文章目录
一、观察线程不安全
下面我们来举个例子:
我们大家都知道,在单线程中,以下的代码100%是正确的。
public class Demo2 {
// 此处定义一个 int 类型的变量
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
//对count变量进行自增5w次
//线程t1
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
t1.start();
t1.join();
System.out.println("count:" + count);
}
}
//执行结果:5w
但是,两个线程,并发的进行上述循环,此时逻辑可能就出现问题了。
public class Demo2 {
// 此处定义一个 int 类型的变量
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
//对count变量进行自增5w次
//线程t1
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
//线程t2
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
t1.start();
t2.start();
//如果没有这两个join,肯定不行!线程还没自增完,就开始打印了,很可能打印出来的count是0
t1.join();
t2.join();
// 预期结果应该是10w
System.out.println("count:" + count);
}
}
//运行结果:和10w相差很大,且每次执行的结果都不一样
上述这样的情况就是非常典型的线程安全问题。这种情况就是bug!!
只要实际结果和预期的结果不符合,就一定是bug。
二、线程安全的概念
想给出一个线程安全的确切定义是复杂的,但我们可以这样认为:
如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线程安全的。
三、线程不安全的原因
1. 关于线程不安全的解释

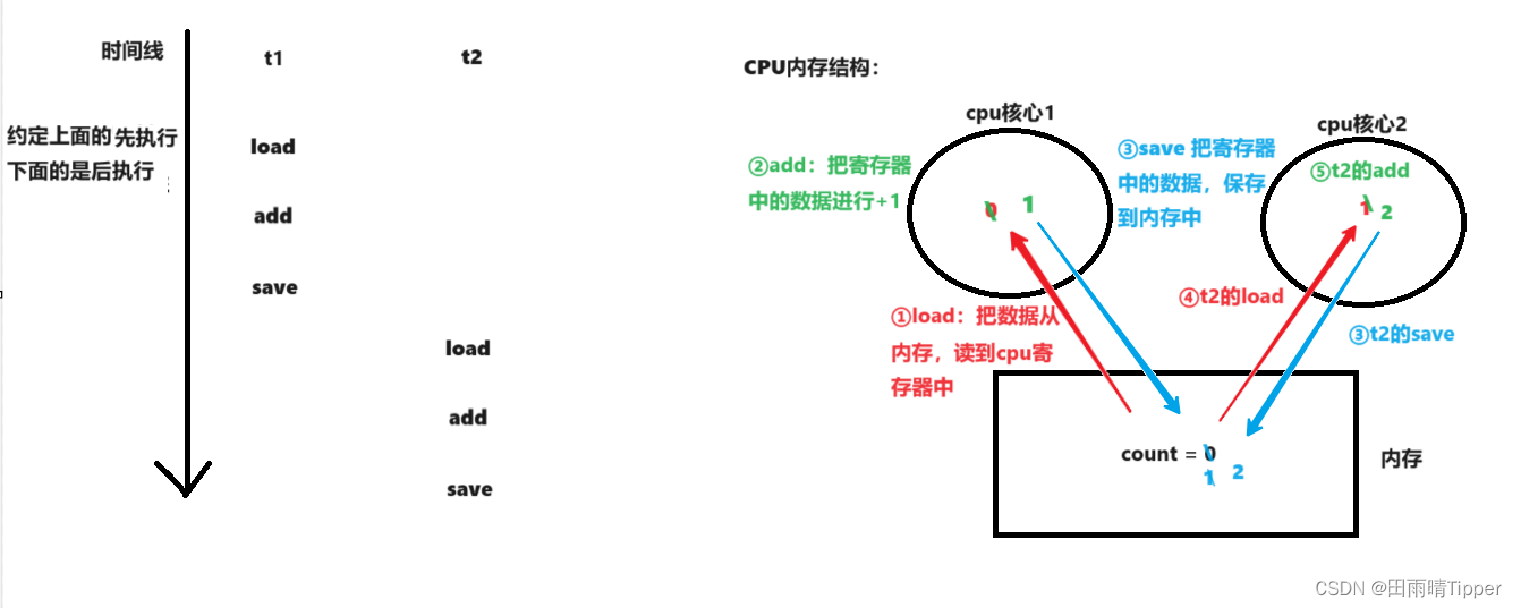
- 站在cpu的角度上,count++这个操作本质上是由cpu通过三个指令来实现的:
① load 把数据从内存,读到cpu寄存器中;
② add 把寄存器中的数据进行+1;
③ save 把寄存器中的数据,保存到内存中。 - 第二个角度:如果是多个线程执行上述代码,由于线程之间的调度顺序,是“随机”的,就会导致在有些调度顺序下,上述的逻辑就会出现问题。
因为是随机的,所以可能会有以下顺序:
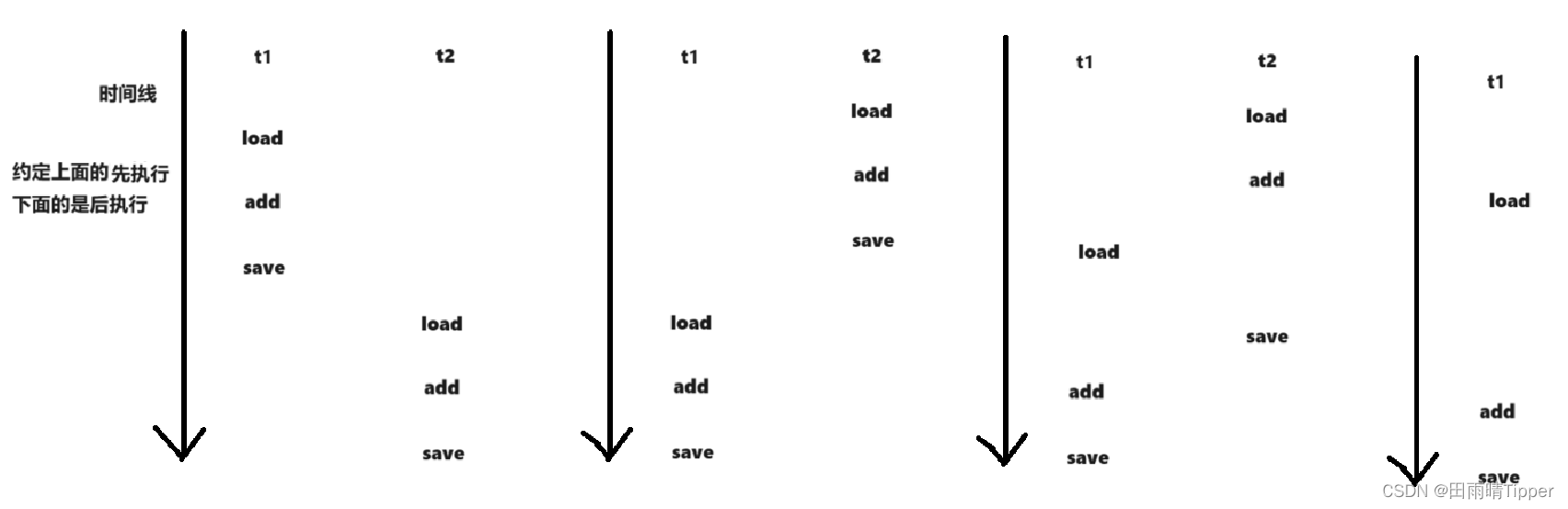
除去这四种的顺序还有无数种的执行情况,因为可能存在t1执行1次,t2执行n次的情况。
结合上述讨论,就意识到了,在多线程程序中,最困难的一点是:线程的随机调度,使两个线程执行逻辑的先后顺序,存在诸多可能。我们必须要保证在所有可能的情况下,代码都是正确的!!
在上述这些排列顺序中,有的执行结果是正确的,有的则是存在问题的如:
【执行结果正确的情况】
【执行结果错误的情况】
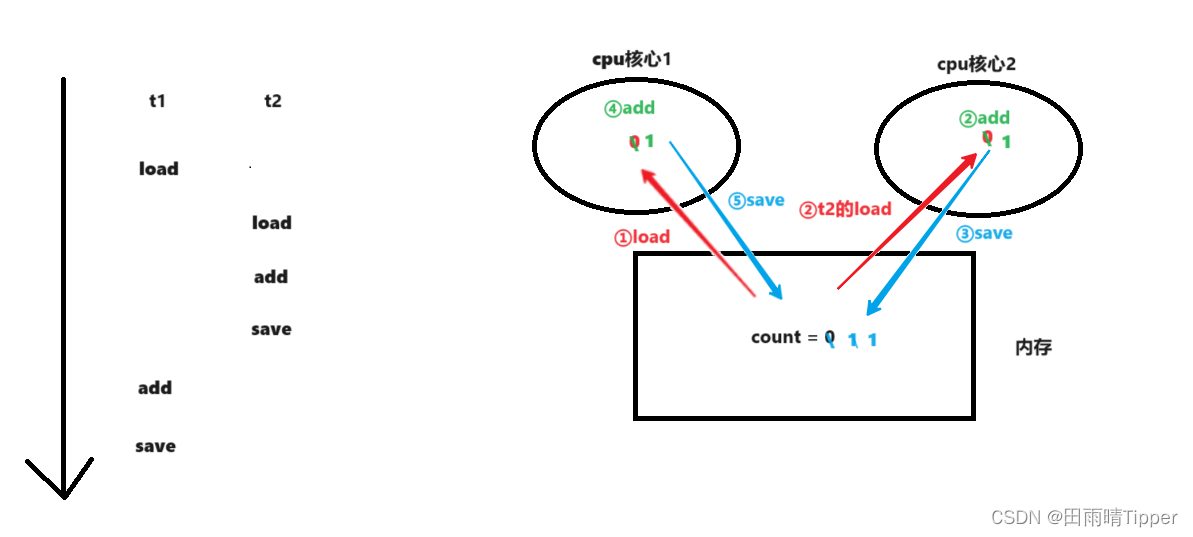
上述顺序执行完毕之后,bug 就出现了!
两个线程,分别自增一次,预期应该是得到2,实际上只有1,这就相当于自增过程中,两个线程的结果是没有往上累加的。
由于我们也不知道,这这5w次自增的过程中,有多少次是按照正确的方式自增的,有多少次,是无法正确自增的,因此最终的结果,就是一个“随机”值,并且这个随机值,一定是小于10w的值!
【总结】产生线程安全问题的原因为以下6种:
1. 抢占式执行
操作系统中,线程的调度顺序是随机的(抢占式执行),罪魁祸首,万恶之源。
调度顺序是随机得,这个是系统内核里实现得,最初搞多任务操作系统的大佬,制定了“抢占式执行”大的基调,在这个基调下,想要做出调整是非常困难的,所以根据这个原因解决抢占式执行是行不通。
2. 修改共享数据
两个线程,针对一个变量进行修改。
① 一个线程针对一个变量修改,可以;
② 两个线程针对不同变量修改,可以;
③ 两个线程针对一个变量读取,可以。
想要解决此原因带来的线程安全问题,有些情况下,可以通过调整代码结构,规避上述问题,但是也有很多情况,调整不了。
3. 原子性
此处给定的count++ 就属于是 非原子的操作(先读,再修改)
类似的,如果一段逻辑中,需要根据一定的条件来决定是否修改,也是存在类似的问题。
(假设 count++是原子的,比如有个cpu指令,一次完成上述的三步)
什么是原子性:
我们把一段代码想象成一个房间,每个线程就是要进入这个房间的人。如果没有任何机制保证,A进入房间之后,还没有出来;B是不是也可以进入房间,打断A在房间里的隐私,这个就是不具备原子性的。
【解决方式】
那我们应该如何解决这个问题呢?是不是只要给房间加一把锁,A 进去就把门锁上,其他人是不是就进不来了。这样就保证了这段代码的原子性了。
就是想办法让count++这里的三步走,成为“原子”的,即加锁,MySQL并发执行事务,隔离性。
4. 可见性
可见性指, 一个线程对共享变量值的修改,能够及时地被其他线程看到。
当前代码不涉及。
5. 指令重排序问题
当前代码不涉及。
四、解决之前的线程不安全的问题
上述我们分析得到的结论是,通过“加锁”就能解决上述问题。
如何给Java种的代码加锁呢?
其中最常用的方法,就是synchronized,在synchronized使用的时候,要搭配一个代码块{};
进入{就会加锁},出了{}就会解锁,在已经加锁的状态中,另一个线程尝试同样加这个锁,就会产生“锁冲突/锁竞争”,后一个线程就会阻塞等待。一直等到前一个线程解锁为止。
【语法】
synchronized() {
}
其中:()中需要表示一个用来加锁的对象,这个对象是什么不重要,重要的是通过这个对象来区分两个线程是否在竞争同一个锁。
如果两个线程是在针对同一个对象加锁,就会有锁竞争;
如果不是针对同一个对象加锁,就不会有锁竞争,仍然是并发执行!
PS:可以把锁想象成一个girl,你向girl表白,把她追到手了,你就相当于给此girl加锁了。
如果另一个小哥,也尝试追同一个girl,他就得阻塞等待,等你俩分手,他才有机会。
但是这个小哥如果追的是其他的单身girl,就不会收到你这边的影响!
public class Demo2 {
// 此处定义一个 int 类型的变量
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
//定义锁对象
Object locker = new Object();
//对count变量进行自增5w次
//线程t1
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker) {
count++;
}
}
});
//线程t2
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
//和线程t1使用的是同一个对象加锁
synchronized (locker) {
count++;
}
}
});
t1.start();
t2.start();
//如果没有这两个join,肯定不行!线程还没自增完,就开始打印了,很可能打印出来的count是0
t1.join();
t2.join();
// 预期结果应该是10w
System.out.println("count:" + count);
}
}
//运行结果
count:100000 //结果正确!
使用此种方式编写代码,两个线程的执行过程就会相互影响。相当于:
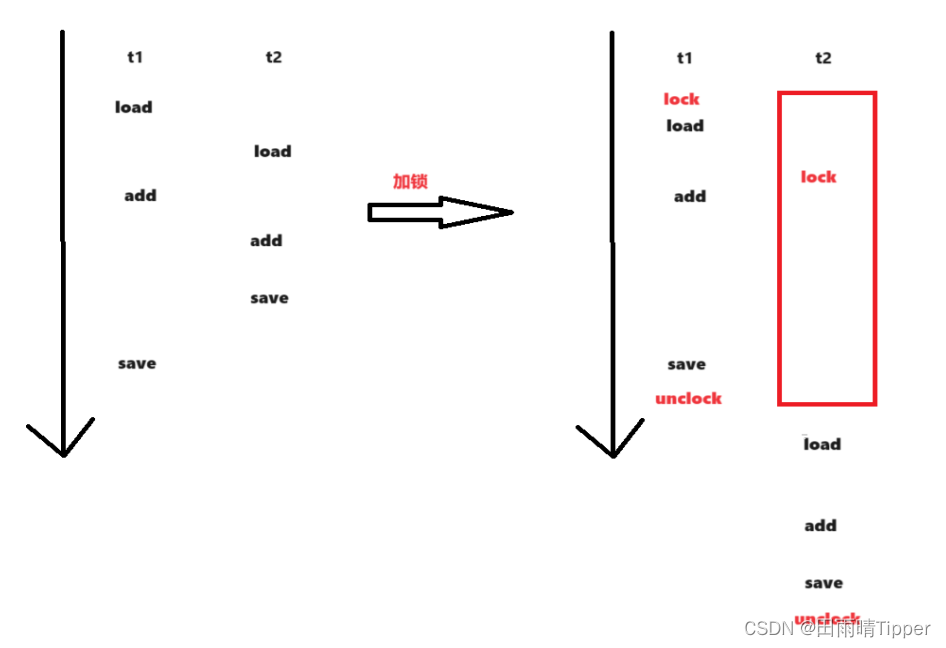
t2 线程由于锁的竞争,导致 lock 操作出现阻塞,阻塞到 t1 线程 unlock 之后,t2 的 lock 才算执行完。
阻塞避免了t2 的 load、add、save 和第一个线程操作出现穿插,形成这种“串行”执行的效果。此时线程安全问题,就迎刃而解了!!
【注意】
如果是针对不同的对象加锁,我们这两个锁操作,中间就不会有这样的阻塞等待,不会有锁竞争,仍然会出现互相穿插的情况,那么线程安全问题仍然存在。
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
Object locker = new Object();
Object locker2 = new Object();
//对count变量进行自增5w次
//线程t1
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker) {
count++;
}
}
});
//线程t2
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
//和线程t1使用的是同一个对象加锁
synchronized (locker2) {
count++;
}
}
});
t1.start();
t2.start();
//如果没有这两个join,肯定不行!线程还没自增完,就开始打印了,很可能打印出来的count是0
t1.join();
t2.join();
// 预期结果应该是10w
System.out.println("count:" + count);//结果错误
}
}
//运行结果
小于10w
五、synchronized 关键字(两个线程同时修改一个变量)
1. synchronized 的特性
(1)互斥
synchronized修饰的是一个代码块,同时会指定一个“锁对象” ,它会起到互斥效果, 某个线程执行到某个对象的 synchronized 中时, 其他线程如果也执行到同一个对象 synchronized 就会阻塞等待。
- 进入 synchronized 修饰的代码块, 相当于对该对象进行加锁;
- 退出 synchronized 修饰的代码块, 相当于对该对象进行解锁。
synchronized void inchrease(锁对象) {//进入方法内部,相当于针对当前对象“加锁”
count++;
}//执行方法完毕,相当于针对当前对象“解锁”
锁对象到底用哪个对象无所谓,对象是谁不重要,重要的是两个线程加锁的对象,是否为同一个对象!
这里的规则意义只有一个:
当两个线程同时尝试对一个对象加锁,此时就会出现“锁竞争”,一旦竞争出现,一个线程能够拿到锁,继续执行;一个线程拿不到锁,就会阻塞等待,等待前一个线程释放锁之后,它才会有机会拿到锁,继续执行。
这样的规则,本质上是把“并发执行”——>“串行执行”。此时就不会出现“穿插”的情况了。
synchronized 用的锁是存在对象头里的。

Java的一个对象,对应的内存空间中,除了你自己定义的一些属性以外,还有一些自带的属性,这个自带的属性,就是对象头。其中对象头中,其中就有属性表示当前对象是否已经加锁。
也可以粗略的理解成,每个对象在内存中存储的时候,都有一块内存表示当前的“锁定”状态。
(2)刷新内存
刷新内存(存疑,很多资料有的说有,有的说没有,此处了解一下)
- 获得互斥锁;
- 从主内存拷贝变量的最新副本到工作的内存;
- 执行代码;
- 将更改后的共享变量的值刷新到主内存;
- 释放互斥锁。
(3)可重入(synchronized的重要特性!)
所谓的可重入锁,指的是一个线程连续针对一把锁,加锁两次且不会出现死锁。满足这个要求,就是“可重入”,不满足就是“不可重入”。
synchronized同步块对同一条线程来说是可重入的,不会出现自己把自己锁死的问题。
下篇博客我将详细的解释死锁问题!这里我们简单介绍一下。
【理解把自己锁死】
一个线程没有释放锁,然后又尝试再次加锁。
// 第一次加锁, 加锁成功
lock();
// 第二次加锁, 锁已经被占用, 阻塞等待.
lock();
按照之前对于锁的设定,第二次加锁的时候,就会阻塞等待。直到第一次的锁被释放,才能获取到第二个锁。但是释放第一个锁也是由该线程来完成,结果这个线程已经躺平了,啥都不想干了,也就无
法进行解锁操作。这时候就会死锁。
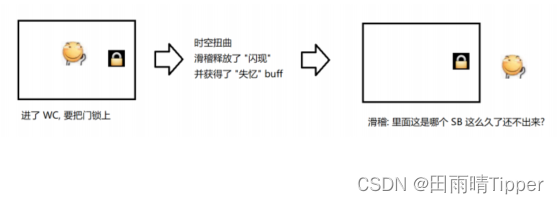
这样的锁称为“不可重入锁”。
Java中的synchronized是可重入锁,因此没有上面的问题。
【代码示例】
在下面的代码中:
- increase 和 increase2 两个方法都加了 synchronized,此处的 synchronized 都是针对 this 当前对象锁的。
- 在调用 increase2 的时候,先加了一次锁,执行到 increase 的时候, 又加了一次锁。(上个锁还没释放, 相当于连续加两次锁)
这个代码是完全没问题的,因为synchronized是可重入锁。
static class Counter {
public int count = 0;
synchronized void increase() {
count++;
}
synchronized void increase2() {
increase();
}
}
在可重入锁的内部,包含了 “线程持有者” 和 “计数器” 两个信息。
- 如果某个线程加锁的时候,发现锁已经被人占用,但是恰好占用的正式是自己,那么仍然可以继续获取到锁,并让计数器自增。
- 解锁的时候计数器递减为 0 的时候, 才真正释放锁.。(才能被别的线程获取到)。
2. synchronized 使用示例
synchronized 除了修饰代码块之外,还可以修饰一个实例方法,或者修饰一个静态方法。
【实例方法】
class Counter {
public int count;
//实例方法1
synchronized public void increase() { //使用this为锁对象
count++;
}
//实例方法2
public void increase2() { //这两种写发是等价的,可以理解为上述代码是这个的简化版本
synchronized (this) {
count++;
}
}
}
public class Demo3 {
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
}
//运行结果:100000
其中,实例方法1和实例方法2是等价的,可理解为实例方法1为实例方法2的简化版本。
【静态方法】
如果是静态方法,相当于是针对类对象加锁。
//静态方法1
synchronized public static void increase3() {
}
//静态方法2
public static void increase4() {
synchronized (Counter.class) {
}
}
静态方法1和2也是等价的,相当于1是2的简化解法。
3. Java标准库中的线程安全类
Java 标准库中很多都是线程不安全的,这些类可能会涉及到多线程修改共享数据, 又没有任何加锁措施。
- ArrayList
- LinkedList
- HashMap
- TreeMap
- HashSet
- TreeSet
- StringBuilder
但是还有一些是线程安全的,使用了一些锁机制来控制。
- Vector (不推荐使用)
- HashTable (不推荐使用)
- ConcurrentHashMap
- StringBuffer
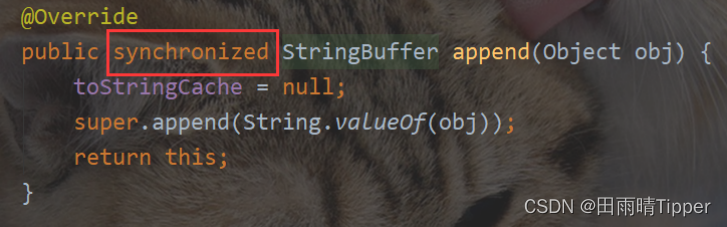
StringBuffer 的核心方法都带有synchronized .
还有的虽然没有加锁,,但是不涉及 “修改”,仍然是线程安全的:String。
4. 总结
synchronized使用规则上并不复杂,抓住一个原则:两个线程针对同一个对象加锁,就会产生锁竞争。
此外,可重入这个特征引出死锁,我们下篇博客详细介绍!
六、volatile 关键字(一个线程读,一个线程修改)
volatile涉及到 保证内存可见性 和 禁止指令重排序。
1. volatile 能保证内存可见性
计算机运行的程序/代码,经常要访问数据。这些依赖的数据,往往会存内存中。(定义一个变量,变量就是在内存中),CPU在使用这个变量的时候,就会把这个内存中的数据,先读出来,放到CPU的寄存器中,再参与运算(load)。
CPU读取内存的这个操作,其实非常慢!CPU在进行大部分操作,都很快,一旦操作到读/写内存,此时速度一下就降下来了。
【重要结论】内存可见性:
为了解决上述问题,提高效率,此时编译器,就可能对代码做出优化,把一些本来要读内存的操作,优化成读取寄存器,减少读内存的次数,也就可以提高整体程序的效率了。
但是!编译器也不是万能的,它对代码做出优化的判断可能会判断错误,进一步导致运行结果错误。
volatile 修饰的变量,能够保证“内存可见性”。
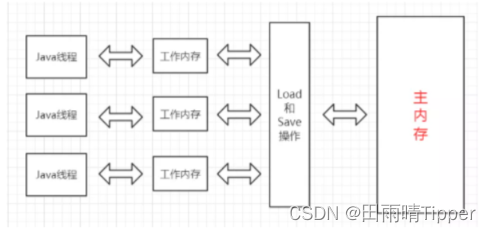
其中:
主内存,就是我们平常所说的内存;
工作内存,就是寄存器。
代码在写入 volatile 修饰的变量的时候,
- 改变线程工作内存中volatile变量
- 将改变后的副本的值从工作内存刷
代码在读取 volatile 修饰的变量的时候,
- 从主内存中读取volatile变量的最新值到线程的工作内存中
- 从工作内存中读取volatile变量的副本
前面我们讨论内存可见性时说了,直接访问工作内存(实际是 CPU 的寄存器或者 CPU 的缓存),速度非常快,但是可能出现数据不一致的情况。
加上 volatile ,强制读写内存。速度是慢了,但是数据变的更准确了。
【代码示例】
在这个代码中:
- 创建两个线程 t1 和 t2;
- t1 中包含一个循环,这个循环以 isQuit == 0 为循环条件;
- t2 中从键盘读入一个整数,并把这个整数赋值给 isQuit;
- 预期当用户输入非 0 的值的时候,t1 线程结束。
public static int isQuit = 0;
public static void main(String[] args) {
Thread t1 = new Thread(()->{
while (isQuit == 0) {
//循环里啥也没干
//此时意味着这个循环,一秒钟就会执行很多次
}
System.out.println("t1 退出!");
});
t1.start();
Thread t2 = new Thread(()->{
System.out.println("请输入isQuit:");
Scanner sc = new Scanner(System.in);
//一旦用户输入的值,不为0,此时就会使 t1 线程执行结束。
isQuit = sc.nextInt();
});
t2.start();
}
//执行效果
//当用户输入非0值时,t1线程循环不会结束。(这显然是个bug)
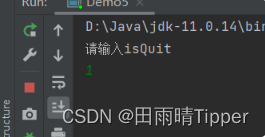
此时代码预期效果:
用户输入非0值之后,t1线程要退出。但是实际上当我们真正输入1的时候,此时t1线程并没有结束!
通过jconsole也能看到,t1线程正在执行。RUNNABLE状态!
由于多线程引起的,也是线程安全问题!此时就是“内存可见性”情况引起的!
如果给 isQuit 加上volatile
private volatile static int isQuit = 0;
//执行结果
//当用户输入非0值时,t1线程循环能够立即结束。
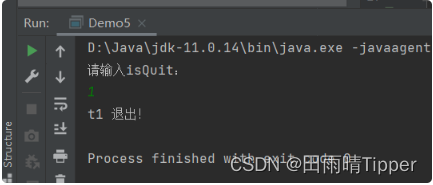
这里的内存可见性解释(了解):
在isQuit == 0中:
① load 读取内存中 isQuit 的值到寄存器中;
② 通过 cmp 指令比较寄存器的值是否是0,决定是否需要循环。
由于这个循环,循环速度非常快,短时间内就会进行大量的循环,也就是进行大量的 load 和 cmp 的操作。
此时,编译器 JVM 就发现了,虽然进行了这么多次 load,但是load出来的结果都是一样的,并且 load 操作又非常的浪费时间,一次 load 花的时间相当于上万次 cmp 了。
所以编译器就做了一个大胆的决定!(编译器优化)只是第一次循环的时候读了内存,后续都不在读内存了,而是直接从寄存器中,取出 isQuit 的值了。
编译器优化是希望能够提高程序的效率,但是提高效率的前提是逻辑不变,此时由于修改了 isQuit 代码是另一个线程的操作,编译器没有正确的判定。它以为没人修改 isQuit,而做出了优化,引起了bug。
这个问题,就成为“内存可见性”问题。
volatile 就是解决方案!
在多线程环境下,编译器对于是否要进行这样的优化,判定不一定准,就需要程序猿通过volatile 关键字,告诉编译器,你不要优化!(优化是算的块了,但是算的不准!)
2. volatile 不保证原子性
volatile和synchronized都对线程安全起到一定的积极作用,但是各司其职,他们有着本质上的区别,synchronized 能够保证原子性,volatile 保证的是内存可见性,是不能保证原子性的。
如,上述count++代码,用volatile,他最后的结果也是不正确的,不是10w。
且 synchronized 也能保证内存可见性,有这种说法,但是存疑,这里要注意一下。
原文地址:https://blog.csdn.net/T2283380276/article/details/135684260
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_61669.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!