本文介绍: 传统的模型融合方法分为集成的方法和权重合并的方法,这两种方法在以往的NLP的比赛中非常常见,是一种提分手段。然而,上述两种方法都需要预训练或者微调相应的模型。在大模型场景下,对每个源模型都进行初始化成本太高,为了减少初始化源LLM的成本,使集成后的模型受益于所有源LLMs的优势。因此,本文介绍了一种知识融合的方法用来进行大模型的融合。FUSELLM提供了一种LLMs的集成方法,为大模型融合提供了一个trick,或许未来LLM比赛爆发的时候,最后大家涨分涨不动了,可以考虑下试一试这个trick。
前言
传统的模型融合方法分为集成的方法和权重合并的方法,这两种方法在以往的NLP的比赛中非常常见,是一种提分手段。然而,上述两种方法都需要预训练或者微调相应的模型。在大模型场景下,对每个源模型都进行初始化成本太高,为了减少初始化源LLM的成本,使集成后的模型受益于所有源LLMs的优势。因此,本文介绍了一种知识融合的方法用来进行大模型的融合。

1 背景与概念
1.1因果语言建模(Causal Language Modeling, CLM)
因果语言建模是训练语言模型的一种目标,它旨在最小化模型预测下一个词的负对数似然。在传统的语言模型训练中,这个目标是通过比较模型生成的词概率分布与实际文本中的词(以one-hot编码表示)来实现的。CLM训练目标可以表示为:
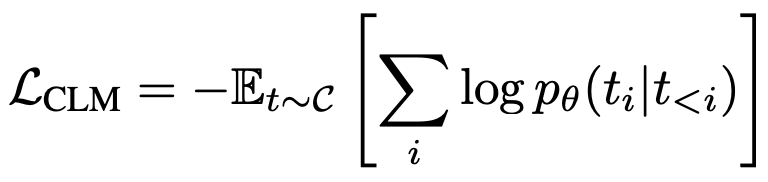
p
1.2 概率分布矩阵
2 LLMs融合
2.1 知识外化
2.2 训练
2.3 概率分布矩阵对齐

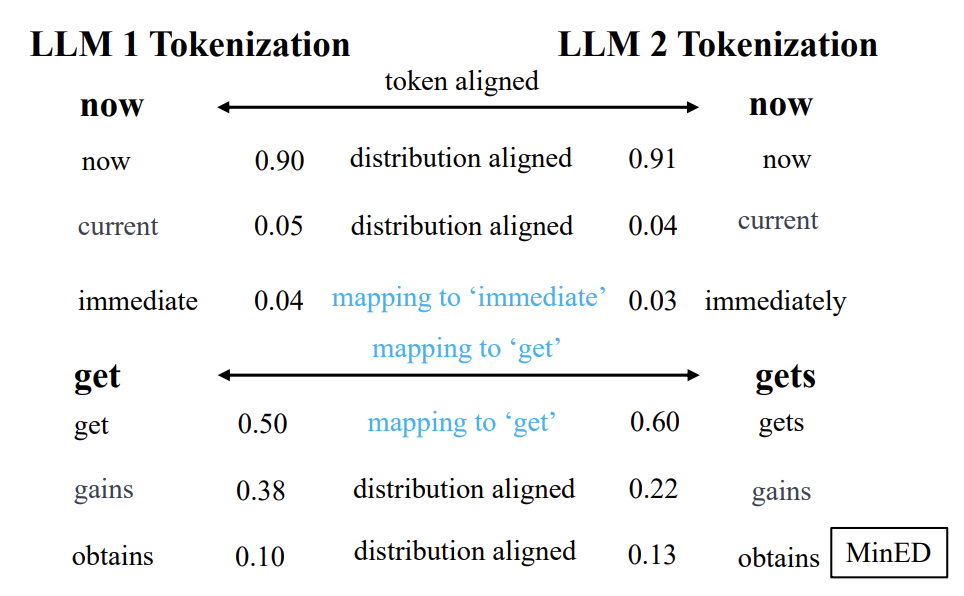
2.4 融合策略
2.5 融合算法

总结
参考文献
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






