本文介绍: 交叉熵损失函数(Cross-entropy loss function)是一种用于衡量模型输出与实际标签之间差异的损失函数。在机器学习中,交叉熵损失函数通常用于分类问题中,特别是在逻辑回归和神经网络等模型中。对于一个逻辑回归函数:损失函数公式:简化后的公式:根据损失函数的定义,当的值与目标值越接近,损失函数值越小,预测越准确。所以:
一、引言
逻辑回归中的损失函数通常采用的是交叉熵损失函数(cross-entropy loss function)。在逻辑回归中,我们通常使用sigmoid函数将线性模型的输出转换为概率值,然后将这些概率值与实际标签进行比较,从而计算损失。
二、交叉熵损失函数
在逻辑回归解决二分类问题的学习中,我们认识到逻辑回归的输出结果可以看成输入时输出为正例(
)的概率。
于是我们便想到可以通过比较模型预测的概率分布和实际标签之间的差异来衡量模型的准确性。在信息论中,交叉熵用来比较两个概率分布之间的差异。
定义:交叉熵损失函数(Cross-entropy loss function)是一种用于衡量模型输出与实际标签之间差异的损失函数。在机器学习中,交叉熵损失函数通常用于分类问题中,特别是在逻辑回归和神经网络等模型中。
对于一个逻辑回归函数:
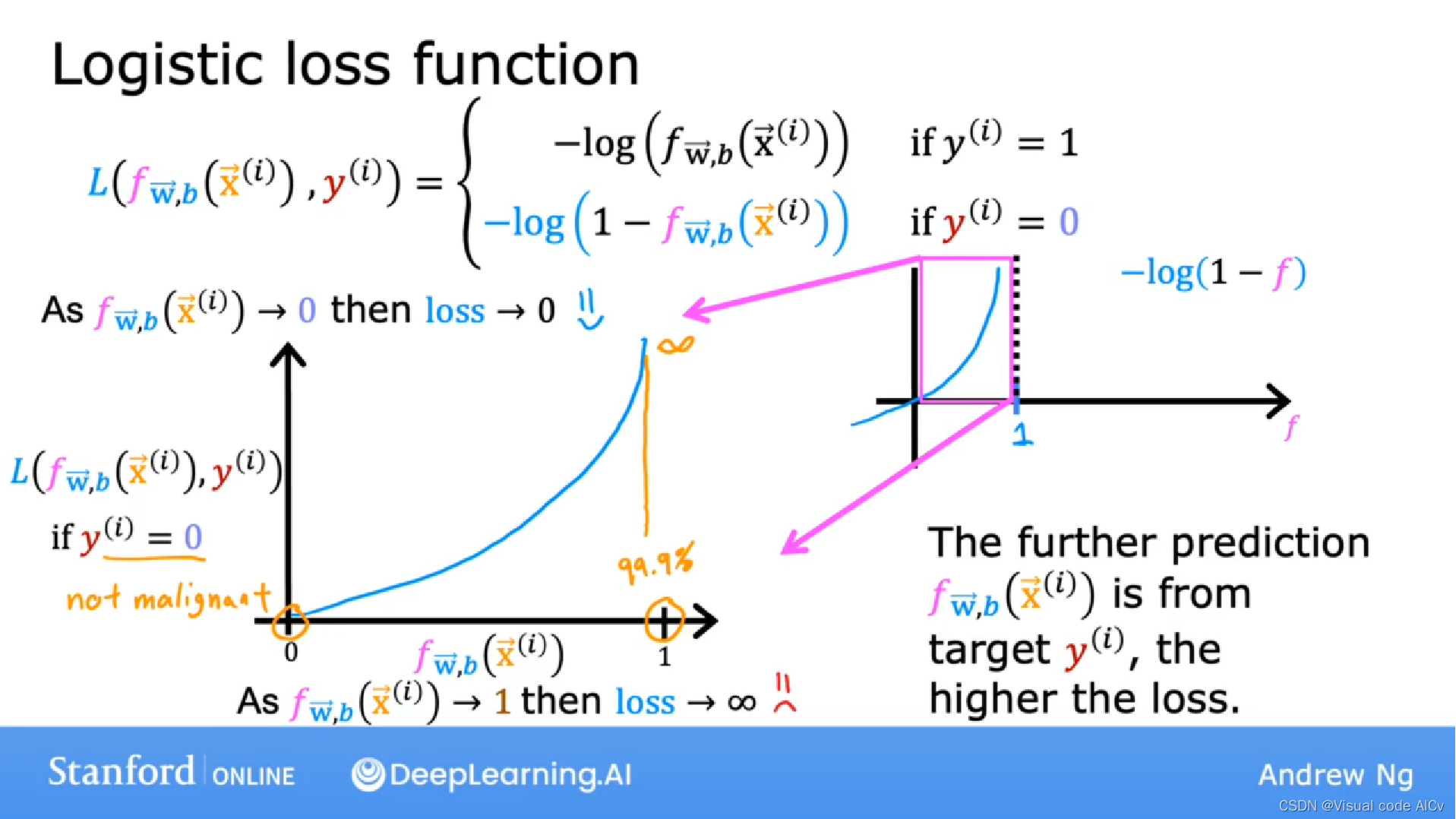
三、为什么不使用均方差损失函数

四、梯度下降实现
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




