文章目录
前言
目前已经讲解了目前LLM的三大流派的两个起始模型:GPT-1(Decoder only)、BERT(Encoder only),但是这两个模型针对不同下游不同的NLP任务时还需要进行一定的修改(如添加一些线性层),Google经过庞大的预训练,最终提出了一个通用框架T5模型(Encoder-Decoder), 将所有NLP任务转化为text to text任务,微调时无需再修改模型,直接在原模型上微调即可。
ps:T5最核心的理念是:使用前缀任务声明及文本答案生成,统一所有自然语言处理任务的输入和输出。在此之前的几乎所有预训练语言模型,在下游任务微调过程中都需要添加非线性层,将模型的输出转化为任务指定的输出格式。
下图所示为T5的输入格式和输出格式。绿色部分表示翻译任务,红色和黄色部分分别表示CoLA(单句分类)和STS-B(文本语义相似度)任务,蓝色部分表示摘要生成任务,左侧的框表示T5的输入样例,右侧的框则是对应的输出结果。
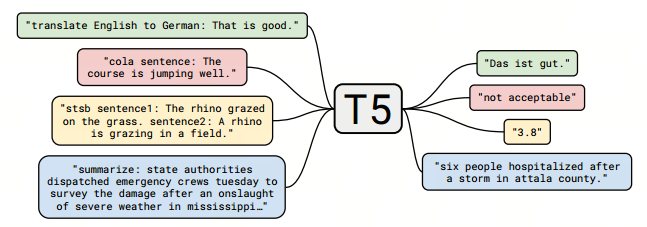
T5唯一需要做的就是在输入数据前加上任务声明前缀,如:
- 英德翻译:translate English to German:That is good.
- 情感分类:sentiment:This movie is terrible!
提示:以下是本篇文章正文内容,下面内容可供参考
一、T5的网络结构和流程
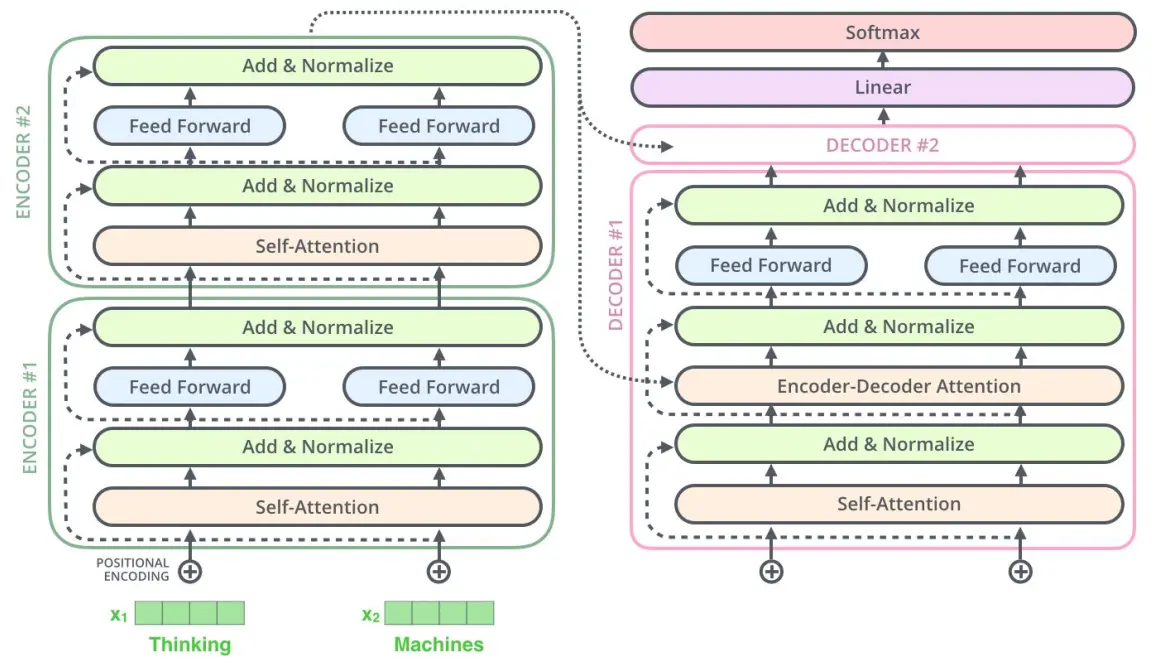
T5模型和原始的Transformer结构基本一致,具体的做了如下几点改动:
- 简化了Layer normalization,其中激活只是重新调整,没有添加附加偏差。
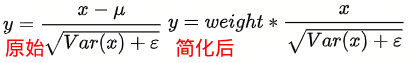
- 使用了简化的相对位置embedding,即每个位置对应一个数值而不是向量,原来的Transformer采用sin/cos习得position embeddings,而T5将(key和query)相对位置的数值加在attention softmax之前的logits上,每个head的有自己的position embeddings,所有的层共享一套position embeddings,每一层都计算一次,让模型对位置更加敏感。
二、T5的预训练过程
T5对预训练目标进行了大范围探索,总共从四个层面来进行比较: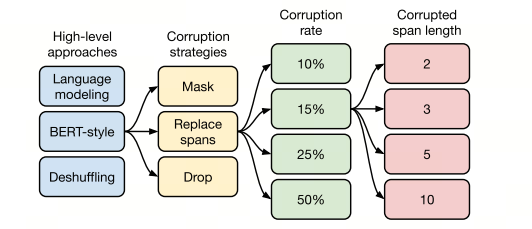
-
第一个方面,高层次方法(自监督的预训练方法)对比,总共三种方法:
- Prefix language modeling,从左到右顺序预测 - BERT-style 式(Masked LM),就是像BERT一样将一部分给破坏掉,然后还原出来,其效果最好 - Deshuffling(顺序还原)式,就是将文本打乱,然后还原出来
结论:发现 BERT-style 式预训练方法最好,因此下一个开始探索文本破坏策略 -
第二方面,对文本一部分进行破坏时的策略,也分三种方法:
- Masked法,将被破坏token换成特殊字符,如[M] - Replace spans法,把Mask 法中相邻 [M] 都合成了一个特殊符,每一小段替换一个特殊符,提高计算效率,其效果最好 - Drop法,没有替换操作,直接随机丢弃一些字符结论:Replace Spans 法胜出,因此下一个开始探索文本破坏的百分比
-
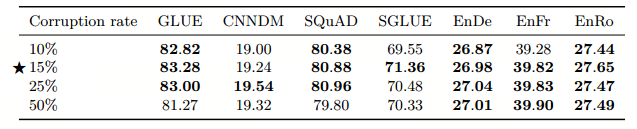
第三方面,探索对文本进行多大程度的破坏,挑了 4 个值:10%,15%,25%,50%,最后发现还是BERT的15%效果最好
-
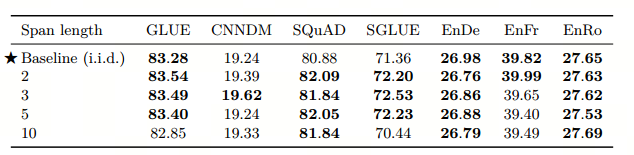
第四方面,Replace Spans需要决定对大概多长的小段进行破坏,于是对不同长度进行探索:2,3,5,10这四个值,最后发现Span length=3时的效果最好
此时就获得了完整的 T5 模型及其训练方法:
- Transformer Encoder-Decoder 模型;
- BERT-style 式的文本破坏方法;
- Replace Spans 的文本破坏策略;
- 15 %的文本破坏比;
- Replace Spans破坏时小段长度为3。
三、其他训练结论
-
网络结构(Architectures)
- 原始的Transformer结构表现最好 - encoder-decoder结构和BERT、GPT的计算量差不多 - 共享encoder和decoder的参数没有使效果差太多 -
无监督目标(Unsupervised objectives)
- 自编码(encoder-decoder)和自回归(decoder)的效果差不多 - 推荐选择更短目标序列的目标函数,提高计算效率 -
数据集(Datasets)
- 在领域内进行无监督训练可以提升一些任务的效果,但在一个小领域数据上重复训练会降低效果 - Large、diverse的数据集效果最好 -
训练策略(Training strategies)
- 精调时更新所有参数 > 更新部分参数 - 在多个任务上预训练之后微调 = 无监督预训练 -
模型缩放(Scaling)
- 在小模型上训练更多数据 < 用少量步数训练更大的模型 - 从一个预训练模型上微调多个模型后集成 < 分开预训练+微调后集成
总结
Google利用其庞大资源,给其他研究者带来了LLM领域新的研究方向和思路。
原文地址:https://blog.csdn.net/long11350/article/details/135703439
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_61489.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






