第 1 章:数据仓库
1.1 数据仓库概述
1.1.1 数据仓库概念
1、数据仓库概念:
为企业制定决策,提供数据支持的集合。通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本,提高产品质量。
数据仓库并不是数据的最终目的地,而是为数据最终的目的地做好准备,这些准备包括对数据的:清洗、转义、分类、重组、合并、拆分、统计等。
2、数据仓库的数据通常包括:业务数据、用户行为数据和爬虫数据等
3、业务系统数据库(关系型数据库中)
1)业务数据:主要指的是各行业在处理事务过程中产生的业务数据
2)产生:用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据
3)存储:都是存储到关系型数据库(如:mysql、oracle)中。

4、用户行为数据(日志文件log)
1)用户行为数据:用户在使用产品过程中,通过埋点与客户端产品交互所产生的数据,并发往日志服务器进行保存。
2)存储:用户数据通常存储在日志文件中。
5、爬虫数据:通过技术手段获取其它公司网站的数据。

1.1.2 数据仓库示意图
数据仓库(data warehouse),为企业指定决策,提供数据支持的。可以帮助企业,改进业务流程、提高产品质量等。
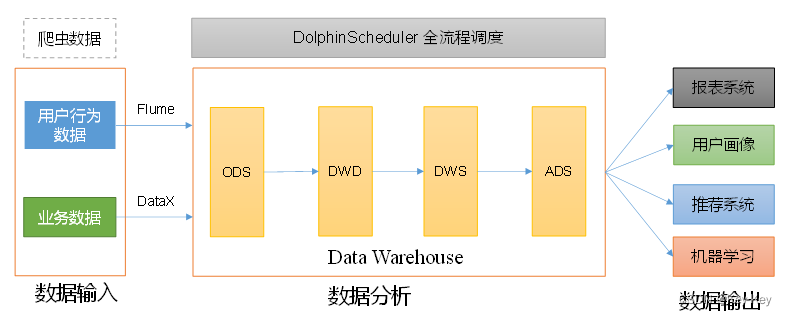
数据仓库,并不是数据的最终目的地,而是为数据最终的目的地做好准备。这些准备包括对数据的:备份、清洗、聚合、统计等。
1、报表系统:对存储的数据做数据统计分析
2、用户画像:即用户信息标签化,是基于数据挖掘的用户特征提取即需求深度挖掘,是大数据时代围绕“以用户为中心”开展的个性化服务。标签化的模型是从用户社交属性、生活习惯、消费行为等信息中抽象出来的产物,是用户“特征标签”的几个。
3、推荐系统:通过对用户的历史行为、用户兴趣偏好来经过推荐算法计算分析,然后产生用户可能感兴趣的项目列表。推荐系统可以更精准的理解用户需求,对用户进行聚类、打标签,推荐用户感兴趣的商品,帮助用户快速找到需要的商品,同时放大需求、增加流量入口、提高商品销售的有效转化率。
4、机器学习:利用机器学习算法模型基于大数据集进行数据挖掘,发现和利用数据价值。
1.2 数仓项目搭建概述
1.2.1 项目需求分析
1、数据需求:用户分析日志log、业务数据db
2、采集需求:日志采集系统(flume)、业务数据同步系统(Maxwell,datax)
3、数据仓库建模:维度建模
4、数据分析:对设备、会员、商品、地区、活动等电商核心主题进行统计,统计的报表指标接近100个。

5、即席查询:用户在使用系统时,根据自己当时的需求定义的查询,通常使用即席查询工具。
6、集群监控:对集群性能进行监控,发生异常及时报警。
7、元数据管理:存储所有表对象的详细信息,通过元数据管理有助于开发人员理解管理数据。
8、数据质量监控:数据质量是数据分析和数据挖掘结果有效性和准确性的基础。数据的导入导出是否完整、一致等问题。一般使用数据质量监控工具完成。
1.2.2 项目框架
思考:项目技术如何选型?
1、技术选型
考虑的因素:数据量的大小、业务需求、行业经验、技术成熟度、开发维护成本、总成本预算
技术选型
数据采集传输:Flume、kafka、datax,maxwell,sqoop,logstash
数据存储:mysql、hdfs、hbase、redis、mongodb
数据计算:hive、spark、flink、storm、tez
数据查询:presto、kylin、impala、druid、clickhouse、doris
数据可视化:superset、echarts、quickbi、datav
任务调度、dolphinscheduler、azkabanoozie、airflow
集群监控:zabbix、prometheus
元数据管理:atlas
权限管理:ranger、sentry

2、系统流程设计
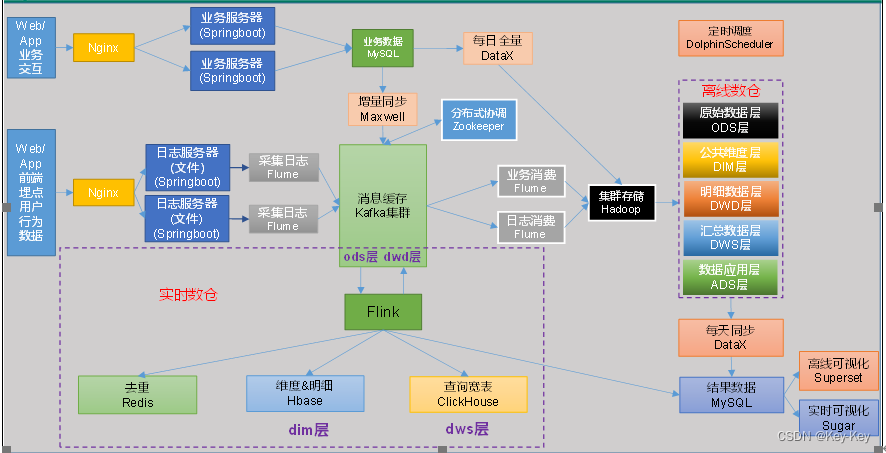
思考:框架版本如何选择?
3、框架版本选型
1)框架选型
(1)如何选择apache/cdh/hdp版本?
apache:运维麻烦,组件间兼容性需要自己调研。(大厂使用)
cdh:国内使用最多的版本,开始收费
hdp:开源,可以进行二次开发,但没cdh稳定,国内很少使用
(2)云服务选择
阿里云的emr、maxcompute、dataworks
亚马逊云emr
腾讯云emr
华为云emr
2)apache框架版本选型
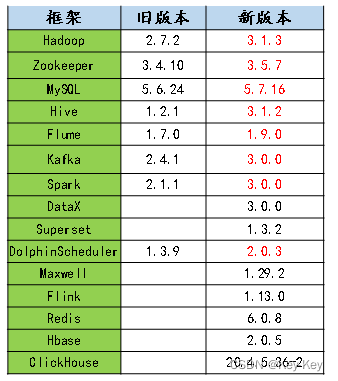
版本选择基本原则:
大版本:框架版本选择尽量不要选择最新的框架,选择最新版本半年前的稳定版本。
小版本:选大不选小。
1.3 基础设施
1.3.1 服务器选型
思考:服务器选择物理机还是云主机呢?主要看成本

不同类型主机的成本投入:

如何选择?
1、有钱并且和阿里有业务冲突的 -> 物理机
2、中小公司,为了快速拉到投资 -> 阿里云
3、资金充足,有长期打算的公司 -> 物理机
1.3.2 集群资源规划
在企业中通常会搭建一套生产集群和一套测试集群。
生产集群运行生产任务。
测试集群用于上线前代码编写和测试。
1、集群规模
数据量有关
1)如何确认集群规模?(假设:每台服务器8T磁盘,128G内存)
(1)每天日活用户100万,每人一天平均100条:100万100条=1亿条
(2)每条日志1K左右,每天1亿条:100000000/1024/1024=约100G
(3)半年内不扩容服务器来算:100G180天=约18T
(4)保存3副本:18T3=54T
(5)预留20%~30%Buf=54T/0.7=77T
(6)算到这:约8T10台服务器
2)如果考虑数仓分层?数据采用压缩?需要重新再计算
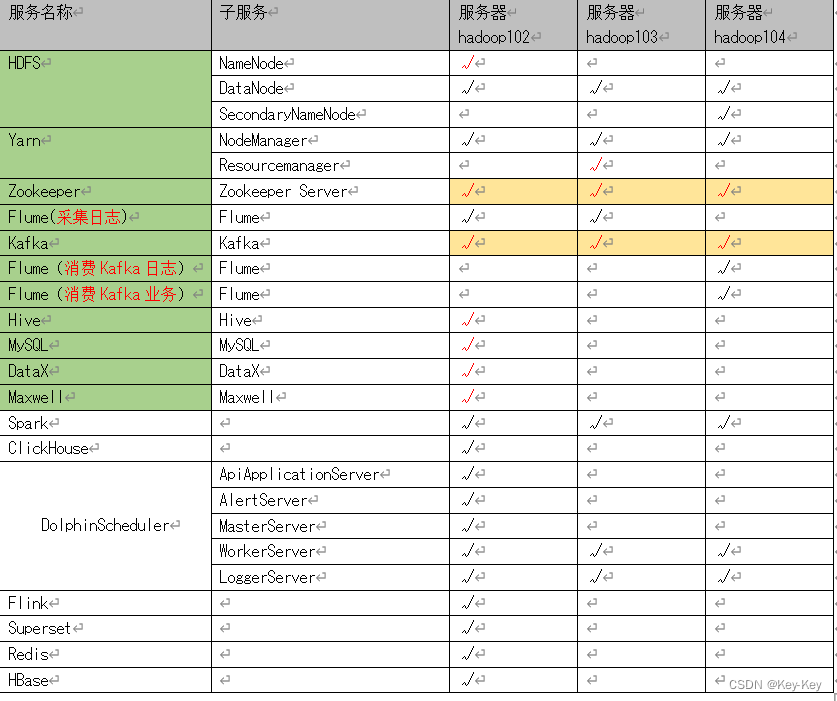
2、部署原则:
1)消耗内存的分开
2)传输数据比较紧密的放在一起(kafka、zookeeper)
3)客户端尽量放在1到2台服务器上,方便外部访问
4)有依赖关系的尽量放在同一台服务器上
(1)生产集群部署规划
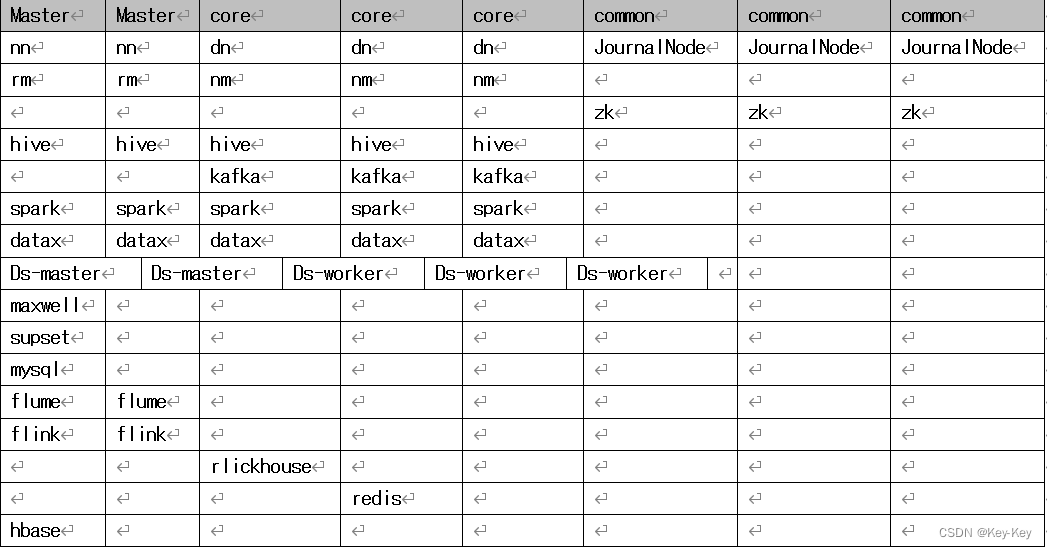
(2)测试集群服务部署规划
第 2 章:用户行为日志
2.1 用户行为日志概述
1、用户行为日志:包括用户的各项行为信息以及行为所处的环境信息
2、目的:优化产品和为各项分析统计指标提供数据支撑
3、收集手段:埋点
2.2 用户行为日志内容
本项目中收集和分析目标数据主要有:页面数据、事件数据、曝光数据、启动数据和错误数据
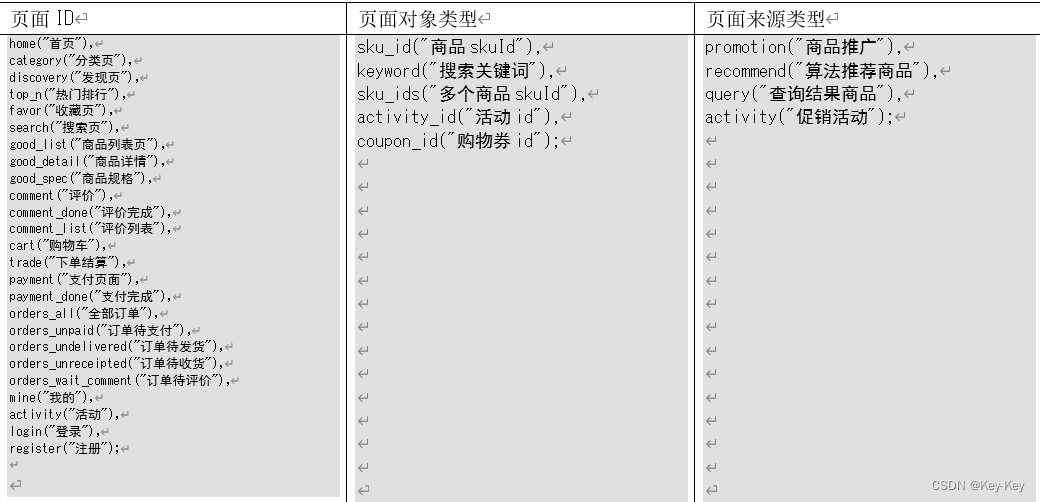
2.2.1 页面数据
1、页面数据:主要记录一个页面的用户访问情况,包括访问时间、停留时间、页面路径等信息。
2.2.2 事件数据
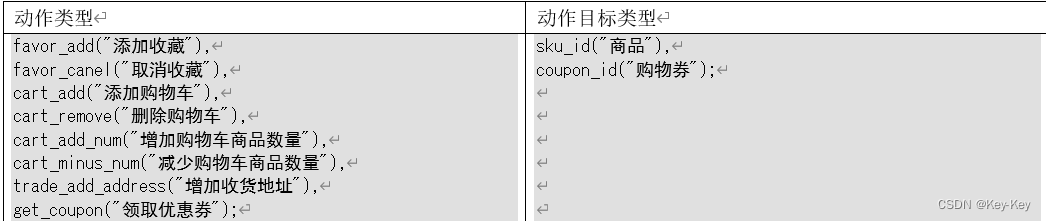
事件数据主要记录应用内一个具体的操作行为,包括操作类型、操作对象、操作对象描述等信息

2.2.3 曝光数据
曝光数据主要记录页面所曝光的内容,包括曝光对象,曝光类型等信息


2.2.4 启动数据
启动数据记录应用的启动信息


2.2.5 错误数据
应用使用过程中的错误信息,包括错误编号和错误信息
2.3 用户行为日志格式
埋点日志数据可分为两大类:普通页面埋点日志、启动日志
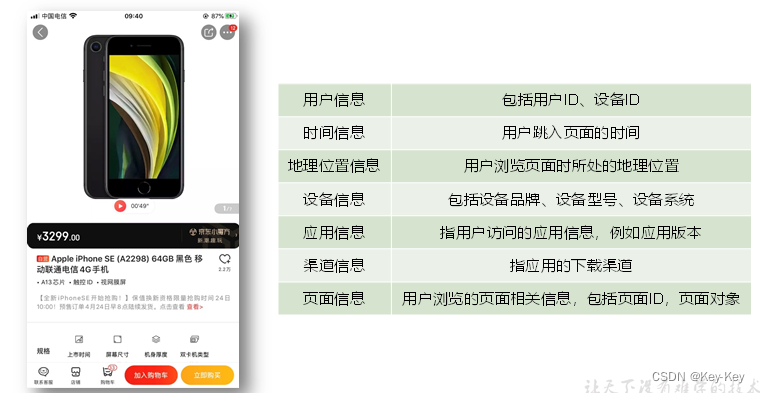
普通页面埋点日志包括:一个页面浏览记录、若干个用户在该页面所做的动作记录、若干个该页面的曝光记录、以及一个在该页面发生的报错记录。除上述行为信息,页面日志还包括了这些行为所处的各种环境信息,包括用户信息、事件信息、地理位置信息、设备信息、应用信息、渠道信息等。
1、普通页面埋点日志


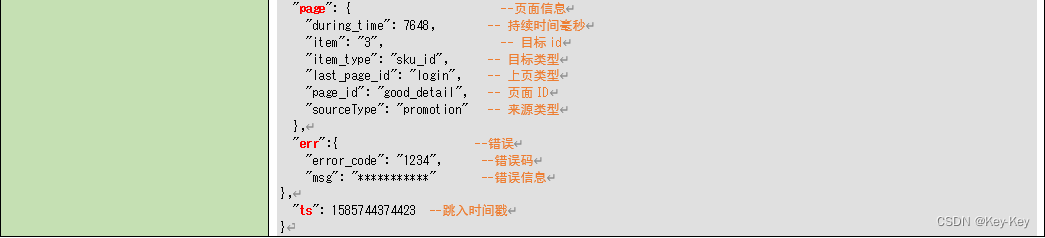
启动日志:以启动为单位,及一次启动行为,生成一条启动日志。一条完整的启动日志包括一个启动记录,一个本次启动时的报错记录,以及启动时所处的环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。

第 1 章:电商业务介绍
1.1 电商的业务流程
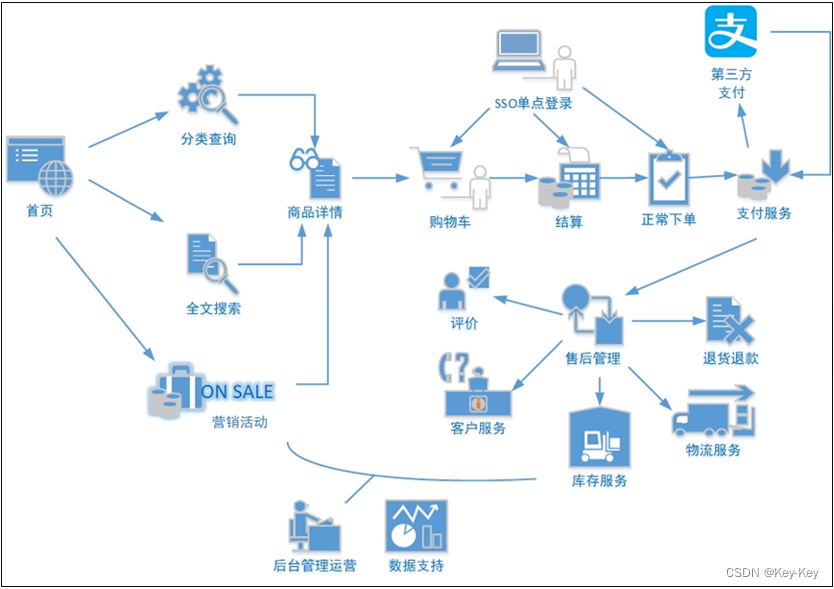
1、我们以一个普通用户的浏览足迹为例进行说明:
1)用户点开电商首页开始浏览,可能会通过分类查询或者通过全文搜索找到自己中意的商品,这些商品无疑都是存储在后台的管理系统中的
2)当用户寻址到自己中意的商品,可能会想要购买,将商品加入到购物车中,发现需要登录,登录后,对商品进行结算,这时候购物车的管理和商品订单信息的生成都会对业务数据库产生影响,会生成相应的订单数据和支付数据。
3)订单数据生成之后,还会对订单进行跟踪处理,直到订单全部完成。
2、主要业务流程包括:
1)用户前台浏览商品时的商品详情的管理
2)用户商品加入购物车进行支付时用户个人中心和支付服务的管理
3)用户支付完成后订单后台服务的管理
这些流程涉及到了十几个甚至几十个业务数据表,甚至更多
1.2 电商常识
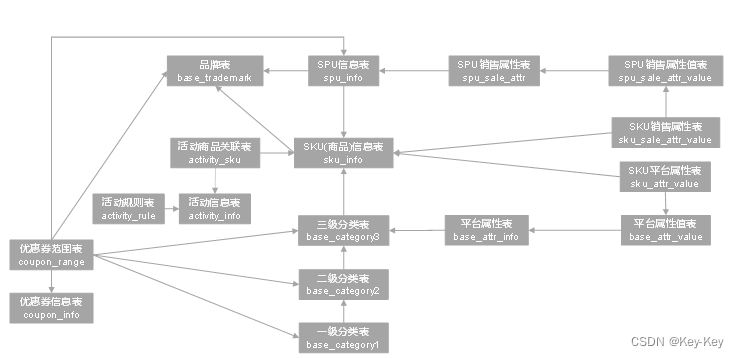
1.2.1 sku和spu
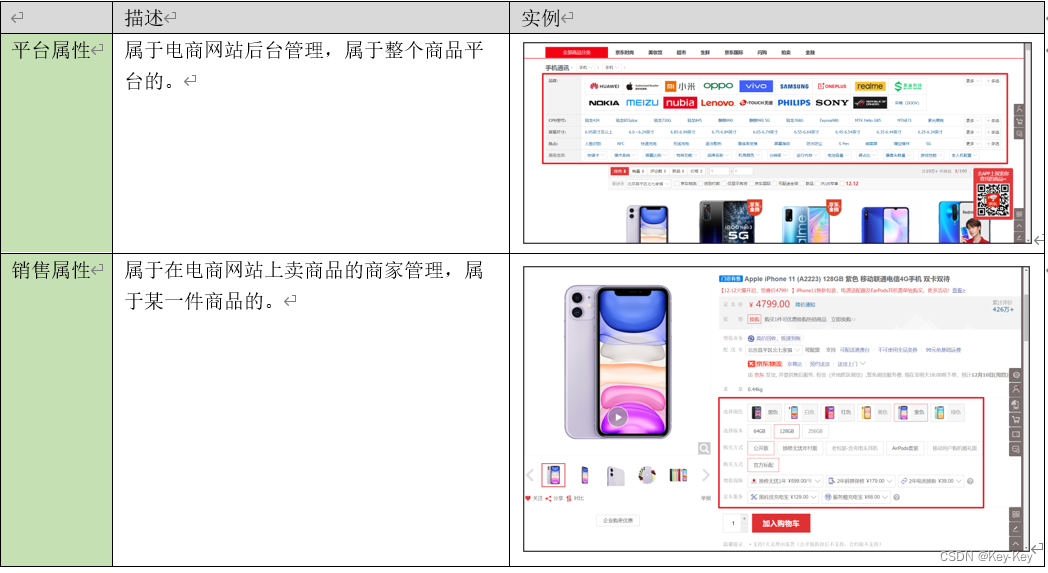
sku:库存量基本单位。产品统一编号的简称,每种商品均对应有唯一的sku号。sku表示一个商品
spu:商品信息集合的最小单位。一组可复用、易检索的标准化信息集合。spu表示一类商品,同一spu的商品可以共用商品图片、海报、销售属性等
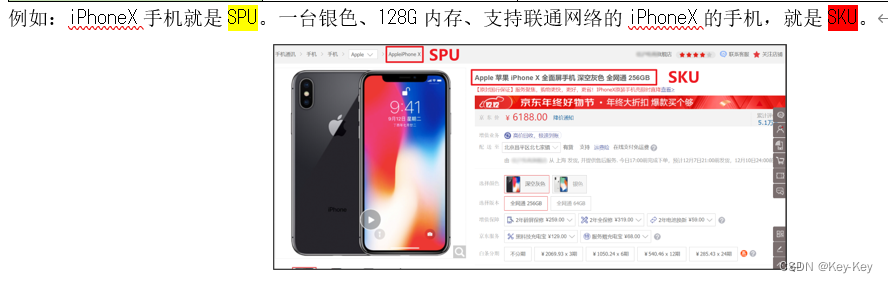
1.2.2 平台属性和销售属性
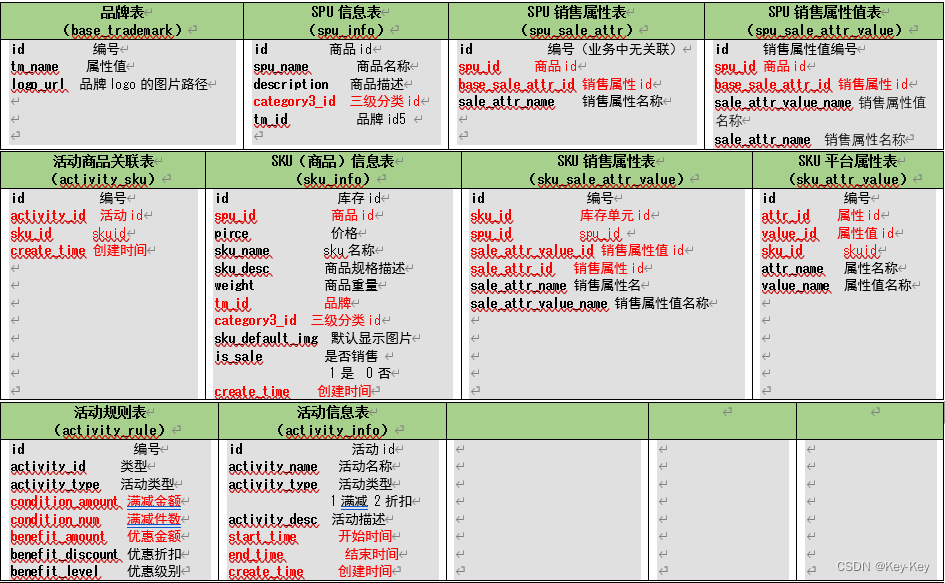
1.2.3 电商系统表结构
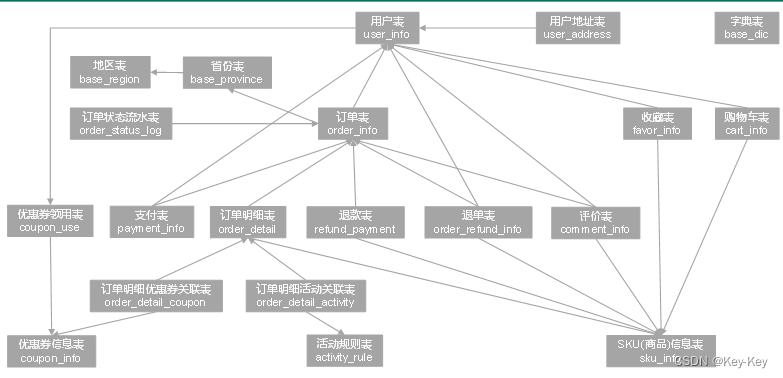
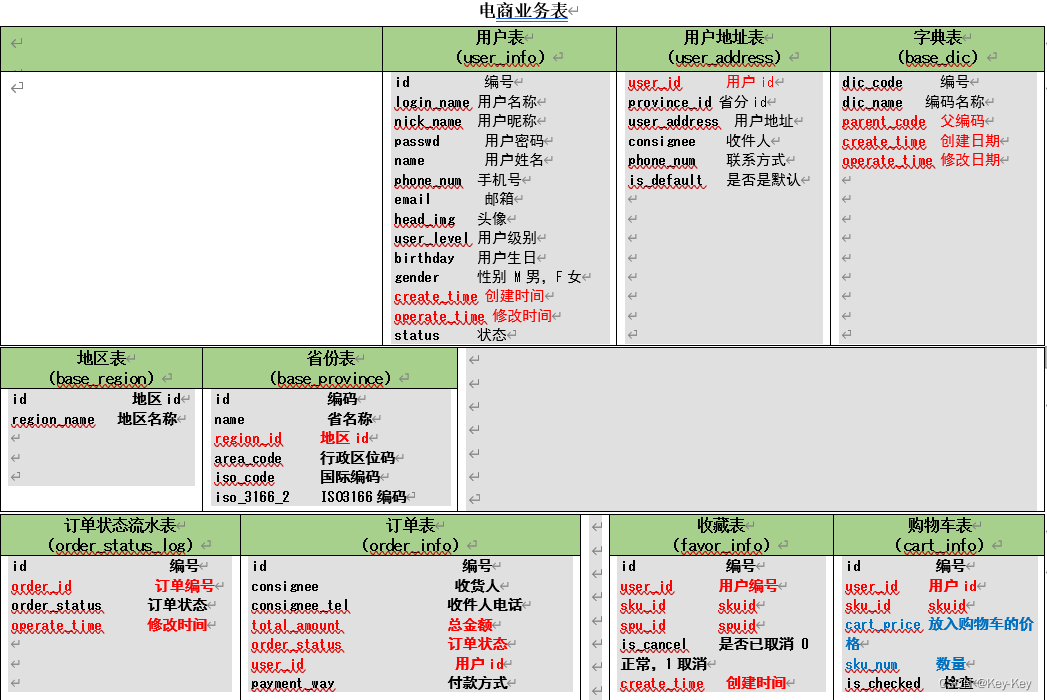
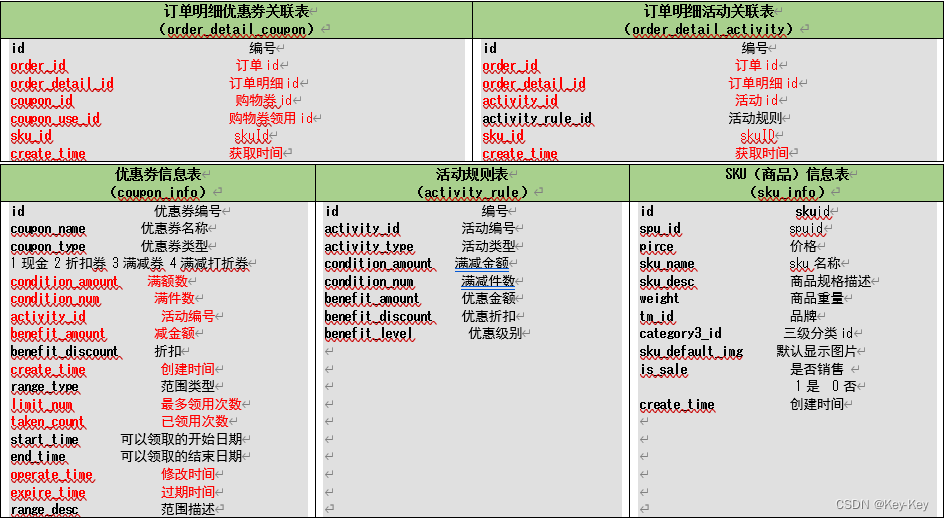
上面展示的就是本电商数仓系统涉及到的业务数据表结构关系。
1、这一共34张表,以订单表、用户表、sku商品表、活动表和优惠卷表为中心。
2、延申出了优惠卷领用表,支付流水表、活动订单表、订单详情表、订单状态表、商品品论表、编码字典表、退单表、spu商品表等。
3、其中的用户表提供用户的详细信息:支付流水表提供订单的支付详情;订单详情表提供订单的商品数量情况;商品表给订单详情表提供商品的详细信息。
本次讲解以此34各表为例,实际生产项目中,业务数据库中的表远远不止这些。



第 1 章:实时数仓同步数据
实时数仓用flink源源不断地从kafka中读取数据进行计算,所以不需要手动同步数据到实时数仓。
第 2 章:离线数仓同步数据
2.1 用户行为数据同步
2.1.1 数据通道
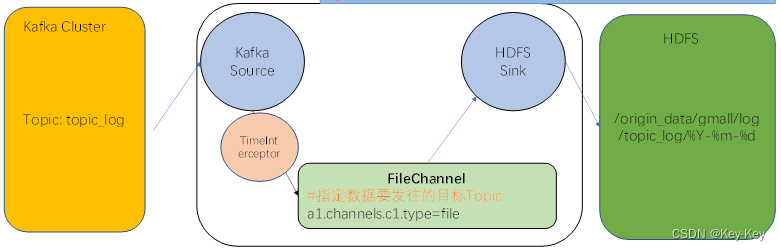
用户行为数据由flume从kafka直接同步到hdfs上,由于离线数仓采用hive地分区表按天统计,所以目标路径要包括一层日期。具体数据流向如图:
2.1.2 日志消费flume概述
1、日志消费flume在架构中的定位
日志消费flume主要用于消费kafka集群中topic_log的数据写入到hdfs中。
flume的集群规划如下:
日志消费flume我们将其安装部署在flume04上。
1)背景:安装规划,该flume需要将kafka中的topic_log的数据采集并发送到hdfs,并且需要对每天产生的用户行为数据进行分区存储,将不同日期的数据发送到hdfs中以不同日期命名的路径下。
2)flume插件选择:kafkasource、fliechannel、hdfssink
3)关键配置如下:
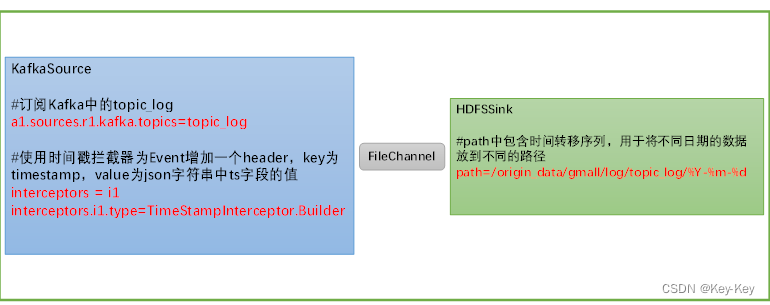
kafkasource:
#订阅kafka中的topic_log
a1.source.r1.kafka.topics=topic_log
#使用时间戳拦截器为event增加一个header,key为timestamp,value为json字符串中ts字段的值
interceptors=i1
interceptors.i1.type=timestampinterceptor.builder
hdfssink
#path中包括时间转移序列,用于将不同日期的数据放在不同的路径
path=/orgin_data/gmall/log/topic_log/%Y-%m-%d
2.1.3 日志消费flume配置分析
#订阅kafka中topic
a1.sources.r1.kafka.topics=topic_log
#path包括时间转义序列,将不同日期的数据放到不同的目录下
a1.sinks.k1.hdfs.path=/orgin_data/gmall/log/topic_log/%Y-%m-%d
#使用时间拦截器为event增加一个header,其中key是timestamp,value是json字符串中的ts字段的值
interceptors=i1
interceptors.i1.type=timestampinterceptor$builder
2.1.4 自定义flume拦截器
1、日志消费flume使用拦截器的目的-处理时间漂移问题
我们知道在使用hdfs sink时需要在event的header上设置时间戳属性。但是使用默认的timestrampinterceptor拦截器会默认使用linux系统时间,作为输出到hdfs路径的时间。
但是如果数据时23:59:59分钟产生的,flume消费kafka中数据时,有可能已经到了第二天了,那么这部分数据就会发送到第二天的hdfs路径。
我们希望根据日志里面的实际时间,发往hdfs的路径,所以我们需要自定义拦截器实现将日志里面的实际时间,提取出来,配置到event的header中。
注意:想要复现时间飘逸现象时,需要保证数据产生时间是在时间节点重新计算附件,如:按天的就需要在00:00前的一分钟以内;按分钟的就要在每分钟的前5秒以内。
2、自定义拦截器
1)创建类timestampinterceptor类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
/**
* @author leon
* @ClassName TimeStampInterceptor.java
* @createTime 2022年01月23日 13:30:00
*/
public class TimeStampInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 1. 获取Event的Body
String log = new String(event.getBody(), StandardCharsets.UTF_8);
// 2. 解析log为json对象
JSONObject jsonObject = JSONObject.parseObject(log);
// 3. 获取log中的时间戳
String ts = jsonObject.getString("ts");
// 4. 将时间戳属性配置到header中
event.getHeaders().put("timestamp",ts);
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
2)重新打包后,上传到hadoop104的flume根目录下lib文件夹下
[atguigu@hadoop104 lib]$ ls -al | grep flume-interceptor*
-rw-rw-r--. 1 atguigu atguigu 662479 1月 23 13:40 flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
2.1.5 编写日志消费flume的配置文件
1、编写配置日志消费flume的配置文件
在hadoop104的/opt/module/flume/job目录下创建flume-kafka-hdfs.conf
[atguigu@hadoop104 conf]$ vim flume-kafka-hdfs.conf
# 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
# source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder
# channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
# sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# 控制输出文件DataStream格式。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
2、配置优化
1)FIlechannel优化
(1)通过配置datadirs指向多个路径,每个路径对应不同的硬盘,增大flume吞吐量
Comma separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance
(2)checkpointdir和backupcheckpointdir也尽量配置到不同的硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupcheckpointdir恢复数据
2)hdfs sink优化
(1)hdfs存入大量小文件的影响
(2)hdfs小文件处理:配置三个参数hdfs.rollinterval=3600,hdfs.rollsize=134217728,hdfs.rollcount=0效果;当文件达到128m时会产生新的文件;当创建超过3600秒时会滚动产生新的文件。
2.1.6 编写日志消费flume启动停止脚本
1、在hadoop102下的atguima用户根目录/home/atguigu/bin下,创建f2.sh文件
[atguigu@hadoop102 bin]$ vim f2.sh
#! /bin/bash
# 1. 判断是否存在参数
if [ $# == 0 ];then
echo -e "请输入参数:nstart 启动日志消费flume;nstop 关闭日志消费flume;"&&exit
fi
case $1 in
"start"){
echo " --------启动 hadoop104 消费flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/job/flume-kafka-hdfs.conf --conf /opt/module/flume/conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/logs/flume.log 2>&1 &"
};;
"stop"){
echo "---------- 停止 hadoop104 上的 日志消费flume ----------"
flume_count=$(xcall jps -ml | grep flume-kafka-hdfs|wc -l);
if [ $flume_count != 0 ];then
ssh hadoop104 "ps -ef | grep flume-kafka-hdfs | grep -v grep | awk '{print $2}' | xargs -n1 kill -9"
else
echo " hadoop104 当前没有日志采集flume在运行"
fi
};;
esac
2、设置f2.sh文件的执行权限
[atguigu@hadoop102 bin]$ chmod +x f2.sh
2.1.7 用户行为数据同步测试
1、首先执行脚本f2.sh启动日志消费flume,消费kafka中topic_log的数据
[atguigu@hadoop102 module]$ f2.sh start
2、执行脚本f1.sh启动日志采集flume,采集日志文件到kafka中的topic_log
[atguigu@hadoop102 module]$ f1.sh start
3、执行脚本lg.sh启动日志数据模拟程序,生产模拟数据(需要修改配置文件)
[atguigu@hadoop102 module]$ lg.sh
4、查看各节点的运行程序
[atguigu@hadoop102 ~]$ xcall "jps -ml"
=============== hadoop102 ===============
11584 org.apache.hadoop.hdfs.server.namenode.NameNode
12256 org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer
6113 kafka.Kafka /opt/module/kafka/config/server.properties
11747 org.apache.hadoop.hdfs.server.datanode.DataNode
12420 gmall2020-mock-log-2021-01-22.jar
12453 sun.tools.jps.Jps -ml
5705 org.apache.zookeeper.server.quorum.QuorumPeerMain /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
10764 org.apache.flume.node.Application --conf-file /opt/module/flume/conf/flume-tailDir-kafka.conf --name a1
12031 org.apache.hadoop.yarn.server.nodemanager.NodeManager
=============== hadoop103 ===============
5584 kafka.Kafka /opt/module/kafka/config/server.properties
8355 org.apache.hadoop.yarn.server.nodemanager.NodeManager
7589 org.apache.flume.node.Application --conf-file /opt/module/flume/conf/flume-tailDir-kafka.conf --name a1
8213 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
5174 org.apache.zookeeper.server.quorum.QuorumPeerMain /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
8843 sun.tools.jps.Jps -ml
8046 org.apache.hadoop.hdfs.server.datanode.DataNode
8814 gmall2020-mock-log-2021-01-22.jar
=============== hadoop104 ===============
5651 org.apache.zookeeper.server.quorum.QuorumPeerMain /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
8627 sun.tools.jps.Jps -ml
8084 org.apache.hadoop.hdfs.server.datanode.DataNode
8265 org.apache.hadoop.yarn.server.nodemanager.NodeManager
6059 kafka.Kafka /opt/module/kafka/config/server.properties
8427 org.apache.flume.node.Application --conf-file /opt/module/flume/conf/flume-kafka-hdfs.conf --name a1
8173 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
5、查看对应hdfs上的目录下是否生成了新的数据文件
[atguigu@hadoop102 module]$ hdfs dfs -ls /origin_data/gmall/log/topic_log
Found 2 items
drwxr-xr-x - atguigu supergroup 0 2022-01-23 16:21 /origin_data/gmall/log/topic_log/2020-06-14
[atguigu@hadoop102 module]$ hdfs dfs -ls /origin_data/gmall/log/topic_log/2020-06-14
-rw-r--r-- 3 atguigu supergroup 544097 2022-01-23 16:20 /origin_data/gmall/log/topic_log/2020-06-14/log-.1642926024093
-rw-r--r-- 3 atguigu supergroup 1075832 2022-01-23 16:21 /origin_data/gmall/log/topic_log/2020-06-14/log-.1642926030114
[atguigu@hadoop102 module]$ hdfs dfs -cat /origin_data/gmall/log/topic_log/2020-06-14/log-.1642926024093 |zcat
……
{"common":{"ar":"110000","ba":"iPhone","ch":"Appstore","is_new":"0","md":"iPhone Xs Max","mid":"mid_125455","os":"iOS 13.2.3","uid":"65","vc":"v2.1.134"},"page":{"during_time":19258,"last_page_id":"home","page_id":"mine"},"ts":1592122835000}
……
2.2 业务数据同步策略
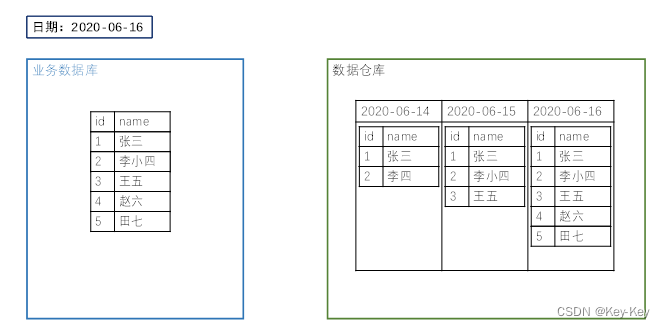
业务数据是数据仓库的重要数据来源,我们需要每日定时从业务数据库中抽取数据,传输到数据仓库中,之后再对数据进行分析统计。为保证统计结果的正确性,需要保证数据仓库中的数据与业务数据库是同步的,离线数仓的计算周期通常为天,所以数据同步周期也通常为天,即每天同步一次即可。
在同步业务数据时有两种同步策略:全量同步和增量同步
2.2.1 全量同步策略
1、解释:每日全量,就是每天都将业务数据库中的全部数据同步一份到数据仓库,是保证两侧数据同步的最简单的方式
2、适用:表数据量不大,且每天即会有新数据加入,也会有旧的数据修改
3、编码字典表、品牌表、商品三级分类表、商品二级分类表、商品一级分类表、优惠规则表、活动表、活动参与商品表、加购表、商品收藏表、优惠卷表、sku商品表、spu商品表
2.2.2 增量同步策略
解释:每日增量,就是每天只将业务数据中的新增及变化的数据同步到数据仓库中。
适用:表数据量大,且每天只会有新的数据插入的场景。
特点:采用每日增量的表,通常会在首日先进行一个全量同步。
例如:退单表、订单状态表、支付流水表、订单详情表、活动与订单关联表、商品评论表
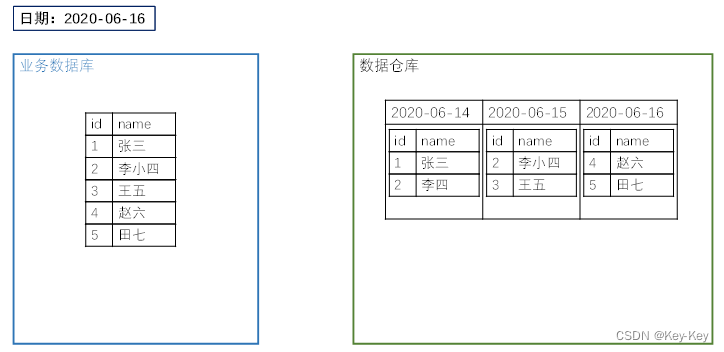
2.2.3 数据同步策略的选择
两种策略都能保证数据仓库和业务数据库的数据同步,那应该选择哪个呢?

结论:若业务数据量比较大,且每天的数据变化比例还比较低,这时应该选择增量同步,否则采用全量同步。
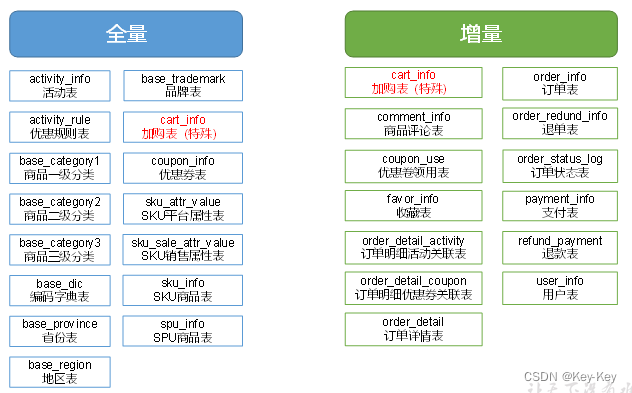
2.2.4 同步工具概述
1、种类繁多的数据同步工具中,大致可以分为两大类
1)基于Select查询的离线、批量同步工具,代表:datax、sqoop
2)基于数据库表述变更日志(mysql的binlog)的实时流式同步工具,代表:maxwell、canal
2、上述同步工具的全量或增量同步适用如下

3、同步工具之间对增量同步不同方案的对比

本项目中,全量同步采用datax,增量同步采用maxwell
注:由于后续数仓建模需要,cart_inso需进行全量同步和增量同步
2.3 全量表数据同步
2.3.1 数据同步工具datax部署
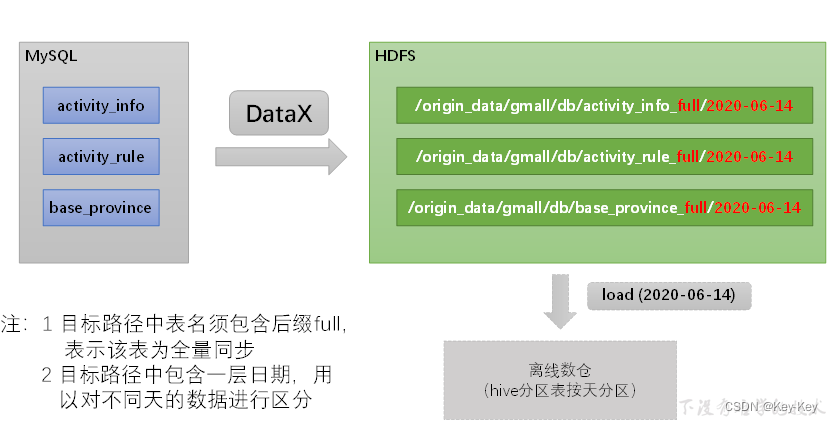
2.3.2 数据通道
全量表数据有datax从mysql业务数据库中直接同步到hdfs,具体数据流向如下表
注:
1、目标路径中表名需包含后缀full,表示该表为全量同步
2、目标路径中包含一层日期,用以对不同天的数据进行区分
2.3.3 编写datax配置文件
我们需要为每张全量表编写一个datax的json配置文件,此处为activity_Info为例,编辑配置文件如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"activity_name",
"activity_type",
"activity_desc",
"start_time",
"end_time",
"create_time"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/gmall"
],
"table": [
"activity_info"
]
}
],
"password": "jianglai",
"splitPk": "",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "activity_name",
"type": "string"
},
{
"name": "activity_type",
"type": "string"
},
{
"name": "activity_desc",
"type": "string"
},
{
"name": "start_time",
"type": "string"
},
{
"name": "end_time",
"type": "string"
},
{
"name": "create_time",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "t",
"fileName": "activity_info",
"fileType": "text",
"path": "${targetdir}",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
这个配置文件定义了一个从 MySQL 数据库读取特定表和列的数据,并将其写入到 HDFS 的过程,同时涵盖了数据类型、连接信息、输出格式和压缩方式等详细信息。这种配置通常用于数据仓库的数据抽取、转换和加载(ETL)过程。

注:我们需要对不同天的数据加以分区,故path参数的值配置为动态传入参数,名为targetdir
2、测试配置文件
[atguigu@hadoop102 datax]$ python bin/datax.py job/activity_info.json -p"-DtargetDir=/origin_data/gmall/db/activity_info_full/2020-06-14"
3、执行时如果报错如下:
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[HdfsWriter-02], Description:[您填写的参数值不合法.]. - 您配置的path: [/origin_data/gmall/db/activity_info/2020-06-14] 不存在, 请先在hive端创建对应的数据库和表.
4、这文件一个个写太麻烦了,每天的日期都不一样,怎么办呢?
2.3.4 datax配置文件生成脚本
1、为了方便起见,我们适用脚本gen_import_config.py批量生成datax的配置文件,脚本内容如下:
# coding=utf-8
import json
import getopt
import os
import sys
import MySQLdb
#MySQL相关配置,需根据实际情况作出修改
mysql_host = "hadoop102"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "你的密码"
#HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "hadoop102"
hdfs_nn_port = "8020"
#生成配置文件的目标路径,可根据实际情况作出修改
output_path = "/opt/module/datax/job/import"
def get_connection():
return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)
def get_mysql_meta(database, table):
connection = get_connection()
cursor = connection.cursor()
sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"
cursor.execute(sql, [database, table])
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall
def get_mysql_columns(database, table):
return map(lambda x: x[0], get_mysql_meta(database, table))
def get_hive_columns(database, table):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"decimal": "string",
"double": "double",
"float": "float",
"binary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string"
}
return mappings[mysql_type]
meta = get_mysql_meta(database, table)
return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)
def generate_json(source_database, source_table):
job = {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": mysql_user,
"password": mysql_passwd,
"column": get_mysql_columns(source_database, source_table),
"splitPk": "",
"connection": [{
"table": [source_table],
"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,
"fileType": "text",
"path": "${targetdir}",
"fileName": source_table,
"column": get_hive_columns(source_database, source_table),
"writeMode": "append",
"fieldDelimiter": "t",
"compress": "gzip"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:
json.dump(job, f)
def main(args):
source_database = ""
source_table = ""
options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])
for opt_name, opt_value in options:
if opt_name in ('-d', '--sourcedb'):
source_database = opt_value
if opt_name in ('-t', '--sourcetbl'):
source_table = opt_value
generate_json(source_database, source_table)
if __name__ == '__main__':
main(sys.argv[1:])

这个脚本是为了简化 DataX 数据迁移任务的配置过程。它自动从 MySQL 数据库中获取表的元数据,然后生成相应的 DataX 配置文件,用于将数据从 MySQL 迁移到 HDFS。
2、安装python mysql驱动
由于需要适用python访问mysql数据库,故需要安装驱动,命令如下
[atguigu@hadoop102 bin]$ sudo yum install -y MySQL-python
3、python脚本使用说明
python gen_import_config.py -d database -t table
这样虽然能调用python脚本生成指定表的datax的json配置文件,但是我的表很多,总不能每个表都执行吧
4、创建gen_import_config.sh脚本
#!/bin/bash
python ~/bin/gen_import_config.py -d gmall -t activity_info
python ~/bin/gen_import_config.py -d gmall -t activity_rule
python ~/bin/gen_import_config.py -d gmall -t base_category1
python ~/bin/gen_import_config.py -d gmall -t base_category2
python ~/bin/gen_import_config.py -d gmall -t base_category3
python ~/bin/gen_import_config.py -d gmall -t base_dic
python ~/bin/gen_import_config.py -d gmall -t base_province
python ~/bin/gen_import_config.py -d gmall -t base_region
python ~/bin/gen_import_config.py -d gmall -t base_trademark
python ~/bin/gen_import_config.py -d gmall -t cart_info
python ~/bin/gen_import_config.py -d gmall -t coupon_info
python ~/bin/gen_import_config.py -d gmall -t sku_attr_value
python ~/bin/gen_import_config.py -d gmall -t sku_info
python ~/bin/gen_import_config.py -d gmall -t sku_sale_attr_value
python ~/bin/gen_import_config.py -d gmall -t spu_info
5、为gen_import_config.sh脚本赋予执行权限
[atguigu@hadoop102 bin]$ chmod +x gen_import_config.sh
6、执行gen_import_config.sh脚本生成配置文件
[atguigu@hadoop102 bin]$ gen_import_config.sh
7、观察配置文件
[atguigu@hadoop102 bin]$ ll /opt/module/datax/job/import/
总用量 60
-rw-rw-r-- 1 atguigu atguigu 957 10月 15 22:17 gmall.activity_info.json
-rw-rw-r-- 1 atguigu atguigu 1049 10月 15 22:17 gmall.activity_rule.json
-rw-rw-r-- 1 atguigu atguigu 651 10月 15 22:17 gmall.base_category1.json
-rw-rw-r-- 1 atguigu atguigu 711 10月 15 22:17 gmall.base_category2.json
-rw-rw-r-- 1 atguigu atguigu 711 10月 15 22:17 gmall.base_category3.json
-rw-rw-r-- 1 atguigu atguigu 835 10月 15 22:17 gmall.base_dic.json
-rw-rw-r-- 1 atguigu atguigu 865 10月 15 22:17 gmall.base_province.json
-rw-rw-r-- 1 atguigu atguigu 659 10月 15 22:17 gmall.base_region.json
-rw-rw-r-- 1 atguigu atguigu 709 10月 15 22:17 gmall.base_trademark.json
-rw-rw-r-- 1 atguigu atguigu 1301 10月 15 22:17 gmall.cart_info.json
-rw-rw-r-- 1 atguigu atguigu 1545 10月 15 22:17 gmall.coupon_info.json
-rw-rw-r-- 1 atguigu atguigu 867 10月 15 22:17 gmall.sku_attr_value.json
-rw-rw-r-- 1 atguigu atguigu 1121 10月 15 22:17 gmall.sku_info.json
-rw-rw-r-- 1 atguigu atguigu 985 10月 15 22:17 gmall.sku_sale_attr_value.json
-rw-rw-r-- 1 atguigu atguigu 811 10月 15 22:17 gmall.spu_info.json
8、测试脚本生成的datax配置文件
我们以activity_Info为例,测试用脚本生成的配置文件是否可用
1)在hdfs上创建目标路径
由于datax同步任务要求目标路径提前存在,故需要手动创建路径,当前activity_info表的目标路径应为/origin_data/gmall/db/activity_info_full/2020-06-14
[atguigu@hadoop102 bin]$ hadoop fs -mkdir -f /origin_data/gmall/db/activity_info_full/2020-06-14
2)执行datax同步命令
[atguigu@hadoop102 bin]$ python /opt/module/datax/bin/datax.py -p"-Dtargetdir=/origin_data/gmall/db/activity_info_full/2020-06-14" /opt/module/datax/job/import/gmall.activity_info.json
3)观察同步结果
观察hdfs目标路径/origin_data/gmall/db/activity_info/2020-06-14下的文件内容
[atguigu@hadoop102 datax]$ hadoop fs -cat /origin_data/gmall/db/activity_info_full/2020-06-14/* | zcat
2022-03-02 14:05:05,527 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1 联想专场 3101 联想满减 2020-10-21 18:49:12 2020-10-31 18:49:15
2 Apple品牌日 3101 Apple品牌日 2020-06-10 00:00:00 2020-06-12 00:00:00
3 女神节 3102 满件打折 2020-03-08 00:00:00 2020-03-09 00:00:00
9、全量表数据同步脚本
1)为方便使用以及后续的任务调度,此处编写一个全量表数据同步脚本mysql_to_hdfs_full.sh
#!/bin/bash
# 定义datax的根目录
DATAX_HOME=/opt/module/datax
# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
#处理目标路径,此处的处理逻辑是,如果目标路径不存在,则创建;若存在,则清空,目的是保证同步任务可重复执行
handle_targetdir() {
hadoop fs -test -e $1
if [[ $? -eq 1 ]]; then
echo "路径$1不存在,正在创建......"
hadoop fs -mkdir -p $1
else
echo "路径$1已经存在"
fs_count=$(hadoop fs -count $1)
content_size=$(echo $fs_count | awk '{print $3}')
if [[ $content_size -eq 0 ]]; then
echo "路径$1为空"
else
echo "路径$1不为空,正在清空......"
hadoop fs -rm -r -f $1/*
fi
fi
}
#数据同步
import_data() {
datax_config=$1
target_dir=$2
handle_targetdir $target_dir
python $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config
}
# 根据传入的表名,处理不同的表
case $1 in
"activity_info")
import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
;;
"activity_rule")
import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date
;;
"base_category1")
import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date
;;
"base_category2")
import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date
;;
"base_category3")
import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date
;;
"base_dic")
import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date
;;
"base_province")
import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date
;;
"base_region")
import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date
;;
"base_trademark")
import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date
;;
"cart_info")
import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date
;;
"coupon_info")
import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date
;;
"sku_attr_value")
import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date
;;
"sku_info")
import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date
;;
"sku_sale_attr_value")
import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date
;;
"spu_info")
import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date
;;
"all")
import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date
import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date
import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date
;;
esac
这个脚本的目的是使得数据同步的过程自动化和标准化。它允许用户指定特定的表或一组表来进行数据同步,同时处理日期和目标路径的逻辑,确保数据同步的准确性和可重复性。
2)为mysql_to_hdfs_full.sh脚本增加执行权限
[atguigu@hadoop102 bin]$ chmod +x mysql_to_hdfs_full.sh
3)测试同步脚本
[atguigu@hadoop102 bin]$ mysql_to_hdfs_full.sh all 2020-06-14
4)检查同步结果
查看hdfs目标路径是否出现了全量表数据,全量表共15张
全量表同步逻辑比较简单,只需要每日执行全量表数据同步脚本mysql_to_hdfs_full.sh即可
2.4 增量表数据同步
2.4.1 数据通道
增量表数据同步数据通道如下所示:
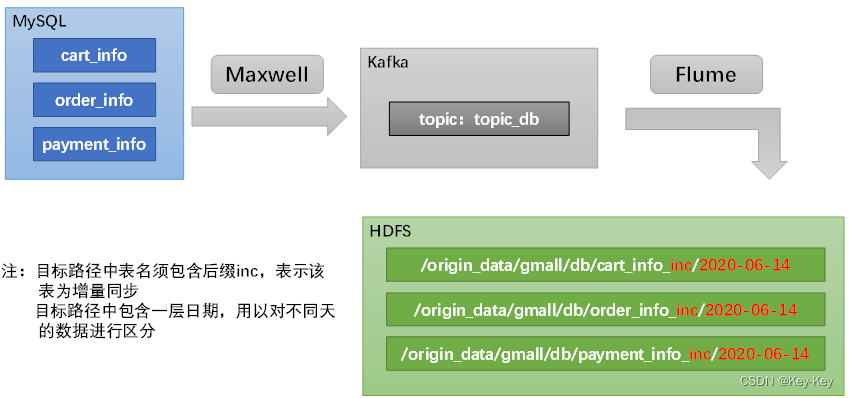
注:
1、目标路径中表明需包含后缀inc,表示该表为锃亮同步
2、目标路径中包含一层日期,用以对不同天的数据进行区分
2.4.3 flume配置
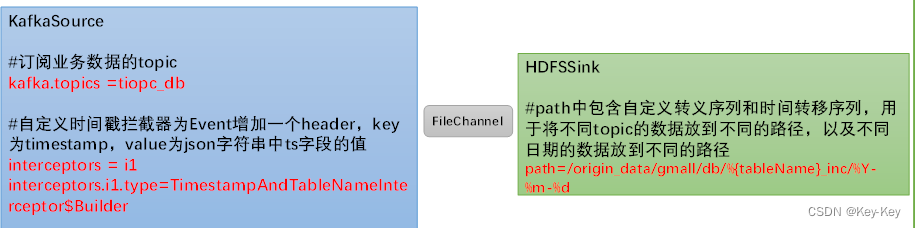
1、需求:此处flume需要将maxwell采集kafka topic中的业务变更数据传输到hdfs
2、需求分析
1)flume需要用到的组件是:kafkasource和hdfssink,channel选择filechannel
2)kafkasource需要订阅kafka中1个topic:topic_db
3)hdfssink需要将不同数据写到不同的路径,路径中还用该包含一层日期,用于分区每天的数据
2.4.4 配置示意图
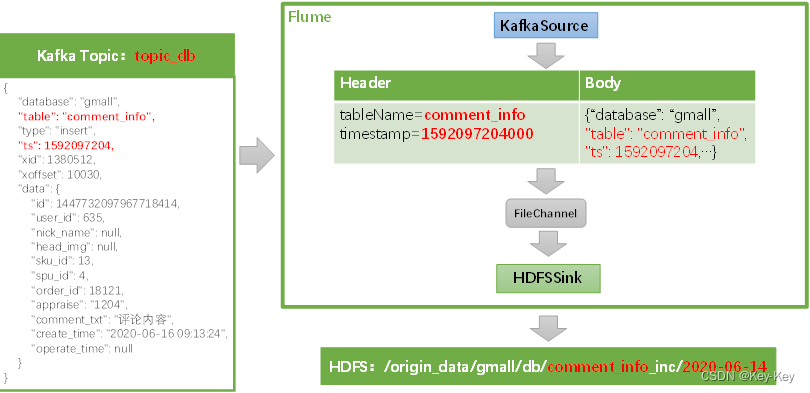
采用kafka topic中的业务变更数据到hdfs的flume,我们部署在hadoop104
2.4.5 flume配置
1、编写flume配置文件kafka_to_hdfs_db.conf
[atguigu@hadoop104 job]$ vim kafka_to_hdfs_db.conf
# agent
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# sources
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.db.TimestampAndTableNameInterceptor $Builder
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
这个配置文件的作用是从 Kafka 主题 topic_db 中读取数据,经过处理后(如添加时间戳和表名),暂存到文件系统中,并最终将数据以压缩格式写入到 HDFS 的指定路径。
2.4.6 配置flume拦截器
项目的pom.xml文件配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
创建com.atguigu.gmall.flume.interceptor.db包,并在该包下创建timestampandtablenameinterceptor类
public class TimestampAndTableNameInterceptor implements Interceptor {
@Override
public void initialize() { }
/**
* 拦截单个事件
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
// 1. 获取事件header
Map<String, String> headers = event.getHeaders();
// 2. 获取解析body
String body = new String(event.getBody(), StandardCharsets.UTF_8);
// 3. 使用fastjson,将body字符串转化为JSONObject对象
JSONObject jsonObject = JSONObject.parseObject(body);
// 4. 获取数据中的时间戳
Long ts = jsonObject.getLong("ts");
// 5. Maxwell输出的数据的ts字段时间单位是秒,HDFSSink要求的时间单位是毫秒
String timeMills = String.valueOf(ts * 1000);
// 6. 获取body数据中的table的值
String tableName = jsonObject.getString("table");
// 7. 将时间戳添加到事件头部
headers.put("timestamp",timeMills);
// 8. 将table的名字插入到事件头部
headers.put("tableName", tableName);
return event;
}
/**
* 拦截批量事件
* @param events
* @return
*/
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() { }
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new TimestampAndTableNameInterceptor ();
}
@Override
public void configure(Context context) {
}
}
}
这个拦截器主要用于处理从源(如 Kafka)接收的事件,特别是处理 JSON 格式的消息体。
它从每个事件的 JSON 消息体中提取特定的信息(时间戳和表名)并将这些信息添加到事件的 header 中,这对于后续的事件处理(如根据时间戳或表名路由事件)非常有用。
打包,并将带有依赖的jar包放到flume的lib目录下

2.4.7 通道测试
1、启动zookeeper集群、kafka集群
2、启动hadoop104上的flume,采集kafka_topic中的业务变更数据到hdfs
[atguigu@hadoop102 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_db.conf -Dflume.root.logger=INFO,console
3、生成模拟数据
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
4、观察hdfs上的目标路径是否有增量表的数据出现
2.4.8 数据目标路径的日期说明
仔细观察,会发现目标路径中的日期,并非模拟数据的业务日期,而是当前日期。这是由于maxwell输出的json字符串中的ts字段的值,是数据的变动日期。而真实场景下,数据的业务日期与变动日期应当是一致的。
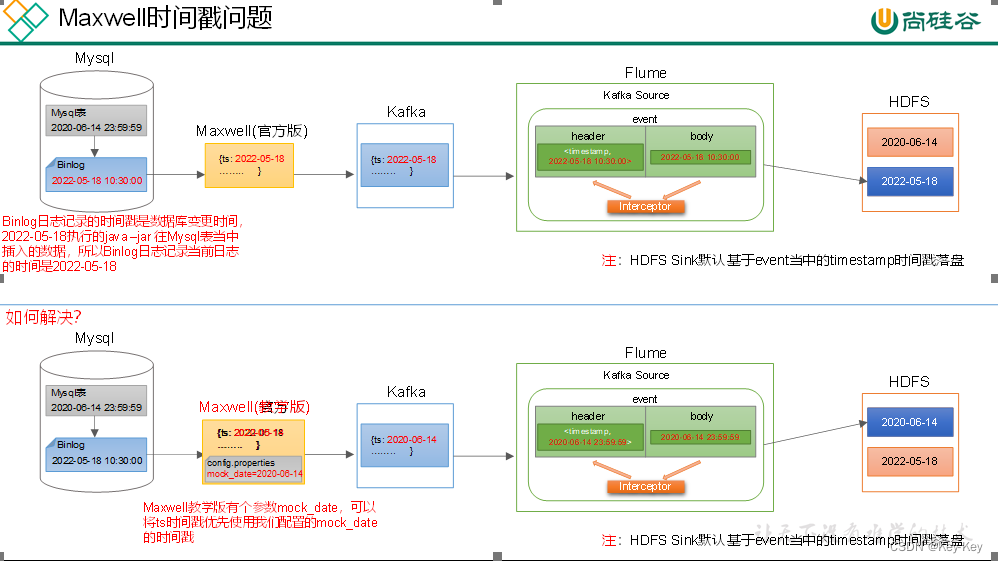
这张图展示了一个数据流的架构,说明了如何从 MySQL 数据库通过 Maxwell 和 Kafka 将数据流式传输到 HDFS,同时使用 Flume 作为传输介质。Maxwell 作为 MySQL 的 binlog 复制器,捕获 MySQL 数据库的更改(如插入、更新和删除操作)并将这些更改作为消息发布到 Kafka 队列中。然后,Flume 从 Kafka 中读取这些消息,并将它们传输到 HDFS。
此处为了模拟真实环境,对maxwell源码进行了改动,增加了一个参数mock_date,该参数的作用就是指定maxwell输出json字符串的ts时间戳的日期,接下来进行测试。
1、修改maxwell配置文件config.properties,增加mock_date参数,如下
该日期需和/opt/module/db_log/application.properties中的mock.date参数保持一致
mock_date=2020-06-14
注:该参数仅供学习使用,修改该参数后重启maxwell才能生效。
2、重启maxwell
[atguigu@hadoop102 bin]$ maxwell.sh restart
3、重新生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
4、观察hdfs目标路径日期是否正常
2.4.9 编写业务数据变更flume采集启动停止脚本
为方便使用,编写一个启动关闭业务数据变更采集的flume脚本
1、再用户目录下的bin目录下编写脚本f3.sh
[atguigu@hadoop102 bin]$ vim f3.sh
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 业务数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 业务数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_db.conf | grep -v grep |awk '{print $2}' | xargs -n1 kill"
;;
esac
这个脚本是一个Bash脚本,用于初始化数据库中的所有增量表。它的主要功能是使用Maxwell工具来导入特定表的数据到Kafka中。Maxwell 是一个 MySQL binlog 到 Kafka 的转换器,它可以捕获数据库的更改并将这些更改作为消息发送到 Kafka。
2、增加脚本权限
[atguigu@hadoop102 bin]$ chmod +x f3.sh
2.4.11 测试同步脚本
1、清理历史数据
为方便查看结果,现在将hdfs上之前同步的增量表数据删除
[atguigu@hadoop102 ~]$ hadoop fs -ls /origin_data/gmall/db | grep _inc | awk '{print $8}' | xargs hadoop fs -rm -r -f
2、执行同步脚本
[atguigu@hadoop102 bin]$ mysql_to_kafka_inc_init.sh all
3、检查同步结果
观察hdfs上是否重新出现增量表数据
2.5 采用通道启动/停止脚本
在/home/atguigu/bin目录下创建脚本cluster.sh
[atguigu@hadoop102 bin]$ vim /home/atguigu/bin/cluster.sh
#!/bin/bash
case $1 in
"start"){
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
hdp.sh start
#启动 Kafka采集集群
kf.sh start
#启动采集 Flume
f1.sh start
#启动日志消费 Flume
f2.sh start
#启动业务消费 Flume
f3.sh start
#启动 maxwell
mxw.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Maxwell
mxw.sh stop
#停止 业务消费Flume
f3.sh stop
#停止 日志消费Flume
f2.sh stop
#停止 日志采集Flume
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
hdp.sh stop
#停止 Zookeeper集群
zk.sh stop
};;
esac
脚本编辑后,赋予脚本执行权限chmod+x cluster.sh
第 4 章:数仓准备
4.1 hive安装
1、把apache-hive~bin.tar.gz上传到linux的/opt/software目录下
2、将/opt/software/目录下的apache-hive~bin.tar.gz到/opt/module/目录下面
[atguigu@hadoop102 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
3、修改解压后的目录名称为hive
[atguigu@hadoop102 module]$ mv apache-hive-3.1.2-bin/ /opt/module/hive
4、修改/etc/profile.d/my_env.sh文件,将Hive的/bin目录添加到环境变量
[atguigu@hadoop102 hive]$ sudo vim /etc/profile.d/my_env.sh
……
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
[atguigu@hadoop102 hive]$ source /etc/profile
5、在hive根目录下,使用/bin目录中的schematool命令初始化hive自带的derby元数据库
[atguigu@hadoop102 hive]$ bin/schematool -dbType derby -initSchema
6、执行上述初始化元数据库时,会发现存在jar包冲突问题,现象如下
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver
Metastore connection User: APP
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.derby.sql
解决jar冲突问题,只需要将hive的/lib目录下的log4j-slf4j-impl-2.10.0.jar重命名即可
[atguigu@hadoop102 hive]$ mv lib/log4j-slf4j-impl-2.10.0.jar lib/log4j-slf4j-impl-2.10.0.back
4.2 将hive元数据配置到mysql
4.2.1 拷贝驱动
将mysql的jdbc驱动拷贝到hive的lib目录下
[atguigu@hadoop102 software]$ cp mysql-connector-java-5.1.37.jar /opt/module/hive/lib
4.2.2 配置metastore到mysql
在$hive_home/conf目录下新建hive-site.xml文件
[atguigu@hadoop102 hive]$ vim conf/hive-site.xml
添加如下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>你的密码</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- Hive元数据存储的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
这个配置文件的主要作用是设置 Hive 与其元数据存储(通常是一个 RDBMS,如 MySQL)的连接配置,定义 Hive 在 HDFS 中的存储位置,以及配置一些与元数据和安全性相关的选项。
4.2.3 hive初始化元数据库
1、登录mysql
[atguigu@hadoop102 module]$ mysql -uroot -p你的密码
2、新建hive元数据库
mysql> create database metastore;
mysql> quit;
3、初始化hive元数据库
[atguigu@hadoop102 hive]$ bin/schematool -initSchema -dbType mysql -verbose
4.2.4 启动hive
1、启动hive客户端
[atguigu@hadoop102 hive]$ bin/hive
2、查看一下数据库
hive (default)> show databases;
OK
database_name
default
4.2.5 修改元数据库字符集
hive元数据库的字符集默认为latin1,由于其不支持中文字符,故若建表语句中包含中文注释,会出现乱码现象。如需要解决乱码问题,需做一下修改。
1、修改hive元数据库中存储注释的字符的字符集为utf-8
1)字段注释
mysql> alter table metastore.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
2)表注释
mysql> alter table metastore.TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
2、修改hive-site.xml中jdbc url,如下
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
原文地址:https://blog.csdn.net/key_honghao/article/details/135727913
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_61565.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







