第 3 章:累加器
累加器:分布式共享只写变量。(executor和executor之间不能读数据)
累加器用来把executor端变量信息聚合到driver端。在driver中定义的一个变量,在executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回driver端进行合并计算。

1、累加器使用
1)累加器定义(sparkcontext.accumulator(initialvalue)方法)
val sum: LongAccumulator = sc.longAccumulator("sum")
2)累加器添加数据(累加器.add方法)
sum.add(count)
3)累加器获取数据(累加器.value)
sum.value
2、创建包名:com.atguigu.accumulator
3、代码实现
object accumulator01_system {
package com.atguigu.cache
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object accumulator01_system {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)))
//需求:统计a出现的所有次数 ("a",10)
//普通算子实现 reduceByKey 代码会走shuffle 效率低
//val rdd1: RDD[(String, Int)] = dataRDD.reduceByKey(_ + _)
//普通变量无法实现
//结论:普通变量只能从driver端发给executor端,在executor计算完以后,结果不会返回给driver端
/*
var sum = 0
dataRDD.foreach{
case (a,count) => {
sum += count
println("sum = " + sum)
}
}
println(("a",sum))
*/
//累加器实现
//1 声明累加器
val accSum: LongAccumulator = sc.longAccumulator("sum")
dataRDD.foreach{
case (a,count) => {
//2 使用累加器累加 累加器.add()
accSum.add(count)
// 4 不要在executor端获取累加器的值,因为不准确
//因此我们说累加器叫分布式共享只写变量
//println("sum = " + accSum.value)
}
}
//3 获取累加器的值 累加器.value
println(("a",accSum.value))
sc.stop()
}
}
注意:executor端的任务不能读取累加器的值(例如:在executor端调用sum.value,获取的值不是累加器最终的值)。因此我们说,累加器事一个分布式共享只写变量。累加器要放在行动算子中。因为转换算子执行的次数取决于job的数量,如果一个spark应用有多个行动算子,那么转换算子中的累加器可能会不止一次更新,导致结果错误。所以,如果想要一个无论是失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach()这样的行动算子中。
对于在行动算子中使用的累加器,spark只会把每个job对各累加器的修改应用一次。
object accumulator02_updateCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)))
//需求:统计a出现的所有次数 ("a",10)
//累加器实现
//1 声明累加器
val accSum: LongAccumulator = sc.longAccumulator("sum")
val mapRDD: RDD[Unit] = dataRDD.map {
case (a, count) => {
//2 使用累加器累加 累加器.add()
accSum.add(count)
// 4 不要在executor端获取累加器的值,因为不准确 因此我们说累加器叫分布式共享只写变量
//println("sum = " + accSum.value)
}
}
//调用两次行动算子,map执行两次,导致最终累加器的值翻倍
mapRDD.collect()
mapRDD.collect()
/**
* 结论:使用累加器最好要在行动算子中使用,因为行动算子只会执行一次,而转换算子的执行次数不确定!
*/
//2 获取累加器的值 累加器.value
println(("a",accSum.value))
sc.stop()
}
}
一般在开发中使用的累加器为集合累加器,在某些场景可以减少shuffle
现在我们用集合累加器实现wordcount:
object Test02_Acc {
def main(args: Array[String]): Unit = {
//1、创建sparkcontext配置
val conf = new SparkConf().setMaster("local[4]").setAppName("test")
//2、创建sparkcontext
val sc = new SparkContext(conf)
//3、创建集合累加器,累加元素为Map
val acc = sc.collectionAccumulator[mutable.Map[String,Int]]
//4、读取文件
val rdd1 = sc.textFile("datas/wc.txt")
//5、切割+转换
val rdd2 = rdd1.flatMap(x=>x.split(" "))
//6、转换为KV键值对
val rdd3 = rdd2.map(x=>(x,1))
//7、使用foreachPartitions在每个分区中对所有单词累加,将累加结果放入累加器中
rdd3.foreachPartition(it=> {
//创建一个累加Map容器
val map = mutable.Map[String,Int]()
//遍历分区数据
it.foreach(x=>{
val num = map.getOrElse(x._1,0)
//将单词累加到map容器中
map.put(x._1,num+x._2)
})
//将装载分区累加结果的map容器放入累加器中
acc.add(map)
})
//为了方便操作,将java集合转成scala集合
import scala.collection.JavaConverters._
//获取累加器结果,此时List中的每个Map是之前放入累加器的分区累加结果Map
val r = acc.value.asScala
//压平,将所有分区计算结果放入List中
val pList = r.flatten
//按照单词分组
val rMap = pList.groupBy(x=>x._1)
//,统计每个单词总个数
val result = rMap.map(x => (x._1, x._2.map(_._2).sum))
println(result)
// 4.关闭sc
sc.stop()
}
}
第 4 章:广播变量
广播变量:分布式共享只读变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个spark task操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量会用起来会很顺手。在多个task并行操作中使用同一个变量,但是spark会为每个task任务分别发送。
1、使用广播变量步骤:
1)调用sparkcontext.broadcast(广播变量)创建出一个广播对象,任何可序列化的类型都可以这么实现。
2)通过广播变量.value,访问该对象的值。
3)广播变量只会被发到各个节点一次,作为只读值处理(修改这个值不会影响到别的节点)。
2、原理说明
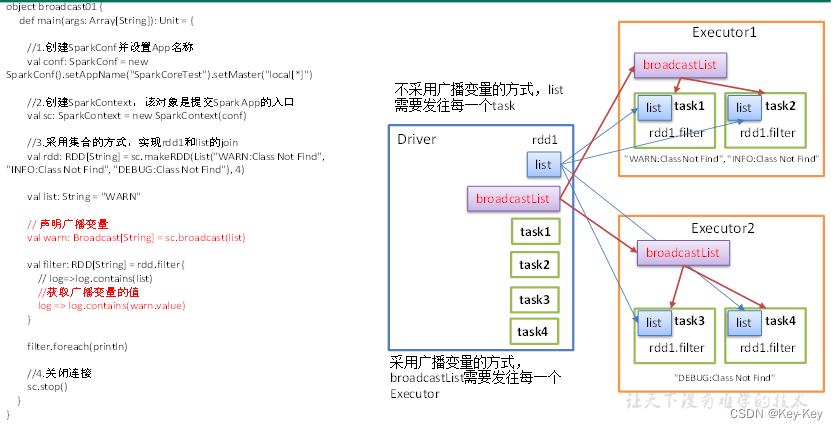
3、创建包名:com.atguigu.broadcast
4、代码实现
object broadcast01 {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建一个字符串RDD,过滤出包含WARN的数据
val rdd: RDD[String] = sc.makeRDD(List("WARN:Class Not Find", "INFO:Class Not Find", "DEBUG:Class Not Find"), 4)
val str: String = "WARN"
// 声明广播变量
val bdStr: Broadcast[String] = sc.broadcast(str)
val filterRDD: RDD[String] = rdd.filter {
// log=>log.contains(str)
log => log.contains(bdStr.value)
}
filterRDD.foreach(println)
//4.关闭连接
sc.stop()
}
}
第 5 章:sparkcore实战
5.1 数据准备
1、数据格式

1)数据采用_分割字段
2)每一行表示用户的一个行为,所以每一行只能是四种行为中的一种
3)如果点击的品类id和产品id是-1表示这次不是点击
4)针对下单行为,一次可以下单多个产品,所以品类id和产品id都是多个,id之间使用逗号分割。如果本次不是下单行为,则他们相关数据用null来表示。
5)支付行为和下单行为格式类似。
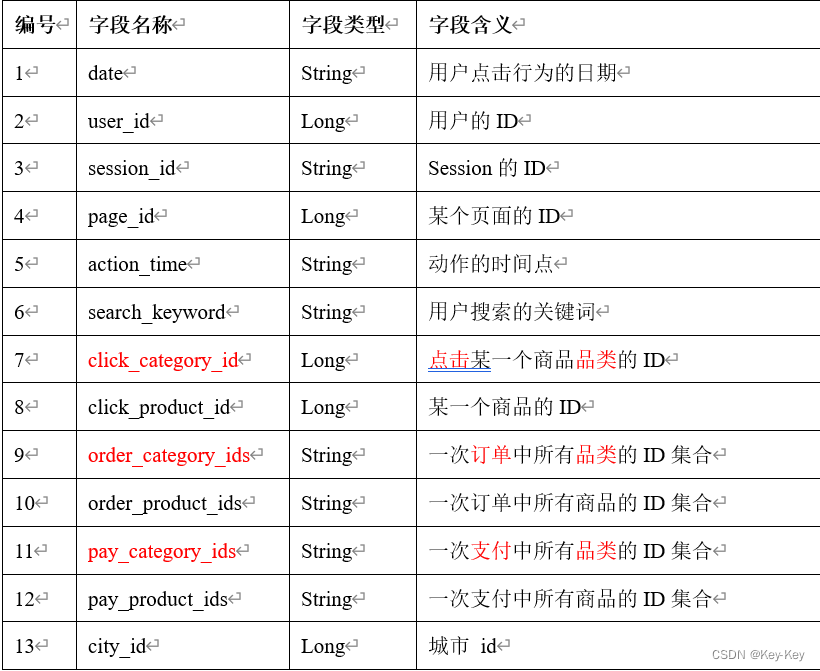
2、数据详情字段说明
5.2 需求:top10热门品类

需求说明:品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量(次数)来统计热门品类。

例如:综合排名=点击数20%+下单数30%+支付书数*50%
本项目需求优化为:先按照点击数排名,考前的就排名高;如果点击数相同,再比较下单数;下单数相同,就比较支付数。
5.2.1 需求分析(方案一)常规算子
思路:分别统计每个品类点击的次数,下单的次数和支付的次数。然后想办法将三个rdd联合在一块。
(品类,点击总数)(品类,下单总数)(品类,支付总数)
(品类,(点击总数,下单总数,支付总数))
然后就可以按照各品类的元组(点击总数,下单总数,支付总数)进行倒叙排序了,因为元组排序刚好是先排第一个元素,然后排第二个元素,最后第三个元素。最后取top10即可。
5.2.2 需求实现(方案一)
1)创建包名:com.atguigu.project01
2)方案一:代码实现(cogroup算子实现满外连接)
package com.atguigu.spark.demo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test01_Top10 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2. 初始化sc
val sc = new SparkContext(conf)
// 3. 编写代码
// 需求: top10的热门品类 通过(id,(点击,下单,支付))
val lineRDD: RDD[String] = sc.textFile("input/user_visit_action.txt")
// 1. 过滤点击数据 进行统计
val clickRDD: RDD[String] = lineRDD.filter(line => {
val data: Array[String] = line.split("_")
// 读进来的数据全部都是字符串
data(6) != "-1"
})
// 统计品类点击次数即可
val clickCountRDD: RDD[(String, Int)] = clickRDD.map(line => {
val data: Array[String] = line.split("_")
(data(6), 1)
})
.reduceByKey(_ + _)
// 2. 过滤统计下单品类
val orderRDD: RDD[String] = lineRDD.filter(line => {
val data: Array[String] = line.split("_")
data(8) != "null"
})
val orderCountRDD: RDD[(String, Int)] = orderRDD.flatMap(line => {
// 切分整行数据
val data: Array[String] = line.split("_")
// 切分下单品类
val orders: Array[String] = data(8).split(",")
// 改变数据结构 (下单品类,1)
orders.map((_, 1))
}).reduceByKey(_ + _)
// 3. 过滤统计支付品类数据
val payRDD: RDD[String] = lineRDD.filter(line => {
val data: Array[String] = line.split("_")
data(10) != "null"
})
val payCountRDD: RDD[(String, Int)] = payRDD.flatMap(line => {
val data: Array[String] = line.split("_")
val pays: Array[String] = data(10).split(",")
pays.map((_, 1))
}).reduceByKey(_ + _)
// 使用cogroup满外连接 避免使用join出现有的品类只有点击没有下单支付 造成数据丢失
val cogroupRDD: RDD[(String, (Iterable[Int], Iterable[Int], Iterable[Int]))] = clickCountRDD.cogroup(orderCountRDD, payCountRDD)
// 改变数据结构 (id,(list(所有当前id的点击数据),list(所有当前id的下单数据),list(所有当前id的支付数据)))
val cogroupRDD2: RDD[(String, (Int, Int, Int))] = cogroupRDD.mapValues({
case (clickList, orderList, payList) => (clickList.sum, orderList.sum, payList.sum)
})
// 排序取top10
val result: Array[(String, (Int, Int, Int))] = cogroupRDD2.sortBy(_._2, false).take(10)
result.foreach(println)
Thread.sleep(600000)
// 4.关闭sc
sc.stop()
}
}
3)一次计算,转换数据结构,通过位置标记数据的类型,不再使用三次过滤,减少reducebykey的次数
package com.atguigu.spark.demo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test02_Top10 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2. 初始化sc
val sc = new SparkContext(conf)
// 3. 编写代码
// 需求: top10的热门品类 通过(id,(点击,下单,支付))
val lineRDD: RDD[String] = sc.textFile("input/user_visit_action.txt")
// 通过位置来标记属于什么类型的数据
// val filterRDD: RDD[String] = lineRDD.filter(line => {
// val data: Array[String] = line.split("_")
// // 过滤出所有的点击 下单 支付数据
// data(6) != "-1" || data(8) != "null" || data(10) != "null"
// })
// 转换数据结构
// 1. 点击数据 -> (id,(1,0,0))
// 2. 下单数据 -> (id,(0,1,0))
// 3. 支付数据 -> (id,(0,0,1))
val flatMapRDD: RDD[(String, (Int, Int, Int))] = lineRDD.flatMap(line => {
val data: Array[String] = line.split("_")
// 判断属于三种的哪一种
if (data(6) != "-1") {
// 点击数据
List((data(6), (1, 0, 0)))
} else if (data(8) != "null") {
// 下单数据
// 此处为数组 需要拆分为多个
val orders: Array[String] = data(8).split(",")
// 多个订单(15,13,5) => (15,(0,1,0)),(13,(0,1,0))...
orders.map(order => (order, (0, 1, 0)))
} else if (data(10) != "null") {
// 支付数据
val pays: Array[String] = data(10).split(",")
pays.map(pay => (pay, (0, 0, 1)))
} else {
List()
}
})
val reduceRDD: RDD[(String, (Int, Int, Int))] = flatMapRDD.reduceByKey((res, elem) => (res._1 + elem._1, res._2 + elem._2, res._3 + elem._3))
val result: Array[(String, (Int, Int, Int))] = reduceRDD.sortBy(_._2, false).take(10)
result.foreach(println)
Thread.sleep(600000)
// 4.关闭sc
sc.stop()
}
}
5.2.3 需求分析(方案二)样例类
使用样例类的方式实现。

5.2.4 需求实现(方案二)
1、用来封装用户行为的样例类
//用户访问动作表
case class UserVisitAction(date: String,//用户点击行为的日期
user_id: String,//用户的ID
session_id: String,//Session的ID
page_id: String,//某个页面的ID
action_time: String,//动作的时间点
search_keyword: String,//用户搜索的关键词
click_category_id: String,//某一个商品品类的ID
click_product_id: String,//某一个商品的ID
order_category_ids: String,//一次订单中所有品类的ID集合
order_product_ids: String,//一次订单中所有商品的ID集合
pay_category_ids: String,//一次支付中所有品类的ID集合
pay_product_ids: String,//一次支付中所有商品的ID集合
city_id: String)//城市 id
// 输出结果表
case class CategoryCountInfo(categoryId: String,//品类id
clickCount: Long,//点击次数
orderCount: Long,//订单次数
payCount: Long)//支付次数
注意:样例类的属性默认是val修饰,不能修改;需要修改属性,需要采用var修饰。
// 输出结果表
case class CategoryCountInfo(var categoryId: String,//品类id
var clickCount: Long,//点击次数
var orderCount: Long,//订单次数
var payCount: Long)//支付次数
注意:样例类的属性默认是val修饰,不能修改;需要修改属性,需要采用var修饰。
2、核心业务代码实现
package com.atguigu.spark.demo
import com.atguigu.spark.demo.bean.{CategoryCountInfo, UserVisitAction}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test04_Top10 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2. 初始化sc
val sc = new SparkContext(conf)
// 3. 编写代码
// 读取数据
val lineRDD: RDD[String] = sc.textFile("input/user_visit_action.txt")
// 转换为样例类
val userRDD: RDD[UserVisitAction] = lineRDD.map(line => {
val data: Array[String] = line.split("_")
UserVisitAction(
data(0),
data(1),
data(2),
data(3),
data(4),
data(5),
data(6),
data(7),
data(8),
data(9),
data(10),
data(11),
data(12)
)
})
//切分数据为单个品类
val categoryRDD: RDD[CategoryCountInfo] = userRDD.flatMap(user => {
if (user.click_category_id != "-1") {
// 点击数据
List(CategoryCountInfo(user.click_category_id, 1, 0, 0))
} else if (user.order_category_ids != "null") {
// 下单数据
val orders: Array[String] = user.order_category_ids.split(",")
orders.map(order => CategoryCountInfo(order, 0, 1, 0))
} else if (user.pay_category_ids != "null") {
// 支付数据
val pays: Array[String] = user.pay_category_ids.split(",")
pays.map(pay => CategoryCountInfo(pay, 0, 0, 1))
} else {
List()
}
})
// 聚合同一品类的数据
val groupRDD: RDD[(String, Iterable[CategoryCountInfo])] = categoryRDD.groupBy(_.categoryId)
val value: RDD[(String, CategoryCountInfo)] = groupRDD.mapValues(list => {
// 集合常用函数
list.reduce((res, elem) => {
res.clickCount += elem.clickCount
res.orderCount += elem.orderCount
res.payCount += elem.payCount
res
})
})
val categoryReduceRDD: RDD[CategoryCountInfo] = value.map(_._2)
// 排序取top10
val result: Array[CategoryCountInfo] = categoryReduceRDD.sortBy(info =>
(info.clickCount, info.orderCount, info.payCount),false)
.take(10)
result.foreach(println)
Thread.sleep(600000)
// 4.关闭sc
sc.stop()
}
}
5.2.5 需求分析(方案三)样例类+算子优化
针对方案二中的groupby算子,没有提前聚合的功能,替换成reducebykey

5.2.6 需求实现(方案三)
1、样例类代码和方案二一样。
2、核心代码实现
package com.atguigu.spark.demo
import com.atguigu.spark.demo.bean.{CategoryCountInfo, UserVisitAction}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test05_Top10 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2. 初始化sc
val sc = new SparkContext(conf)
// 3. 编写代码
// 读取数据
val lineRDD: RDD[String] = sc.textFile("input/user_visit_action.txt")
// 转换为样例类
val userRDD: RDD[UserVisitAction] = lineRDD.map(line => {
val data: Array[String] = line.split("_")
UserVisitAction(
data(0),
data(1),
data(2),
data(3),
data(4),
data(5),
data(6),
data(7),
data(8),
data(9),
data(10),
data(11),
data(12)
)
})
//切分数据为单个品类
val categoryRDD: RDD[CategoryCountInfo] = userRDD.flatMap(user => {
if (user.click_category_id != "-1") {
// 点击数据
List(CategoryCountInfo(user.click_category_id, 1, 0, 0))
} else if (user.order_category_ids != "null") {
// 下单数据
val orders: Array[String] = user.order_category_ids.split(",")
orders.map(order => CategoryCountInfo(order, 0, 1, 0))
} else if (user.pay_category_ids != "null") {
// 支付数据
val pays: Array[String] = user.pay_category_ids.split(",")
pays.map(pay => CategoryCountInfo(pay, 0, 0, 1))
} else {
List()
}
})
// 聚合同一品类的数据
// 使用reduceByKey调换groupBy (重要)
val reduceRDD: RDD[(String, CategoryCountInfo)] = categoryRDD.map(info => (info.categoryId, info))
.reduceByKey((res, elem) => {
res.clickCount += elem.clickCount
res.orderCount += elem.orderCount
res.payCount += elem.payCount
res
})
val categoryReduceRDD: RDD[CategoryCountInfo] = reduceRDD.map(_._2)
// 排序取top10
val result: Array[CategoryCountInfo] = categoryReduceRDD.sortBy(info =>
(info.clickCount, info.orderCount, info.payCount),false)
.take(10)
result.foreach(println)
Thread.sleep(600000)
// 4.关闭sc
sc.stop()
}
}
原文地址:https://blog.csdn.net/key_honghao/article/details/135831892
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_61529.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!