当前位置: 首页互联网正文 本文介绍: 我们通常使用n来表示数据集中的样本数。对索引为i的样本,其输入表示为xix1ix2i…xni⊤,其对应的标签是yi。 1exp(−2σ21(y−w⊤x−b)2). 现在,根据极大似然估计法,参数 w mathbf{w} w和 b b b的最优值是使整个数据集的似然最大的值: P ( y ∣ X ) = ∏ i = 1 n p ( y ( i ) ∣ x ( i ) ) . P(mathbf y mid mathbf X) = prod_{i=1}^{n} p(y^{(i)}|mathbf{x}^{(i)}). P(y∣X)=i=1∏np(y(i)∣x(i)). 根据极大似然估计法选择的估计量称为极大似然估计量。虽然使许多指数函数的乘积最大化看起来很困难,但是我们可以在不改变目标的前提下,通过最大化似然对数来简化。由于历史原因,优化通常是说最小化而不是最大化。我们可以改为最小化负对数似然 − log P ( y ∣ X ) -log P(mathbf y mid mathbf X) −logP(y∣X)。由此可以得到的数学公式是: − log P ( y ∣ X ) = ∑ i = 1 n 1 2 log ( 2 π σ 2 ) + 1 2 σ 2 ( y ( i ) − w ⊤ x ( i ) − b ) 2 . -log P(mathbf y mid mathbf X) = sum_{i=1}^n frac{1}{2} log(2 pi sigma^2) + frac{1}{2 sigma^2} left(y^{(i)} – mathbf{w}^top mathbf{x}^{(i)} – bright)^2. −logP(y∣X)=i=1∑n21log(2πσ2)+2σ21(y(i)−w⊤x(i)−b)2. 现在我们只需要假设 σ sigma σ是某个固定常数就可以忽略第一项,现在第二项除了常数 1 σ 2 frac{1}{sigma^2} σ21外,其余部分和前面介绍的均方误差是一样的。因此,在高斯噪声的假设下,最小化均方误差等价于对线性模型的极大似然估计。 3.1.4 From Linear Regression to Deep Networks 我们可以用描述神经网络的方式来描述线性模型,从而把线性模型看作一个神经网络。 首先,我们用“层”符号来重写这个模型。深度学习从业者喜欢绘制图表来可视化模型中正在发生的事情。我们将线性回归模型描述为一个神经网络。需要注意的是,该图只显示连接模式,即只显示每个输入如何连接到输出,隐去了权重和偏置的值。 在图中所示的神经网络中,输入为 x 1 , … , x d x_1, ldots, x_d x1,…,xd,因此输入层中的输入数(或称为特征维度,feature dimensionality)为 d d d。网络的输出为 o 1 o_1 o1,因此输出层中的输出数是1。需要注意的是,输入值都是已经给定的,并且只有一个计算神经元。由于模型重点在发生计算的地方,所以通常我们在计算层数时不考虑输入层。也就是说,图中神经网络的层数为1。我们可以将线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。对于线性回归,每个输入都与每个输出(在本例中只有一个输出)相连,我们将这种变换( 图中的输出层)称为全连接层(fully-connected layer)或称为稠密层(dense layer)。 原文地址:https://blog.csdn.net/weixin_73004416/article/details/135833963 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_61547.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。mathbf估计量似然 代码007普通 打赏 收藏 海报 链接


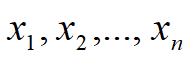


![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)