本文介绍: 结构化的数据文件映射为一张表。
最近学习hive 时候,在做一个实操案例,具体大概是这样子的:
我在dataGip里建了一个表,然后在hadoop集群创建一个文本文件里面存储了数据库表的数据信息,然后把他上传到hdfs后,dataGrip那个表也同步了我上传到hdfs数据信息,这一下子让我有点懵了,为什么可以实现同步呢?
首先hive的定义为,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,Hive中每张表的数据存储在HDFS
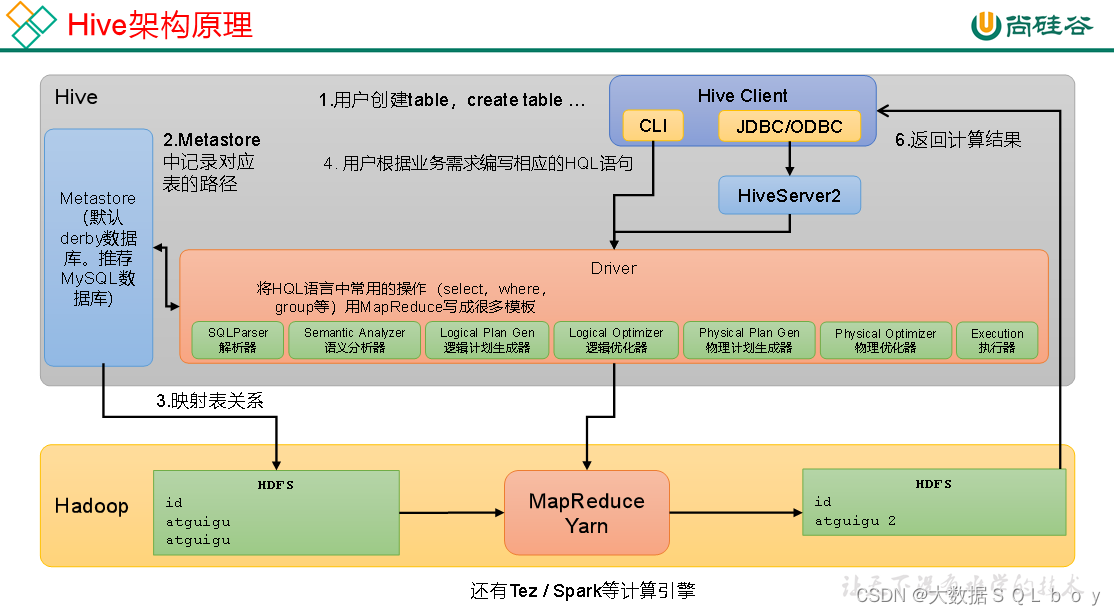
另外对于hiveserver2访问
这里关键在于理解真正的表数据信息在hdfs,而在dataGrip的表实际上是根据matestored 元数据以及hdfs数据信息映射到数据库得到的一张张表。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。