &wait);
while(dev->current_len == GLOBALFIFO_SIZE){
if(filp->f_flags & O_NONBLOCK){
ret = -EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE);
mutex_unlock(&dev->mutex);
schedule();
if(signal_pending(current)){
ret = -ERESTARTSYS;
goto out2;
}
mutex_lock(&dev->mutex);
}
if (count > GLOBALFIFO_SIZE - dev->current_len)
count = GLOBALFIFO_SIZE - dev->current_len;
if (copy_from_user(dev->mem + dev->current_len, buf, count)){
ret = -EFAULT;
goto out;
} else {
dev->current_len += count;
printk(KERN_INFO "written %u bytes(s) from %lun", count, dev->current_len);
wake_up_interruptible(&dev->r_wait);
if(dev->async_queue)
{
kill_fasync(&dev->async_queue, SIGIO, POLL_IN);
printk(KERN_DEBUG "%s kill SIGIOn", __func__);
}
ret = count;
}
out:
mutex_unlock(&dev->mutex);
out2:
remove_wait_queue(&dev->w_wait, &wait);
set_current_state(TASK_RUNNING);
return ret;
}
static loff_t globalfifo_llseek(struct file *filp, loff_t offset, int orig)
{
loff_t ret = 0;
switch (orig) {
case 0: /* 从文件开头位置 seek */
if (offset< 0) {
ret = -EINVAL;
break;
}
if ((unsigned int)offset > GLOBALFIFO_SIZE) {
ret = -EINVAL;
break;
}
filp->f_pos = (unsigned int)offset;
ret = filp->f_pos;
break;
case 1: /* 从文件当前位置开始 seek */
if ((filp->f_pos + offset) > GLOBALFIFO_SIZE) {
ret = -EINVAL;
break;
}
if ((filp->f_pos + offset) < 0) {
ret = -EINVAL;
break;
}
filp->f_pos += offset;
ret = filp->f_pos;
break;
default:
ret = -EINVAL;
break;
}
return ret;
}
static unsigned int globalfifo_poll(struct file *filp, poll_table * wait)
{
unsigned int mask = 0;
struct globalfifo_dev *dev = filp->private_data;
mutex_lock(&dev->mutex);;
poll_wait(filp, &dev->r_wait, wait);
poll_wait(filp, &dev->w_wait, wait);
if (dev->current_len != 0) {
mask |= POLLIN | POLLRDNORM;
}
if (dev->current_len != GLOBALFIFO_SIZE) {
mask |= POLLOUT | POLLWRNORM;
}
mutex_unlock(&dev->mutex);;
return mask;
}
static const struct file_operations globalfifo_fops = {
.owner = THIS_MODULE,
.llseek = globalfifo_llseek,
.read = globalfifo_read,
.write = globalfifo_write,
.unlocked_ioctl = globalfifo_ioctl,
.open = globalfifo_open,
.release = globalfifo_release,
.poll = globalfifo_poll,
};
static void globalfifo_setup_cdev(struct globalfifo_dev *dev, int index)
{
int err, devno = MKDEV(globalfifo_major, index);
cdev_init(&dev->cdev, &globalfifo_fops);
dev->cdev.owner = THIS_MODULE;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_NOTICE "Error %d adding globalfifo%d", err, index);
}
static int __init globalfifo_init(void)
{
int ret;
dev_t devno = MKDEV(globalfifo_major, 0);
if (globalfifo_major)
ret = register_chrdev_region(devno, DEVICE_NUM, "globalfifo");
else {
ret = alloc_chrdev_region(&devno, 0, DEVICE_NUM, "globalfifo");
globalfifo_major = MAJOR(devno);
}
if (ret < 0)
return ret;
globalfifo_devp = kzalloc(sizeof(struct globalfifo_dev) * DEVICE_NUM, GFP_KERNEL);
if (!globalfifo_devp) {
ret = -ENOMEM;
goto fail_malloc;
}
int i = 0;
for (i = 0; i < DEVICE_NUM; i++)
{
mutex_init(&(globalfifo_devp + i)->mutex);
globalfifo_setup_cdev(globalfifo_devp + i, i);
init_waitqueue_head(&(globalfifo_devp + i)->r_wait);
init_waitqueue_head(&(globalfifo_devp + i)->w_wait);
}
return 0;
fail_malloc:
unregister_chrdev_region(devno, DEVICE_NUM);
return ret;
}
module_init(globalfifo_init);
static void __exit globalfifo_exit(void)
{
int i = 0;
for (i = 0; i < DEVICE_NUM; i++)
{
cdev_del(&globalfifo_devp->cdev);
}
kfree(globalfifo_devp);
unregister_chrdev_region(MKDEV(globalfifo_major, 0), DEVICE_NUM);
}
module_exit(globalfifo_exit);
MODULE_AUTHOR("Barry Song <baohua@kernel.org>");
MODULE_LICENSE("GPL v2");
在用户空间中验证globalfifo的异步通知
#include <stdio.h>
#include <fcntl.h>
#include <sys/select.h>
#include <sys/types.h>
#include <signal.h>
static void signalio_handler(int signum)
{
printf("receive a signal from globalfifo,signalnum:%dn", signum);
}
void main(void)
{
int fd, oflags;
fd = open("/dev/globalfifo0", O_RDWR, S_IRUSR | S_IWUSR);
if (fd != -1) {
signal(SIGIO, signalio_handler);
fcntl(fd, F_SETOWN, getpid());
oflags = fcntl(fd, F_GETFL);
fcntl(fd, F_SETFL, oflags | FASYNC);
while (1) {
sleep(100);
}
} else {
printf("device open failuren");
}
}
实测,并不像书里说的可以有程序打印,观察dmesglog是内核没有释放信号,具体原因待查
更新:原因是,没有注册fasync函数,即:
static const struct file_operations globalfifo_fops = {
.owner = THIS_MODULE,
.llseek = globalfifo_llseek,
.read = globalfifo_read,
.write = globalfifo_write,
.unlocked_ioctl = globalfifo_ioctl,
.open = globalfifo_open,
.release = globalfifo_release,
.poll = globalfifo_poll,
};
应为:
static const struct file_operations globalfifo_fops = {
.owner = THIS_MODULE,
.llseek = globalfifo_llseek,
.read = globalfifo_read,
.write = globalfifo_write,
.unlocked_ioctl = globalfifo_ioctl,
.open = globalfifo_open,
.release = globalfifo_release,
.poll = globalfifo_poll,
.fasync = globalfifo_fasync,
};
修改后即可复现书中现象。
linux异步I/O
AIO概念与GNU C库AIO
Linux的AIO有多种实现, 其中一种实现是在用户空间的glibc库中实现的, 它本质上是借用了多线程模型, 用开启新的线程以同步的方法来做I/O, 新的AIO辅助线程与发起AIO的线程以pthread_cond_signal() 的形式进行线程间的同步。 glibc的AIO主要包括如下函数。
int aio_read( struct aiocb *aiocbp );
int aio_write( struct aiocb *aiocbp );
int aio_error( struct aiocb *aiocbp );
ssize_t aio_return( struct aiocb *aiocbp );
int aio_suspend( const struct aiocb *const cblist[],int n, const struct timespec *timeout );
int aio_cancel(int fd, struct aiocb *aiocbp);
int lio_listio( int mode, struct aiocb *list[], int nent, struct sigevent *sig );
Linux内核AIO与libaio
在用户空间中, 我们一般要结合libaio来进行内核AIO的系统调用。 内核AIO提供的系统调用主要包括:
int io_setup(int maxevents, io_context_t *ctxp);
int io_destroy(io_context_t ctx);
int io_submit(io_context_t ctx, long nr, struct iocb *ios[]);
int io_cancel(io_context_t ctx, struct iocb *iocb, struct io_event *evt);
int io_getevents(io_context_t ctx_id, long min_nr, long nr, struct io_event *events, struct timespec *timeout);
void io_set_callback(struct iocb *iocb, io_callback_t cb);
void io_prep_pwrite(struct iocb *iocb, int fd, void *buf, size_t count, long long offset);
void io_prep_pread(struct iocb *iocb, int fd, void *buf, size_t count, long long offset);
void io_prep_pwritev(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt, long long offset);
void io_prep_preadv(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt, long long offset);
AIO的读写请求都用io_submit() 下发。 下发前通过io_prep_pwrite() 和io_prep_pread() 生成iocb的结构体,作为io_submit() 的参数。 这个结构体指定了读写类型、 起始地址、 长度和设备标志符等信息。 读写请求下发之后, 使用io_getevents() 函数等待I/O完成事件。 io_set_callback() 则可设置一个AIO完成的回调函数。
AIO与设备驱动
AIO一般由内核空间的通用代码处理, 对于块设备和网络设备而言, 一般在Linux核心层的代码已经解决。 字符设备驱动一般不需要实现AIO支持。 Linux内核中对字符设备驱动实现AIO的特例包括drivers/char/mem.c里实现的null、 zero等, 由于zero这样的虚拟设备其实也不存在在要去读的时候读不到东西的情况, 所以aio_read_zero()本质上也不包含异步操作。
总结
使用信号可以实现设备驱动与用户程序之间的异步通知, 总体而言, 设备驱动和用户空间要分别完成3项对应的工作, 用户空间设置文件的拥有者、 FASYNC标志及捕获信号, 内核空间响应对文件的拥有者、 FASYNC标志的设置并在资源可获得时释放信号。
Linux 2.6以后的内核包含对AIO的支持, 它为用户空间提供了统一的异步I/O接口。 另外, glibc也提供了一个不依赖于内核的用户空间的AIO支持。
中断与时钟
中断与定时器
linux中断处理程序架构
Linux将中断处理程序分解为两个半部: 顶半部(Top Half) 和底半部(Bottom Half) 。
顶半部用于完成尽量少的比较紧急的功能, 它往往只是简单地读取寄存器中的中断状态, 并在清除中断标志后就进行“登记中断”的工作。 “登记中断”意味着将底半部处理程序挂到该设备的底半部执行队列中去。 这样, 顶半部执行的速度就会很快, 从而可以服务更多的中断请求。
现在, 中断处理工作的重心就落在了底半部的头上, 需用它来完成中断事件的绝大多数任务。 底半部几乎做了中断处理程序所有的事情, 而且可以被新的中断打断, 这也是底半部和顶半部的最大不同, 因为顶半部往往被设计成不可中断。 底半部相对来说并不是非常紧急的, 而且相对比较耗时, 不在硬件中断服务程序中执行。
尽管顶半部、 底半部的结合能够改善系统的响应能力, 但是, 僵化地认为Linux设备驱动中的中断处理一定要分两个半部则是不对的。 如果中断要处理的工作本身很少, 则完全可以直接在顶半部全部完成。
linux中断编程
申请和释放中断
使能和屏蔽中断
底半部机制
Linux实现底半部的机制主要有tasklet、 工作队列、 软中断和线程化irq。
tasklet的使用较简单, 它的执行上下文是软中断, 执行时机通常是顶半部返回的时候。
使用tasklet作为底半部处理中断的设备驱动程序模板如代码清单10.2所示(仅包含与中断相关的部分) 。
代码清单10.2 tasklet使用模板
/* 定义 tasklet 和底半部函数并将它们关联 */
void xxx_do_tasklet(unsigned long);
DECLARE_TASKLET(xxx_tasklet, xxx_do_tasklet, 0);
/* 中断处理底半部 */
void xxx_do_tasklet(unsigned long)
{
...
}
/* 中断处理顶半部 */
irqreturn_t xxx_interrupt(int irq, void *dev_id)
{
...
tasklet_schedule(&xxx_tasklet);
...
}
/* 设备驱动模块加载函数 */
int __init xxx_init(void)
{
...
/* 申请中断 */
result = request_irq(xxx_irq, xxx_interrupt,
0, "xxx", NULL);
...
return IRQ_HANDLED;
}
/* 设备驱动模块卸载函数 */
void __exit xxx_exit(void)
{
...
/* 释放中断 */
free_irq(xxx_irq, xxx_interrupt);
...
}
上述程序在模块加载函数中申请中断(第24~25行) , 并在模块卸载函数中释放它(第35行) 。 对应于xxx_irq的中断处理程序被设置为xxx_interrupt() 函数, 在这个函数中, 第15行的tasklet_schedule(&xxx_tasklet) 调度被定义的tasklet函数xxx_do_tasklet() 在适当的时候执行。
工作队列的使用方法和tasklet非常相似, 但是工作队列的执行上下文是内核线程, 因此可以调度和睡眠。
软中断(Softirq) 也是一种传统的底半部处理机制, 它的执行时机通常是顶半部返回的时候, tasklet是基于软中断实现的, 因此也运行于软中断上下文。
软中断和tasklet运行于软中断上下文, 仍然属于原子上下文的一种, 而工作队列则运行于进程上下文。 因此, 在软中断和tasklet处理函数中不允许睡眠, 而在工作队列处理函数中允许睡眠。
硬中断、 软中断和信号的区别: 硬中断是外部设备对CPU的中断, 软中断是中断底半部的一种处理机制, 而信号则是由内核(或其他进程) 对某个进程的中断。
在涉及系统调用的场合, 人们也常说通过软中断(例如ARM为swi) 陷入内核, 此时软中断的概念是指由软件指令引发的中断, 和我们这个地方说的softirq是两个完全不同的概念, 一个是software, 一个是soft。
需要特别说明的是, 软中断以及基于软中断的tasklet如果在某段时间内大量出现的话, 内核会把后续软中断放入ksoftirqd内核线程中执行。 总的来说, 中断优先级高于软中断, 软中断又高于任何一个线程。 软中断适度线程化, 可以缓解高负载情况下系统的响应。
中断共享
多个设备共享一根硬件中断线的情况在实际的硬件系统中广泛存在, Linux支持这种中断共享。 下面是中断共享的使用方法。
1) 共享中断的多个设备在申请中断时, 都应该使用IRQF_SHARED标志, 而且一个设备以IRQF_SHARED申请某中断成功的前提是该中断未被申请, 或该中断虽然被申请了, 但是之前申请该中断的所有设备也都以IRQF_SHARED标志申请该中断。
2) 尽管内核模块可访问的全局地址都可以作为request_irq(…, void*dev_id) 的最后一个参数dev_id, 但是设备结构体指针显然是可传入的最佳参数。
3) 在中断到来时, 会遍历执行共享此中断的所有中断处理程序, 直到某一个函数返回IRQ_HANDLED。 在中断处理程序顶半部中, 应根据硬件寄存器中的信息比照传入的dev_id参数迅速地判断是否为本设备的中断, 若不是, 应迅速返回IRQ_NONE
内核定时器
内核定时器编程
Linux内核所提供的用于操作定时器的数据结构和函数如下:
- 在Linux内核中, timer_list结构体的一个实例对应一个定时器
timer_list结构体
1struct timer_list {
2 /*
3 * All fields that change during normal runtime grouped to the
4 * same cacheline
5 */
6 struct list_head entry;
7 unsigned long expires;
8 struct tvec_base *base;
9
10 void (*function)(unsigned long);
11 unsigned long data;
12
13 int slack;
14
15#ifdef CONFIG_TIMER_STATS
16 int start_pid;
17 void *start_site;
18 char start_comm[16];
19#endif
20#ifdef CONFIG_LOCKDEP
21 struct lockdep_map lockdep_map;
22#endif
23};
当定时器期满后, 其中第10行的function() 成员将被执行, 而第11行的data成员则是传入其中的参数, 第7行的expires则是定时器到期的时间(jiffies) 。
- init_timer是一个宏, 它的原型等价于:
void init_timer(struct timer_list * timer);
TIMER_INITIALIZER(_function, _expires, _data) 宏用于赋值定时器结构体的function、 expires、 data和base成员, 这个宏等价于:
#define TIMER_INITIALIZER(_function, _expires, _data) {
.entry = { .prev = TIMER_ENTRY_STATIC },
.function = (_function),
.expires = (_expires),
.data = (_data),
.base = &boot_tvec_bases,
}
DEFINE_TIMER(_name, _function, _expires, _data) 宏是定义并初始化定时器成员的“快捷方式”, 这个宏定义为:
#define DEFINE_TIMER(_name, _function, _expires, _data)
struct timer_list _name =
TIMER_INITIALIZER(_function, _expires, _data)
此外, setup_timer() 也可用于初始化定时器并赋值其成员, 其源代码为:
#define __setup_timer(_timer, _fn, _data, _flags)
do {
__init_timer((_timer), (_flags));
(_timer)->function = (_fn); (_timer)->data = (_data);
} while (0)
- 用于注册内核定时器, 将定时器加入到内核动态定时器链表中。
void add_timer(struct timer_list * timer);
- 用于删除定时器。
del_timer_sync() 是del_timer() 的同步版, 在删除一个定时器时需等待其被处理完, 因此该函数的调用不能发
生在中断上下文中。
int del_timer(struct timer_list * timer);
- 用于修改定时器的到期时间, 在新的被传入的expires到来后才会执行定时器函数
int mod_timer(struct timer_list *timer, unsigned long expires);
定时器的到期时间往往是在目前jiffies的基础上添加一个时延,在定时器处理函数中, 在完成相应的工作后, 往往会延后expires并将定时器再次添加到内核定时器链表中, 以便定时器能再次被触发
此外, Linux内核支持tickless和NO_HZ模式后, 内核也包含对hrtimer(高精度定时器) 的支持, 它可以支持到微秒级别的精度。
内核中延迟的工作delayed_work
对于周期性的任务, 除了定时器以外, 在Linux内核中还可以利用一套封装得很好的快捷机制, 其本质是利用工
作队列和定时器实现, 这套快捷机制就是delayed_work, delayed_work结构体的定义如代码清单10.12所示。
代码清单10.12
delayed_work结构体
1struct delayed_work {
2 struct work_struct work;
3 struct timer_list timer;
4 5
/* target workqueue and CPU ->timer uses to queue ->work */
6 struct workqueue_struct *wq;
7 int cpu;
8};
我们可以通过如下函数调度一个delayed_work在指定的延时后执行:
int schedule_delayed_work(struct delayed_work *work, unsigned long delay);
当指定的delay到来时, delayed_work结构体中的work成员work_func_t类型成员func() 会被执行。 work_func_t类型定义为:
typedef void (*work_func_t)(struct work_struct *work);
其中, delay参数的单位是jiffies, 因此一种常见的用法如下:
schedule_delayed_work(&work, msecs_to_jiffies(poll_interval));
msecs_to_jiffies() 用于将毫秒转化为jiffies。
如果要周期性地执行任务, 通常会在delayed_work的工作函数中再次调用schedule_delayed_work() , 周而复始。
如下函数用来取消delayed_work:
int cancel_delayed_work(struct delayed_work *work);
int cancel_delayed_work_sync(struct delayed_work *work);
实例:秒字符设备
遇到问题:
- linux 4.15内核之后,移除了init_timer函数,使用timer_setup函数代替;
static int second_open(struct inode *inode, struct file *filp)
{
//if linux version < 4.15
//init_timer(&second_devp->s_timer);
//second_devp->s_timer.function = &second_timer_handler;
//else
timer_setup(&second_devp->s_timer, second_timer_handler, 0);
second_devp->s_timer.expires = jiffies + HZ;
atomic_set(&second_devp->counter, 0); /* 初始化秒计数为 0 */
add_timer(&second_devp->s_timer);
return 0;
}
- insmod xbw_second.ko时,提示Device or resource busy
是设备号冲突导致,改为231,重新编译,正常insmod
处理方法:
1.输入$cat /proc/devices 查看驱动的设备号
2.选择一个不冲突的设备号进行编译
#define SECOND_MAJOR 231
实测可用代码:
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/mm.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#define SECOND_MAJOR 231
static int second_major = SECOND_MAJOR;
module_param(second_major, int, S_IRUGO);
struct second_dev {
struct cdev cdev;
atomic_t counter;
struct timer_list s_timer;
};
static struct second_dev *second_devp;
static void second_timer_handler(unsigned long arg)
{
mod_timer(&second_devp->s_timer, jiffies + HZ); /* 触发下一次定时 */
atomic_inc(&second_devp->counter); /* 增加秒计数 */
printk(KERN_INFO "current jiffies is %ldn", jiffies);
}
static int second_open(struct inode *inode, struct file *filp)
{
//if linux version < 4.15
//init_timer(&second_devp->s_timer);
//second_devp->s_timer.function = &second_timer_handler;
//else
timer_setup(&second_devp->s_timer, second_timer_handler, 0);
second_devp->s_timer.expires = jiffies + HZ;
add_timer(&second_devp->s_timer);
atomic_set(&second_devp->counter, 0); /* 初始化秒计数为 0 */
return 0;
}
static int second_release(struct inode *inode, struct file *filp)
{
del_timer(&second_devp->s_timer);
return 0;
}
static ssize_t second_read(struct file *filp, char __user * buf, size_t count, loff_t * ppos)
{
int counter;
counter = atomic_read(&second_devp->counter);
if (put_user(counter, (int *)buf))/* 复制 counter 到 userspace */
return -EFAULT;
else
return sizeof(unsigned int);
}
static const struct file_operations second_fops = {
.owner = THIS_MODULE,
.open = second_open,
.release = second_release,
.read = second_read,
};
static void second_setup_cdev(struct second_dev *dev, int index)
{
int err, devno = MKDEV(second_major, index);
cdev_init(&dev->cdev, &second_fops);
dev->cdev.owner = THIS_MODULE;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_ERR "Failed to add second devicen");
}
static int __init second_init(void)
{
int ret;
dev_t devno = MKDEV(second_major, 0);
if (second_major)
ret = register_chrdev_region(devno, 1, "second");
else {
ret = alloc_chrdev_region(&devno, 0, 1, "second");
second_major = MAJOR(devno);
}
if (ret < 0)
return ret;
second_devp = kzalloc(sizeof(*second_devp), GFP_KERNEL);
if (!second_devp) {
ret = -ENOMEM;
goto fail_malloc;
}
second_setup_cdev(second_devp, 0);
return 0;
fail_malloc:
unregister_chrdev_region(devno, 1);
return ret;
}
module_init(second_init);
static void __exit second_exit(void)
{
cdev_del(&second_devp->cdev);
kfree(second_devp);
unregister_chrdev_region(MKDEV(second_major, 0), 1);
}
module_exit(second_exit);
MODULE_AUTHOR("Barry Song <21cnbao@gmail.com>");
MODULE_LICENSE("GPL v2");
用户空间测试程序:
#include <stdio.h>
#include <fcntl.h>
#include <sys/select.h>
main()
{
int fd;
int counter = 0;
int old_counter = 0;
/* 打开 /dev/second 设备文件 */
fd = open("/dev/second", O_RDONLY);
if (fd != - 1) {
while (1) {
read(fd,&counter, sizeof(unsigned int));/* 读目前经历的秒数 */
if(counter!=old_counter) {
printf("seconds after open /dev/second :%dn",counter);
old_counter = counter;
}
}
} else {
printf("Device open failuren");
}
}
测试步骤:
- make 得到xxx.ko模块文件
- sudo insmod xxx.ko (可以通过rmmod删除insmod安装的模块的)
- sudo mknod /dev/second c 231(代码中的设备号) 0 (可以通过sudo rm命令删除mknod创建的设备文件)
- 运行用户空间测试程序,现象与书描述一致
内核延时
短延时
Linux内核中提供了下列3个函数以分别进行纳秒、 微秒和毫秒延迟:
void ndelay(unsigned long nsecs);
void udelay(unsigned long usecs);
void mdelay(unsigned long msecs);
上述延迟的实现原理本质上是忙等待
对于毫秒级以上的时延, 内核提供了下述函数:
void msleep(unsigned int millisecs);
unsigned long msleep_interruptible(unsigned int millisecs);
void ssleep(unsigned int seconds);
上述函数将使得调用它的进程睡眠参数指定的时间为millisecs, msleep() 、 ssleep() 不能被打断, 而msleep_interruptible() 则可以被打断。
受系统Hz以及进程调度的影响, msleep() 类似函数的精度是有限的。
总结
Linux的中断处理分为两个半部, 顶半部处理紧急的硬件操作, 底半部处理不紧急的耗时操作。 tasklet和工作队列都是调度中断底半部的良好机制, tasklet基于软中断实现。 内核定时器也依靠软中断实现。
内核中的延时可以采用忙等待或睡眠等待, 为了充分利用CPU资源, 使系统有更好的吞吐性能, 在对延迟时间的要求并不是很精确的情况下, 睡眠等待通常是值得推荐的, 而ndelay() 、 udelay() 忙等待机制在驱动中通常是为了配合硬件上的短时延迟要求
内存与I/O访问
CPU与内存、I/O
为了理解基本的MMU操作原理, 需先明晰几个概念。
1) TLB(Translation Lookaside Buffer) : 即转换旁路缓存, TLB是MMU的核心部件, 它缓存少量的虚拟地址与物理地址的转换关系, 是转换表的Cache, 因此也经常被称为“快表”。
2) TTW(Translation Table walk) : 即转换表漫游, 当TLB中没有缓冲对应的地址转换关系时, 需要通过对内存中转换表(大多数处理器的转换表为多级页表) 的访问来获得虚拟地址和物理地址的对应关系。 TTW成功后, 结果应写入TLB中。
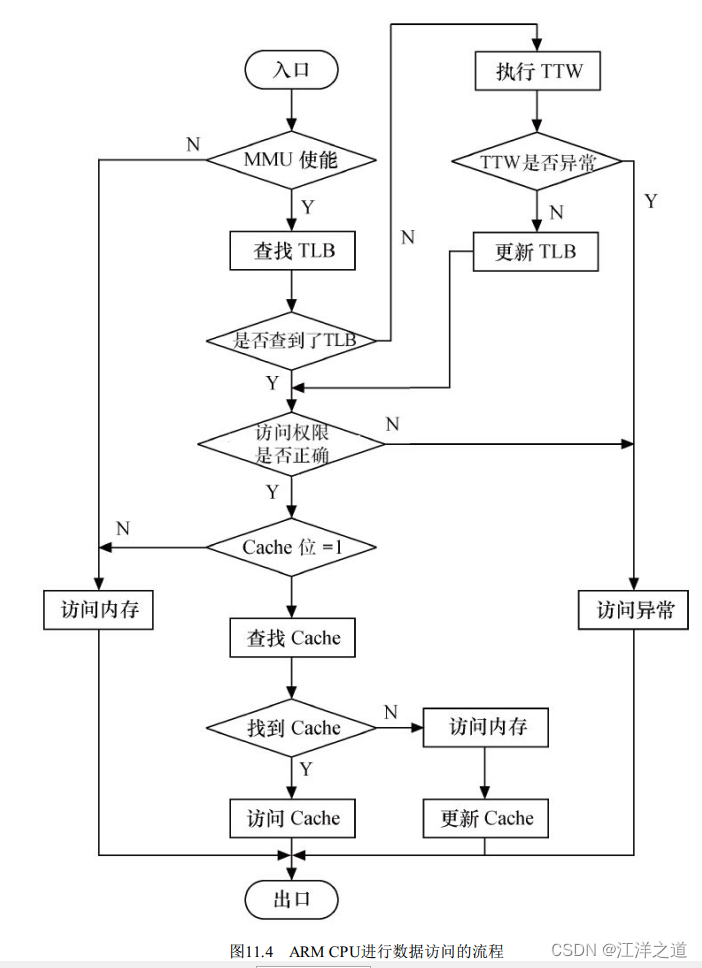
Linux内存管理
对于包含MMU的处理器而言, Linux系统提供了复杂的存储管理系统, 使得进程所能访问的内存达到4GB。
在Linux系统中, 进程的4GB内存空间被分为两个部分——用户空间与内核空间。 用户空间的地址一般分布为0~3GB(即PAGE_OFFSET, 在0x86中它等于0xC0000000) , 这样, 剩下的3~4GB为内核空间。 用户进程通常只能访问用户空间的虚拟地址, 不能访问内核空间的虚拟地址。 用户进程只有通过系统调用(代表用户进程在内核态执行) 等方式才可以访问到内核空间。
对于32位的x86而言, 在3~4GB之间的内核空间中, 从低地址到高地址依次为: 物理内存映射区→隔离带→vmalloc虚拟内存分配器区→隔离带→高端内存映射区→专用页面映射区→保留区。
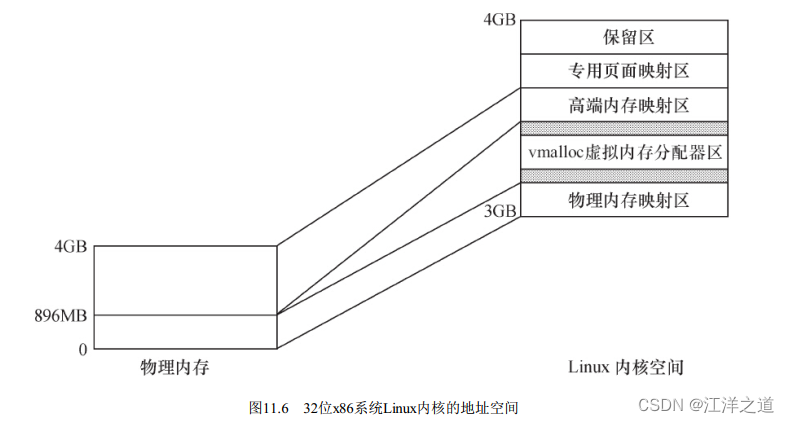
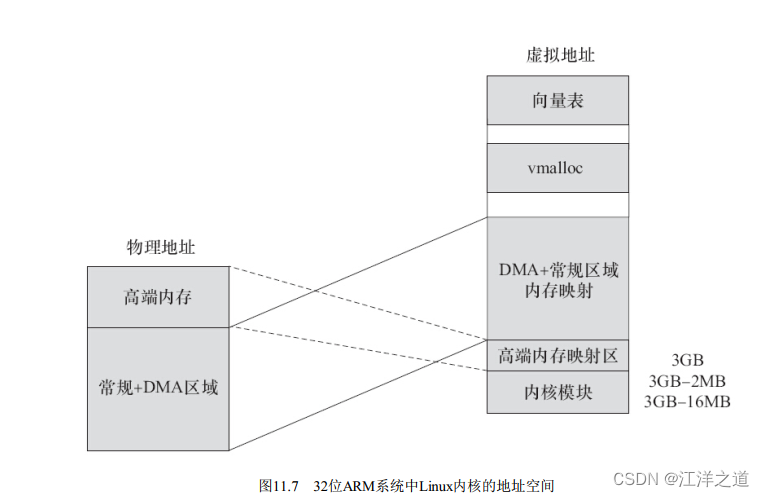
对于内核物理内存映射区的虚拟内存(即从DMA和常规区域映射过来的) , 使用virt_to_phys() 可以实现内核虚拟地址转化为物理地址。 与之对应的函数为phys_to_virt() , 它将物理地址转化为内核虚拟地址。
注意: 上述virt_to_phys() 和phys_to_virt() 方法仅适用于DMA和常规区域, 高端内存的虚拟地址与物理地址之间不存在如此简单的换算关系
内存存取
由于用户空间C库的malloc算法实际上具备一个二次管理能力, 所以并不是每次申请和释放内存都一定伴随着对内核的系统调用。
内核空间内存动态申请
在Linux内核空间中申请内存涉及的函数主要包括kmalloc() 、__get_free_pages() 和vmalloc() 等。
kmalloc() 和__get_free_pages() (及其类似函数) 申请的内存位于DMA和常规区域的映射区(?kmalloc()函数的标志中包含申请高端内存以及用户空间内存,这点待确认,推测该函数申请的内存都是实际存在且连续的), 而且在物理上也是连续的, 它们与真实的物理地址只有一个固定的偏移, 因此存在较简单的转换关系。 而vmalloc() 在虚拟内存空间给出一块连续的内存区, 实质上, 这片连续的虚拟内存在物理内存中并不一定连续, 而vmalloc() 申请的虚拟内存和物理内存之间也没有简单的换算关系。
vmalloc() 一般只为存在于软件中(没有对应的硬件意义) 的较大的顺序缓冲区分配内存, vmalloc() 远大于__get_free_pages() 的开销, 为了完成vmalloc() , 新的页表项需要被建立。 因此, 只是调用vmalloc() 来分配少量的内存(如1页以内的内存) 是不妥的
vmalloc() 不能用在原子上下文中, 因为它的内部实现使用了标志为GFP_KERNEL的kmalloc() (可能导致休眠和任务切换)。
slab是建立在buddy算法之上的, 它从buddy算法拿到2n页面后再次进行二次管理, 这一点和用户空间的C库很像。 slab申请的内存以及基于slab的kmalloc() 申请的内存, 与物理内存之间也是一个简单的线性偏移。
除了slab以外, 在Linux内核中还包含对内存池的支持, 内存池技术也是一种非常经典的用于分配大量小对象的后备缓存技术。
设备I/O端口和I/O内存的访问
设备通常会提供一组寄存器来控制设备、 读写设备和获取设备状态, 即控制寄存器、 数据寄存器和状态寄存器。 这些寄存器可能位于I/O空间中, 也可能位于内存空间中。 当位于I/O空间时, 通常被称为I/O端口; 当位于内存空间时, 对应的内存空间被称为I/O内存。
在内核中访问I/O内存(通常是芯片内部的各个I 2 C、 SPI、 USB等控制器的寄存器或者外部内存总线上的设备)之前, 需首先使用ioremap() 函数将设备所处的物理地址映射到虚拟地址上。
ioremap() 返回一个特殊的虚拟地址, 该地址可用来存取特定的物理地址范围, 这个虚拟地址位于vmalloc映射区域。 通过ioremap() 获得的虚拟地址应该被iounmap() 函数释放
在设备的物理地址(一般都是寄存器) 被映射到虚拟地址之后, 尽管可以直接通过指针访问这些地址, 但是Linux内核推荐用一组标准的API来完成设备内存映射的虚拟地址的读写。
I/O端口访问的一种途径是直接使用I/O端口操作函数: 在设备打开或驱动模块被加载时申请I/O端口区域, 之后使用inb() 、 outb() 等进行端口访问, 最后, 在设备关闭或驱动被卸载时释放I/O端口范围。 整个流程如图11.10所示。
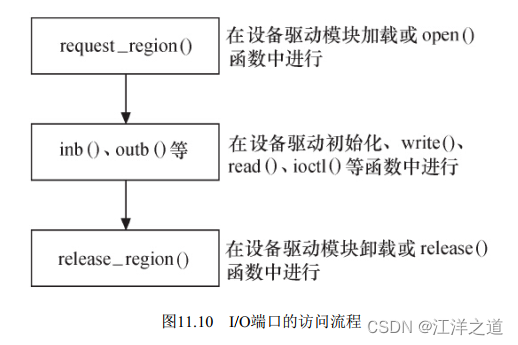
I/O内存的访问步骤如图11.11所示, 首先是调用request_mem_region() 申请资源, 接着将寄存器地址通过ioremap() 映射到内核空间虚拟地址, 之后就可以通过Linux设备访问编程接口访问这些设备的寄存器了。 访问完成后, 应对ioremap() 申请的虚拟地址进行释放, 并释放release_mem_region() 申请的I/O内存资源。
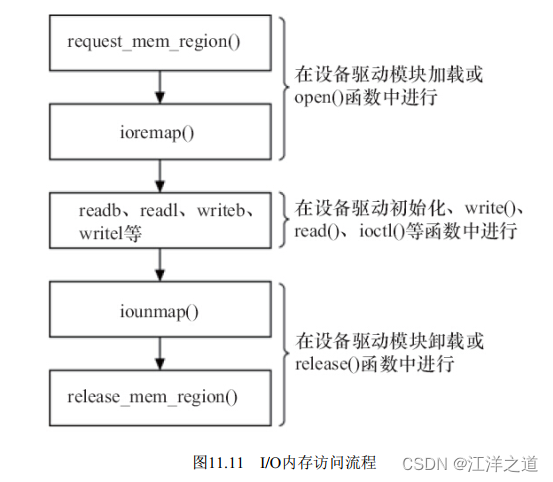
将设备地址映射到用户空间
一般情况下, 用户空间是不可能也不应该直接访问设备的, 但是, 设备驱动程序中可实现mmap() 函数, 这个函数可使得用户空间能直接访问设备的物理地址。 实际上, mmap() 实现了这样的一个映射过程: 它将用户空间的一段内存与设备内存关联, 当用户访问用户空间的这段地址范围时, 实际上会转化为对设备的访问。
这种能力对于显示适配器一类的设备非常有意义, 如果用户空间可直接通过内存映射访问显存的话, 屏幕帧的各点像素将不再需要一个从用户空间到内核空间的复制的过程。
这段较复杂,实用性在于音视频领域,待仔细研究
I/O内存静态映射
在将Linux移植到目标电路板的过程中, 有得会建立外设I/O内存物理地址到虚拟地址的静态映射, 这个映射通过在与电路板对应的map_desc结构体数组中添加新的成员来完成
DMA
所谓Cache数据与内存数据的不一致性, 是指在采用Cache的系统中, 同样一个数据可能既存在于Cache中, 也存在于主存中, Cache与主存中的数据一样则具有一致性, 数据若不一样则具有不一致性。
对于带MMU功能的ARM处理器, 在开启MMU之前, 需要先置Cache无效, 对于TLB, 也是如此
dma_alloc_coherent( ) 申请一片DMA缓冲区, 以进行地址映射并保证该缓冲区的Cache一致性。
并不是所有的DMA缓冲区都是驱动申请的, 如果是驱动申请的, 用一致性DMA缓冲区自然最方便, 这直接考虑了Cache一致性问题。 但是, 在许多情况下, 缓冲区来自内核的较上层( 如网卡驱动中的网络报文、 块设备驱动中要写入设备的数据等) , 上层很可能用普通的kmalloc( ) 、 __get_free_pages( ) 等方法申请, 这时候就要使用流式DMA映射。 流式DMA缓冲区使用的一般步骤如下。
1) 进行流式DMA映射。
2) 执行DMA操作。
3) 进行流式DMA去映射。
流式DMA映射操作在本质上大多就是进行Cache的使无效或清除操作, 以解决Cache一致性问题。
Linux内核目前推荐使用dmaengine的驱动架构来编写DMA控制器的驱动, 同时外设的驱动使用标准的dmaengineAPI进行DMA的准备、 发起和完成时的回调工作。
总结
外设可处于CPU的内存空间和I/O空间, 除x86外, 嵌入式处理器一般只存在内存空间。 在Linux系统中, 为I/O内存和I/O端口的访问提高了一套统一的方法, 访问流程一般为“申请资源→映射→访问→去映射→释放资源”。
对于有MMU的处理器而言, Linux系统的内部布局比较复杂, 可直接映射的物理内存称为常规内存, 超出部分为高端内存。 kmalloc() 和__get_free_pages() 申请的内存在物理上连续, 而vmalloc() 申请的内存在物理上不连续。
DMA操作可能导致Cache的不一致性问题, 因此, 对于DMA缓冲, 应该使用dma_alloc_coherent() 等方法申请。 在DMA操作中涉及总线地址、 物理地址和虚拟地址等概念, 区分这3类地址非常重要。
Linux设备驱动的软件架构思想
Linux总线、 设备和驱动模型实际上可以做到这一点, 驱动只管驱动, 设备只管设备, 总线则负责匹配设备和驱动, 而驱动则以标准途径拿到板级信息, 这样, 驱动就可以放之四海而皆准了。
platform设备驱动
Linux发明了一种虚拟的总线, 称为platform总线, 相应的设备称为platform_device, 而驱动成为platform_driver。
注意: 所谓的platform_device并不是与字符设备、 块设备和网络设备并列的概念, 而是Linux系统提供的一种附加手段, 例如, 我们通常把在SoC内部集成的I 2 C、 RTC、 LCD、 看门狗等控制器都归纳为platform_device, 而它们本身就是字符设备。
将globalfifo作为platform设备
现在我们将前面章节的globalfifo驱动挂接到platform总线上, 这要完成两个工作。
1) 将globalfifo移植为platform驱动。
2) 在板文件中添加globalfifo这个platform设备。
为完成将globalfifo移植到platform驱动的工作, 需要在原始的globalfifo字符设备驱动中套一层platform_driver的外壳, 注意进行这一工作后, 并没有改变globalfifo是字符设备的本质, 只是将其挂接到了platform总线上。
module_platform_driver(globalfifo_driver);
module_platform_driver() 宏所定义的模块加载和卸载函数仅仅通过
platform_driver_register() 、 platform_driver_unregister() 函数进行platform_driver的注册与注销, 而原先注册和注销字符设备的工作已经被移交到platform_driver的probe() 和remove() 成员函数中。
在设备驱动中引入platform的概念至少有如下好处。
1) 使得设备被挂接在一个总线上, 符合Linux 2.6以后内核的设备模型。 其结果是使配套的sysfs节点、 设备电源管理都成为可能。
2) 隔离BSP和驱动。 在BSP中定义platform设备和设备使用的资源、 设备的具体配置信息, 而在驱动中, 只需要通过通用API去获取资源和数据, 做到了板相关代码和驱动代码的分离, 使得驱动具有更好的可扩展性和跨平台性。
3) 让一个驱动支持多个设备实例。 譬如DM9000的驱动只有一份, 但是我们可以在板级添加多份DM9000的platform_device, 它们都可以与唯一的驱动匹配。
设备驱动的分层思想
设备驱动核心层和实例化
在面向对象的程序设计中, 可以为某一类相似的事物定义一个基类, 而具体的事物可以继承这个基类中的函数。 如果对于继承的这个事物而言, 某成员函数的实现与基类一致, 那它就可以直接继承基类的函数; 相反,它也可以重写(Overriding) , 对父类的函数进行重新定义。 若子类中的方法与父类中的某方法具有相同的方法名、 返回类型和参数表, 则新方法将覆盖原有的方法。 这种面向对象的“多态”设计思想极大地提高了代码的可重用能力, 是对现实世界中事物之间关系的一种良好呈现。
Linux内核完全是由C语言和汇编语言写成, 但是却频繁地用到了面向对象的设计思想。 在设备驱动方面, 往往为同类的设备设计了一个框架, 而框架中的核心层则实现了该设备通用的一些功能。 同样的, 如果具体的设备不想使用核心层的函数, 也可以重写。
驱动核心层
我们可以归纳出核心层肩负的3大职责:
1) 对上提供接口。 file_operations的读、 写、 ioctl都被中间层搞定, 各种I/O模型也被处理掉了。
2) 中间层实现通用逻辑。 可以被底层各种实例共享的代码都被中间层搞定, 避免底层重复实现。
3) 对下定义框架。 底层的驱动不再需要关心Linux内核VFS的接口和各种可能的I/O模型, 而只需处理与具体硬件相关的访问。
这种分层有时候还不是两层, 可以有更多层, 在软件上呈现为面向对象里类继承和多态的状态。
主机驱动与外设驱动分离的设计思想
Linux中的SPI、 I 2 C、 USB等子系统都利用了典型的把主机驱动和外设驱动分离的想法, 让主机端只负责产生总线上的传输波形, 而外设端只是通过标准的API来让主机端以适当的波形访问自身。 因此这里面就涉及了4个软件模块:
1) 主机端的驱动。 根据具体的I 2 C、 SPI、 USB等控制器的硬件手册, 操作具体的I 2 C、 SPI、 USB等控制器,产生总线的各种波形。
2) 连接主机和外设的纽带。 外设不直接调用主机端的驱动来产生波形, 而是调一个标准的API。 由这个标准的API把这个波形的传输请求间接“转发”给了具体的主机端驱动。 当然, 在这里, 最好把关于波形的描述也以某种数据结构标准化。
3) 外设端的驱动。 外设接在I 2 C、 SPI、 USB这样的总线上, 但是它们本身可以是触摸屏、 网卡、 声卡或者任意一种类型的设备。 我们在相关的i2c_driver、 spi_driver、 usb_driver这种xxx_driver的probe() 函数中去注册它具体的类型。 当这些外设要求I 2 C、 SPI、 USB等去访问它的时候, 它调用“连接主机和外设的纽带”模块的标准API。
4) 板级逻辑。 板级逻辑用来描述主机和外设是如何互联的, 它相当于一个“路由表”。 假设板子上有多个SPI控制器和多个SPI外设, 那究竟谁接在谁上面管理互联关系, 既不是主机端的责任, 也不是外设端的责任, 这属于板级逻辑的责任。 这部分通常出现在arch/arm/mach-xxx下面或者arch/arm/boot/dts下面。
linux块设备驱动
块设备的I/O操作特点
字符设备与块设备I/O操作的不同如下:
1) 块设备只能以块为单位接收输入和返回输出, 而字符设备则以字节为单位。 大多数设备是字符设备, 因为它们不需要缓冲而且不以固定块大小进行操作。
2) 块设备对于I/O请求有对应的缓冲区, 因此它们可以选择以什么顺序进行响应, 字符设备无须缓冲且被直接读写。 对于存储设备而言, 调整读写的顺序作用巨大, 因为在读写连续的扇区的存储速度比分离的扇区更快。
3) 字符设备只能被顺序读写, 而块设备可以随机访问。
linux块设备驱动结构
block_device_operations结构体
在块设备驱动中, 有一个类似于字符设备驱动中file_operations结构体的block_device_operations结构体, 它是对块设备操作的集合
gendisk结构体
在Linux内核中, 使用gendisk(通用磁盘) 结构体来表示一个独立的磁盘设备(或分区)
bio、 request和request_queue
通常一个bio对应上层传递给块层的I/O请求。 每个bio结构体实例及其包含的bvec_iter、 bio_vec结构体实例描述了该I/O请求的开始扇区、 数据方向(读还是写) 、 数据放入的页,
与bio对应的数据每次存放的内存不一定是连续的, bio_vec结构体用来描述与这个bio请求对应的所有的内存
I/O调度算法可将连续的bio合并成一个请求。 请求是bio经由I/O调度进行调整后的结果, 这是请求和bio的区别。 因此, 一个request可以包含多个bio。 当bio被提交给I/O调度器时, I/O调度器可能会将这个bio插入现存的请求中, 也可能生成新的请求。
每个块设备或者块设备的分区都对应有自身的request_queue, 从I/O调度器合并和排序出来的请求会被分发(Dispatch) 到设备级的request_queue。
I/O调度器
内核包含3个I/O调度器, 它们分别是Noop I/O调度器、Deadline I/O调度器与CFQ I/O调度器。
Noop I/O调度器是一个简化的调度程序, 该算法实现了一个简单FIFO队列, 它只进行最基本的合并, 比较适合基于Flash的存储器。
Deadline I/O调度器是针对Anticipatory I/O调度器的缺点进行改善而得来的, 它试图把每次请求的延迟降至最低,该算法重排了请求的顺序来提高性能。 它使用轮询的调度器, 简洁小巧, 提供了最小的读取延迟和尚佳的吞吐量, 特别适合于读取较多的环境(比如数据库) 。
CFQ I/O调度器为系统内的所有任务分配均匀的I/O带宽, 提供一个公平的工作环境, 在多媒体应用中, 能保证音、 视频及时从磁盘中读取数据。
可以通过给内核添加启动参数, 选择所使用的I/O调度算法如:
kernel elevator=deadline
也可以通过类似如下的命令, 改变一个设备的调度器:
echo SCHEDULER > /sys/block/DEVICE/queue/scheduler
linux块设备驱动的初始化
在块设备的注册和初始化阶段, 与字符设备驱动类似, 块设备驱动要注册它们自己到内核, 申请设备号,除此之外, 在块设备驱动初始化过程中, 通常需要完成分配、 初始化请求队列, 绑定请求队列和请求处理函数的工作, 并且可能会分配、 初始化gendisk, 给gendisk的major、 fops、 queue等成员赋值, 最后添加gendisk。
块设备的打开与释放
块设备驱动的open() 函数和其字符设备驱动的对等体不太相似, 前者不以相关的inode和file结构体指针作为参数(因为file和inode概念位于文件系统层中) 。 在open() 中我们可以通过block_device参数bdev获取private_data、 在release() 函数中则通过gendisk参数disk获取,
块设备驱动的ioctl函数
与字符设备驱动一样, 块设备可以包含一个ioctl() 函数以提供对设备的I/O控制能力。 实际上, 高层的块设备层代码处理了绝大多数I/O控制, 如BLKFLSBUF、 BLKROSET、 BLKDISCARD、 HDIO_GETGEO、BLKROGET和BLKSECTGET等, 因此, 在具体的块设备驱动中通常只需要实现与设备相关的特定ioctl命令。
块设备驱动的I/O请求处理
使用请求队列
块设备驱动在使用请求队列的场景下, 会用blk_init_queue() 初始化request_queue, 而该函数的第一个参数就是请求处理函数的指针。 request_queue会作为参数传递给我们在调用blk_init_queue() 时指定的请求处理函数
块设备驱动请求处理函数的原型为:
static void xxx_req(struct request_queue *q)
这个函数不能由驱动自己调用, 只有当内核认为是时候让驱动处理对设备的读写等操作时, 它才调用这个函数。 该函数的主要工作就是发起与request对应的块设备I/O动作(但是具体的I/O工作不一定要在该函数内同步完成) 。
不使用请求队列
使用请求队列对于一个机械磁盘设备而言的确有助于提高系统的性能, 但是对于RAMDISK、ZRAM(Compressed RAM Block Device) 等完全可真正随机访问的设备而言, 无法从高级的请求队列逻辑中获益。 对于这些设备, 块层支持“无队列”的操作模式, 为使用这个模式, 驱动必须提供一个“制造请求”函数, 而不
是一个请求处理函数, “制造请求”函数的原型为:
static void xxx_make_request(struct request_queue *queue, struct bio *bio);
块设备驱动初始化的时候不再调用blk_init_queue() , 而是调用blk_alloc_queue() 和blk_queue_make_request() , xxx_make_request则会成为blk_queue_make_request() 的第2个参数。
xxx_make_request() 函数的第一个参数仍然是“请求队列”, 但是这个“请求队列”实际不包含任何请求, 因为块层没有必要将bio调整为请求。 因此, “制造请求”函数的主要参数是bio结构体。
linux MMC子系统
Linux MMC/SD存储卡是一种典型的块设备, 它的实现位于drivers/mmc。 drivers/mmc下又分为card、 core和host这3个子目录。 card实际上跟Linux的块设备子系统对接, 实现块设备驱动以及完成请求, 但是具体的协议经过core层的接口, 最终通过host完成传输, 因此整个MMC子系统的框架结构如图13.5所示。
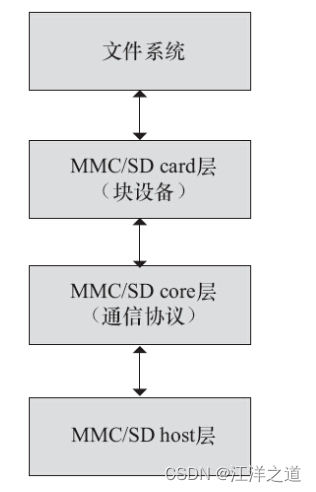
总结
块设备的I/O操作方式与字符设备的存在较大的不同, 因而引入了request_queue、 request、 bio等一系列数据结构。 在整个块设备的I/O操作中, 贯穿始终的就是“请求”, 字符设备的I/O操作则是直接进行不绕弯, 块设备的I/O操作会排队和整合。
驱动的任务是处理请求, 对请求的排队和整合由I/O调度算法解决, 因此, 块设备驱动的核心就是请求处理函数或“制造请求”函数。
尽管在块设备驱动中仍然存在block_device_operations结构体及其成员函数, 但不再包含读写类的成员函数, 而只是包含打开、 释放及I/O控制等与具体读写无关的函数。
块设备驱动的结构相对复杂, 但幸运的是, 块设备不像字符设备那样包罗万象, 它通常就是存储设备, 而且驱动的主体已经由Linux内核提供, 针对一个特定的硬件系统, 驱动工程师所涉及的工作往往只是编写极其少量的与硬件平台相关的代码。
linux网络设备驱动
linux网络设备驱动的结构
Linux网络设备驱动程序的体系结构如图14.1所示,
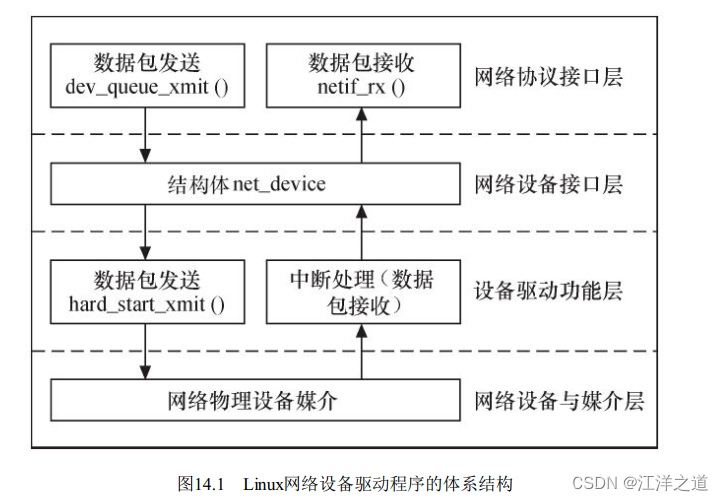
从上到下可以划分为4层, 依次为网络协议接口层、 网络设备接口层、 提供实际功能的设备驱动功能层以及网络设备与媒介层, 这4层的作用如下所示。
1) 网络协议接口层向网络层协议提供统一的数据包收发接口, 不论上层协议是ARP, 还是IP, 都通过dev_queue_xmit() 函数发送数据, 并通过netif_rx() 函数接收数据。 这一层的存在使得上层协议独立于具体的设备。
2) 网络设备接口层向协议接口层提供统一的用于描述具体网络设备属性和操作的结构体net_device, 该结构体是设备驱动功能层中各函数的容器。 实际上, 网络设备接口层从宏观上规划了具体操作硬件的设备驱动功能层的结构。
3) 设备驱动功能层的各函数是网络设备接口层net_device数据结构的具体成员, 是驱使网络设备硬件完成相应动作的程序, 它通过hard_start_xmit() 函数启动发送操作, 并通过网络设备上的中断触发接收操作。
4) 网络设备与媒介层是完成数据包发送和接收的物理实体, 包括网络适配器和具体的传输媒介, 网络适配器被设备驱动功能层中的函数在物理上驱动。 对于Linux系统而言, 网络设备和媒介都可以是虚拟的。
在设计具体的网络设备驱动程序时, 我们需要完成的主要工作是编写设备驱动功能层的相关函数以填充net_device数据结构的内容并将net_device注册入内核。
网络设备驱动的注册与注销
网络设备驱动的注册与注销由register_netdev() 和unregister_netdev() 函数完成, 这两个函数的原型为:
int register_netdev(struct net_device *dev);
void unregister_netdev(struct net_device *dev);
这两个函数都接收一个net_device结构体指针为参数, 可见net_device数据结构在网络设备驱动中的核心地位。
net_device的生成和成员的赋值并不一定要由工程师亲自动手逐个完成, 可以利用下面的宏帮助我们填充:
#define alloc_netdev(sizeof_priv, name, setup)
alloc_netdev_mqs(sizeof_priv, name, setup, 1, 1)
#define alloc_etherdev(sizeof_priv) alloc_etherdev_mq(sizeof_priv, 1)
#define alloc_etherdev_mq(sizeof_priv, count) alloc_etherdev_mqs(sizeof_priv, count, count)
alloc_netdev以及alloc_etherdev宏引用的alloc_netdev_mqs() 函数的原型为:
struct net_device *alloc_netdev_mqs(int sizeof_priv, const char *name, void (*setup)(struct net_device *), unsigned int txqs, unsigned int rxqs);
网络设备的初始化
网络设备的初始化主要需要完成如下几个方面的工作。
·进行硬件上的准备工作, 检查网络设备是否存在, 如果存在, 则检测设备所使用的硬件资源。
·进行软件接口上的准备工作, 分配net_device结构体并对其数据和函数指针成员赋值。
·获得设备的私有信息指针并初始化各成员的值。 如果私有信息中包括自旋锁或信号量等并发或同步机制, 则需对其进行初始化。
对net_device结构体成员及私有数据的赋值都可能需要与硬件初始化工作协同进行, 即硬件检测出了相应的资源, 需要根据检测结果填充net_device结构体成员和私有数据。
网络设备的打开与释放
网络设备的打开函数需要完成如下工作。
·使能设备使用的硬件资源, 申请I/O区域、 中断和DMA通道等。
·调用Linux内核提供的netif_start_queue() 函数, 激活设备发送队列。
网络设备的关闭函数需要完成如下工作。
·调用Linux内核提供的netif_stop_queue() 函数, 停止设备传输包。
·释放设备所使用的I/O区域、 中断和DMA资源。
Linux内核提供的netif_start_queue() 和netif_stop_queue() 两个函数的原型为:
void netif_start_queue(struct net_device *dev);
void netif_stop_queue (struct net_device *dev);
数据发送流程
Linux网络子系统在发送数据包时, 会调用驱动程序提供的hard_start_transmit() 函数, 该函数用于启动数据包的发送。 在设备初始化的时候, 这个函数指针需被初始化以指向设备的xxx_tx() 函数。
网络设备驱动完成数据包发送的流程如下。
1) 网络设备驱动程序从上层协议传递过来的sk_buff参数获得数据包的有效数据和长度, 将有效数据放入临时缓冲区。
2) 对于以太网, 如果有效数据的长度小于以太网冲突检测所要求数据帧的最小长度ETH_ZLEN, 则给临时缓冲区的末尾填充0。
3) 设置硬件的寄存器, 驱使网络设备进行数据发送操作。
数据接收流程
网络设备接收数据的主要方法是由中断引发设备的中断处理函数, 中断处理函数判断中断类型, 如果为接收中断, 则读取接收到的数据, 分配sk_buffer数据结构和数据缓冲区, 将接收到的数据复制到数据缓冲区, 并调用netif_rx() 函数将sk_buffer传递给上层协议。
网络连接状态
网络适配器硬件电路可以检测出链路上是否有载波, 载波反映了网络的连接是否正常。 网络设备驱动可以通过netif_carrier_on() 和netif_carrier_off() 函数改变设备的连接状态, 如果驱动检测到连接状态发生变化, 也应该以netif_carrier_on() 和netif_carrier_off() 函数显式地通知内核。
除了netif_carrier_on() 和netif_carrier_off() 函数以外, 另一个函数netif_carrier_ok() 可用于向调用者返回链路上的载波信号是否存在。
这几个函数都接收一个net_device设备结构体指针作为参数, 原型分别为:
void netif_carrier_on(struct net_device *dev);
void netif_carrier_off(struct net_device *dev);
int netif_carrier_ok(struct net_device *dev);
在网络设备驱动程序中可采取一定的手段来检测和报告链路状态, 最常见的方法是采用中断, 其次可以设置一个定时器来对链路状态进行周期性的检查。 当定时器到期之后, 在定时器处理函数中读取物理设备的相关寄存器以获得载波状态, 从而更新设备的连接状态。
总结
对Linux网络设备驱动体系结构的层次化设计实现了对上层协议接口的统一和硬件驱动对下层多样化硬件设备的可适应。 程序员需要完成的工作集中在设备驱动功能层, 网络设备接口层net_device结构体的存在将千变万化的网络设备进行抽象, 使得设备功能层中除数据包接收以外的主体工作都由填充net_device的属性和函数指针完成。
在分析net_device数据结构的基础上, 本章给出了设备驱动功能层设备初始化、 数据包收发、 打开和释放等函数的设计模板, 这些模板对实际设备驱动的开发具有直接指导意义。 有了这些模板, 我们在设计具体设备的驱动时, 不再需要关心程序的体系, 而可以将精力集中于硬件操作本身。
在Linux网络子系统和设备驱动中, 套接字缓冲区sk_buff发挥着巨大的作用, 它是所有数据流动的载体。 网络设备驱动和上层协议之间也基于此结构进行数据包交互, 因此, 我们要特别牢记它的操作方法。
Linux I 2 C核心、 总线与设备驱动
linuxI2C体系结构
Linux的I 2 C体系结构分为3个组成部分。
(1) I 2 C核心
I 2 C核心提供了I 2 C总线驱动和设备驱动的注册、 注销方法, I 2 C通信方法(即Algorithm) 上层的与具体适配器无关的代码以及探测设备、 检测设备地址的上层代码等
2) I 2 C总线驱动
I 2 C总线驱动是对I 2 C硬件体系结构中适配器端的实现, 适配器可由CPU控制, 甚至可以直接集成在CPU内部。
I 2 C总线驱动主要包含I 2 C适配器数据结构i2c_adapter、 I 2 C适配器的Algorithm数据结构i2c_algorithm和控制I 2 C适配器产生通信信号的函数。
( 3) I 2 C设备驱动
I 2 C设备驱动( 也称为客户驱动) 是对I 2 C硬件体系结构中设备端的实现, 设备一般挂接在受CPU控制的I 2 C适配器上, 通过I 2 C适配器与CPU交换数据。
I 2 C设备驱动主要包含数据结构i2c_driver和i2c_client, 我们需要根据具体设备实现其中的成员函数。
(1) i2c_adapter与i2c_algorithm
i2c_adapter对应于物理上的一个适配器, 而i2c_algorithm对应一套通信方法。 一个I 2 C适配器需要i2c_algorithm提供的通信函数来控制适配器产生特定的访问周期。 缺少i2c_algorithm的i2c_adapter什么也做不了, 因此i2c_adapter中包含所使用的i2c_algorithm的指针。
(2) i2c_driver与i2c_client
i2c_driver对应于一套驱动方法, 其主要成员函数是probe() 、 remove() 、 suspend() 、 resume() 等, 另外, struct i2c_device_id形式的id_table是该驱动所支持的I 2 C设备的ID表。 i2c_client对应于真实的物理设备, 每个I 2 C设备都需要一个i2c_client来描述。 i2c_driver与i2c_client的关系是一对多, 一个i2c_driver可以支持多个同类型的i2c_client。
(3) i2c_adpater与i2c_client
i2c_adpater与i2c_client的关系与I 2 C硬件体系中适配器和设备的关系一致, 即i2c_client依附于i2c_adpater。 由于一个适配器可以连接多个I 2 C设备, 所以一个i2c_adpater也可以被多个i2c_client依附, i2c_adpater中包括依附于它的i2c_client的链表。
工程师要实现的主要工作如下。
·提供I 2 C适配器的硬件驱动, 探测、 初始化I 2 C适配器(如申请I 2 C的I/O地址和中断号) 、 驱动CPU控制的I 2C适配器从硬件上产生各种信号以及处理I 2 C中断等。
·提供I 2 C适配器的Algorithm, 用具体适配器的xxx_xfer() 函数填充i2c_algorithm的master_xfer指针, 并把i2c_algorithm指针赋值给i2c_adapter的algo指针。
·实现I 2 C设备驱动中的i2c_driver接口, 用具体设备yyy的yyy_probe() 、 yyy_remove() 、 yyy_suspend() 、yyy_resume() 函数指针和i2c_device_id设备ID表赋值给i2c_driver的probe、 remove、 suspend、 resume和id_table指针。
·实现I 2 C设备所对应类型的具体驱动, i2c_driver只是实现设备与总线的挂接, 而挂接在总线上的设备则千差万别。 例如, 如果是字符设备, 就实现文件操作接口, 即实现具体设备yyy的yyy_read() 、 yyy_write() 和yyy_ioctl() 函数等; 如果是声卡, 就实现ALSA驱动。
上述工作中前两个属于I 2 C总线驱动, 后两个属于I 2 C设备驱动。
Linux I2C核心
I 2 C核心(drivers/i2c/i2c-core.c) 中提供了一组不依赖于硬件平台的接口函数, 这个文件一般不需要被工程师修改, 但是理解其中的主要函数非常关键, 因为I 2 C总线驱动和设备驱动之间以I 2 C核心作为纽带。
(1) 增加/删除i2c_adapter
int i2c_add_adapter(struct i2c_adapter *adap);
void i2c_del_adapter(struct i2c_adapter *adap);
(2) 增加/删除i2c_driver
int i2c_register_driver(struct module *owner, struct i2c_driver *driver);
void i2c_del_driver(struct i2c_driver *driver);
#define i2c_add_driver(driver)
i2c_register_driver(THIS_MODULE, driver)
(3) I 2 C传输、 发送和接收
int i2c_transfer(struct i2c_adapter * adap, struct i2c_msg *msgs, int num);
int i2c_master_send(struct i2c_client *client,const char *buf ,int count);
int i2c_master_recv(struct i2c_client *client, char *buf ,int count);
linux I2C适配器驱动
I 2 C适配器驱动的注册与注销
由于I 2 C总线控制器通常是在内存上的, 所以它本身也连接在platform总线上, 要通过platform_driver和platform_device的匹配来执行。 因此尽管I 2 C适配器给别人提供了总线, 它自己也被认为是接在platform总线上的一个客户。 Linux的总线、 设备和驱动模型实际上是一个树形结构, 每个节点虽然可能成为别人的总线控制器,但是自己也被认为是从上一级总线枚举出来的。
I 2 C总线的通信方法
我们需要为特定的I 2 C适配器实现通信方法, 主要是实现i2c_algorithm的functionality() 函数和master_xfer() 函数。
functionality() 函数非常简单, 用于返回algorithm所支持的通信协议, 如I2C_FUNC_I2C、 I2C_FUNC_10BIT_ADDR、I2C_FUNC_SMBUS_READ_BYTE、 I2C_FUNC_SMBUS_WRITE_BYTE等。
master_xfer() 函数在I 2 C适配器上完成传递给它的i2c_msg数组中的每个I 2 C消息。
master_xfer() 函数模板中的i2c_adapter_xxx_start() 、 i2c_adapter_xxx_setaddr() 、 i2c_adapter_xxx_wait_ack() 、i2c_adapter_xxx_readbytes() 、 i2c_adapter_xxx_writebytes() 和i2c_adapter_xxx_stop() 函数用于完成适配器的底层硬件操作, 与I 2 C适配器和CPU的具体硬件直接相关, 需要由工程师根据芯片的数据手册来实现。
i2c_adapter_xxx_readbytes() 用于从从设备上接收一串数据, i2c_adapter_xxx_writebytes() 用于向从设备写入一串数据, 这两个函数的内部也会涉及I 2 C总线协议中的ACK应答。
master_xfer() 函数的实现形式会很多种, 多数驱动以中断方式来完成这个流程, 比如发起硬件操作请求后, 将自己调度出去,因此中间会伴随着睡眠的动作。
多数I 2 C总线驱动会定义一个xxx_i2c结构体, 作为i2c_adapter的algo_data(类似“私有数据”) , 其中包含I 2 C消息数组指针、 数组索引及I 2 C适配器Algorithm访问控制用的自旋锁、 等待队列等, 而master_xfer() 函数在完成i2c_msg数组中消息的处理时, 也经常需要访问xxx_i2c结构体的成员以获取寄存器基地址、 锁等信息。
原文地址:https://blog.csdn.net/szxhcljyjsjdff/article/details/125753903
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_61447.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




