文章目录
四种模型ocr效果简单测试
模型
PP-OCRv3、ppocr_server_v2、CnOCR、TesseractOCR
场景
发票(扫描件)、表格扫描件
1.paddle框架下PP-OCRv3
使用轻量级模型PP-OCRv3

1.1.效果如下:
1号表格扫描件==(时间2.13s)==:


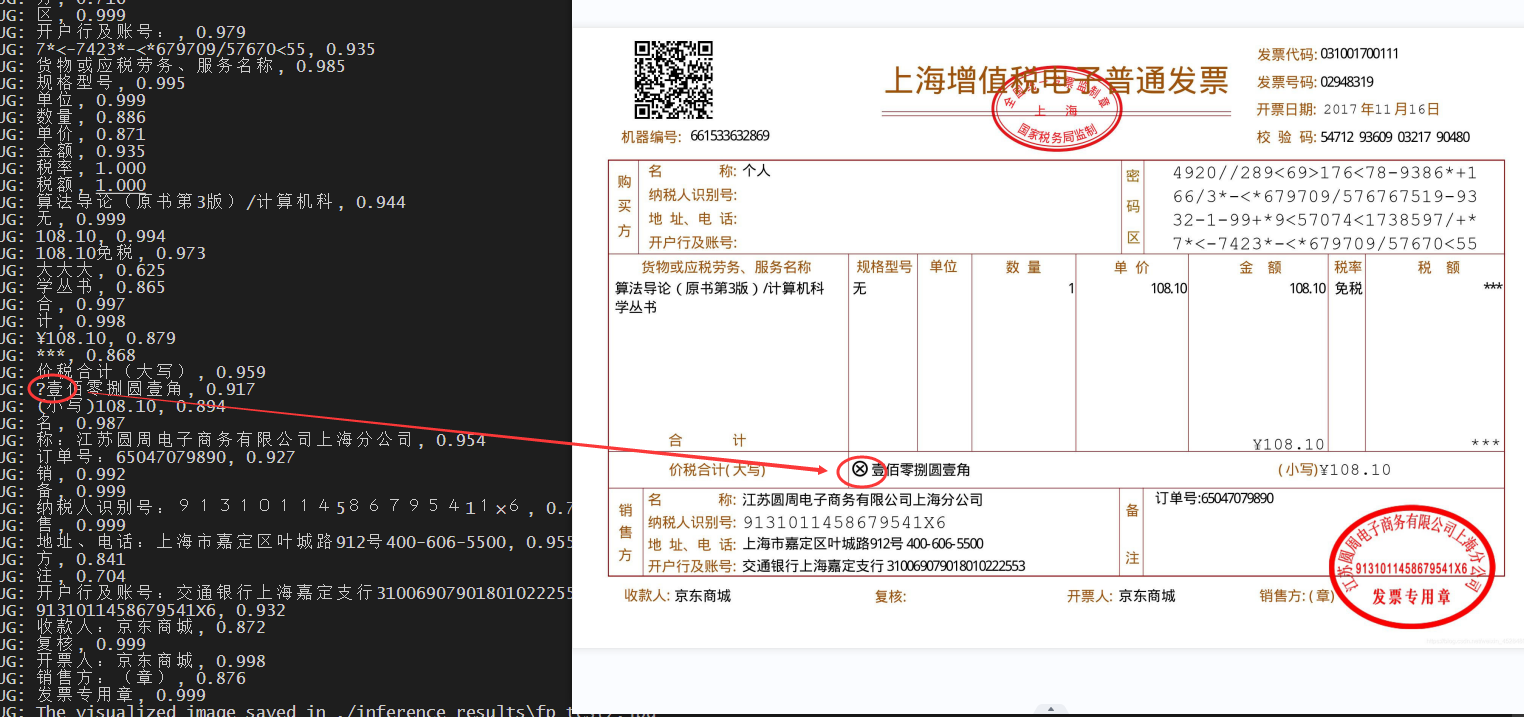
1号发票==(时间1.7s)==
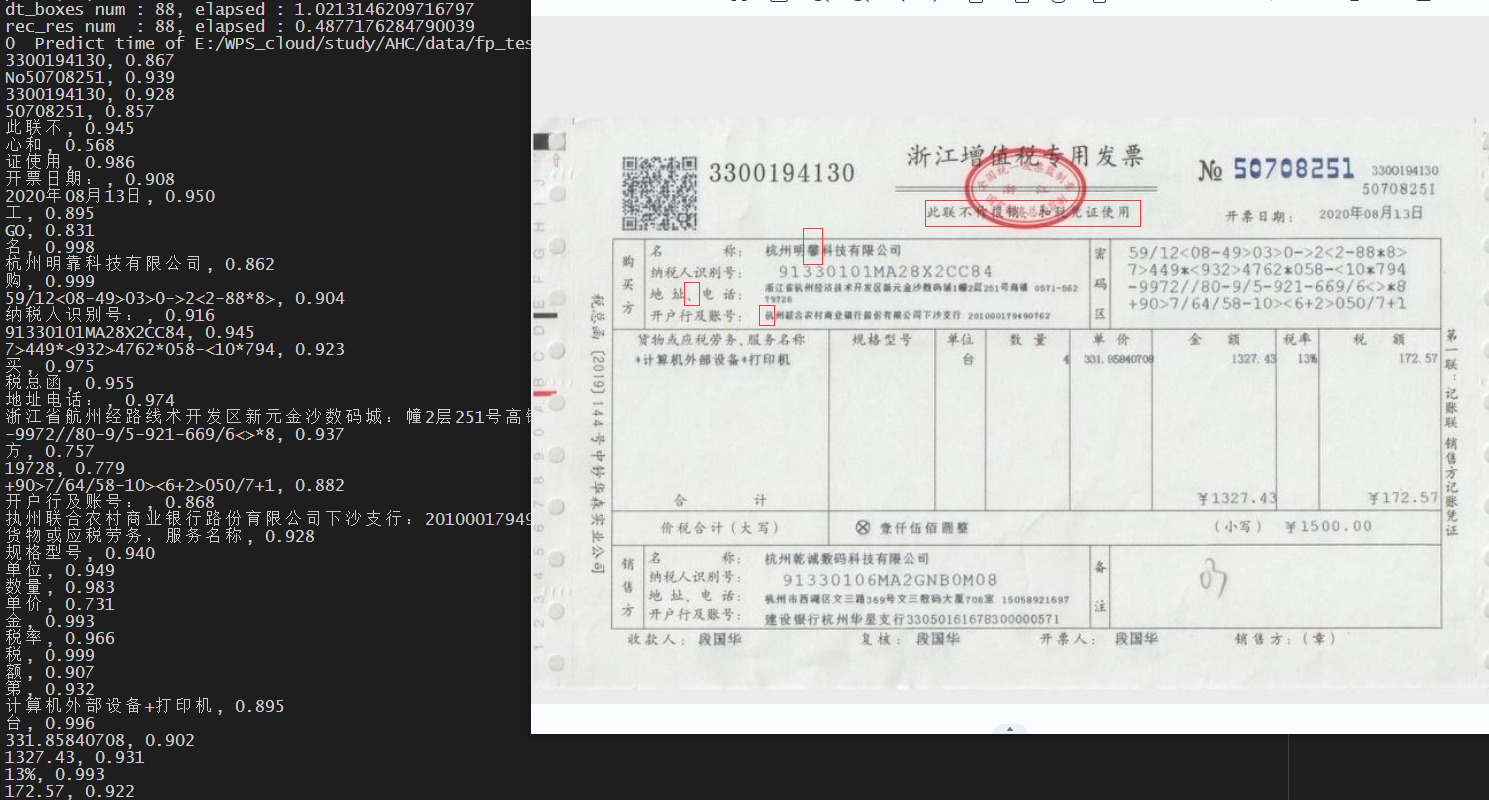
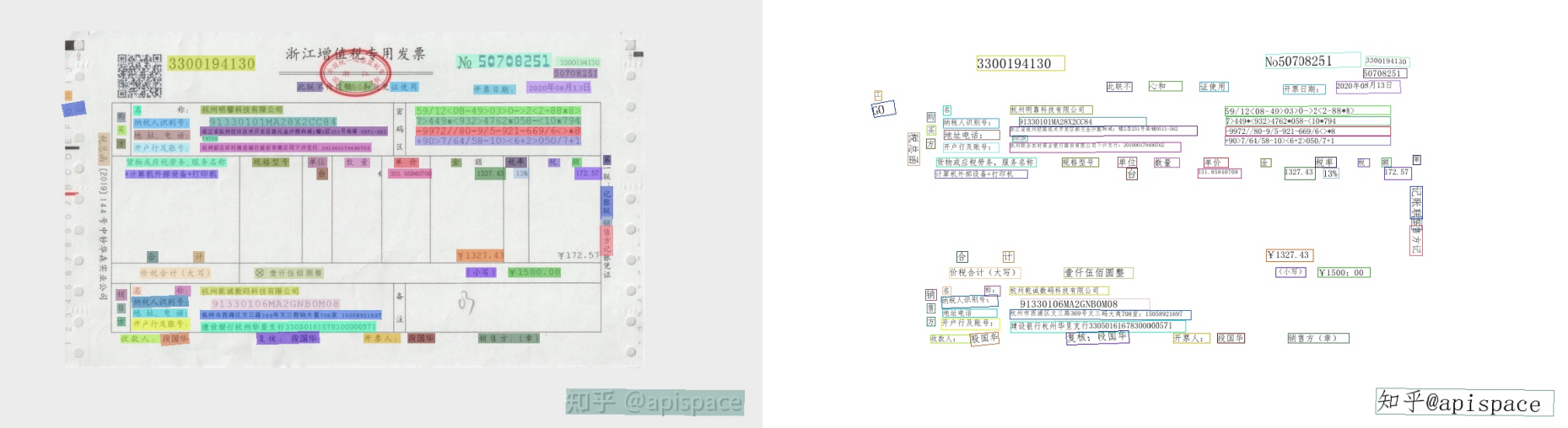
2号发票扫描件==(时间2.36s)==
1.2.总结
表格扫描件:效果一切良好
发票实拍:有部分模糊文字识别不清,图片太糊了
发票扫描件:效果良好,但是特殊字符无法识别,后续补充训练可以解决
2.paddle框架下ppocr_server_v2
使用通用模型PP-OCRv3

2.1.效果如下
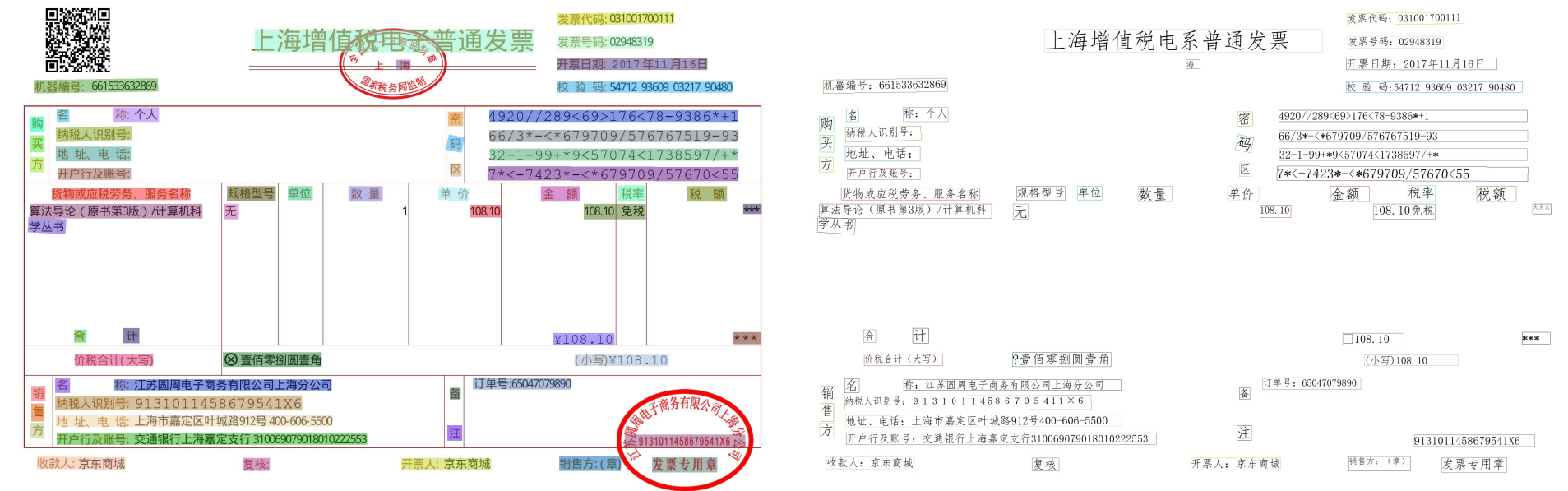
1号发票
2.2.总结
效果太差不试了
3.CnOCR
这里ocr参数全部设置默认
3.1.效果如下
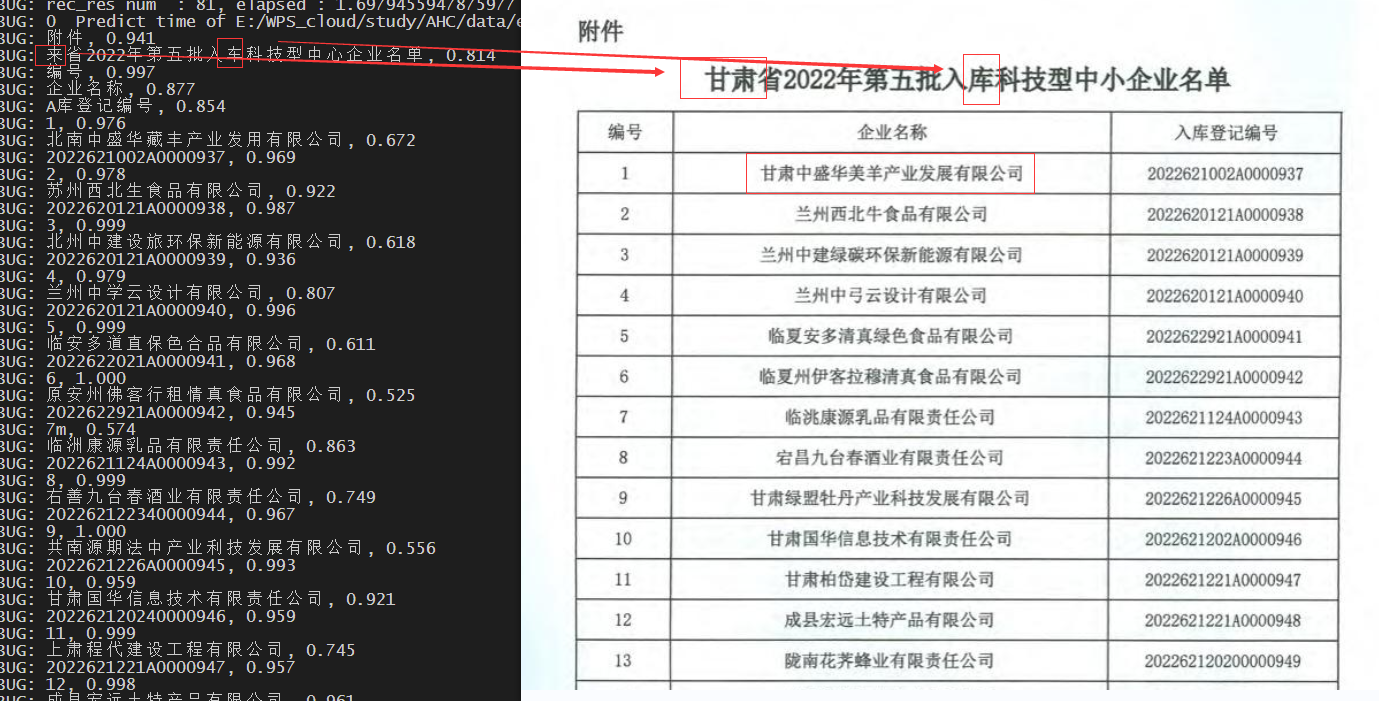
1号表格扫描件:
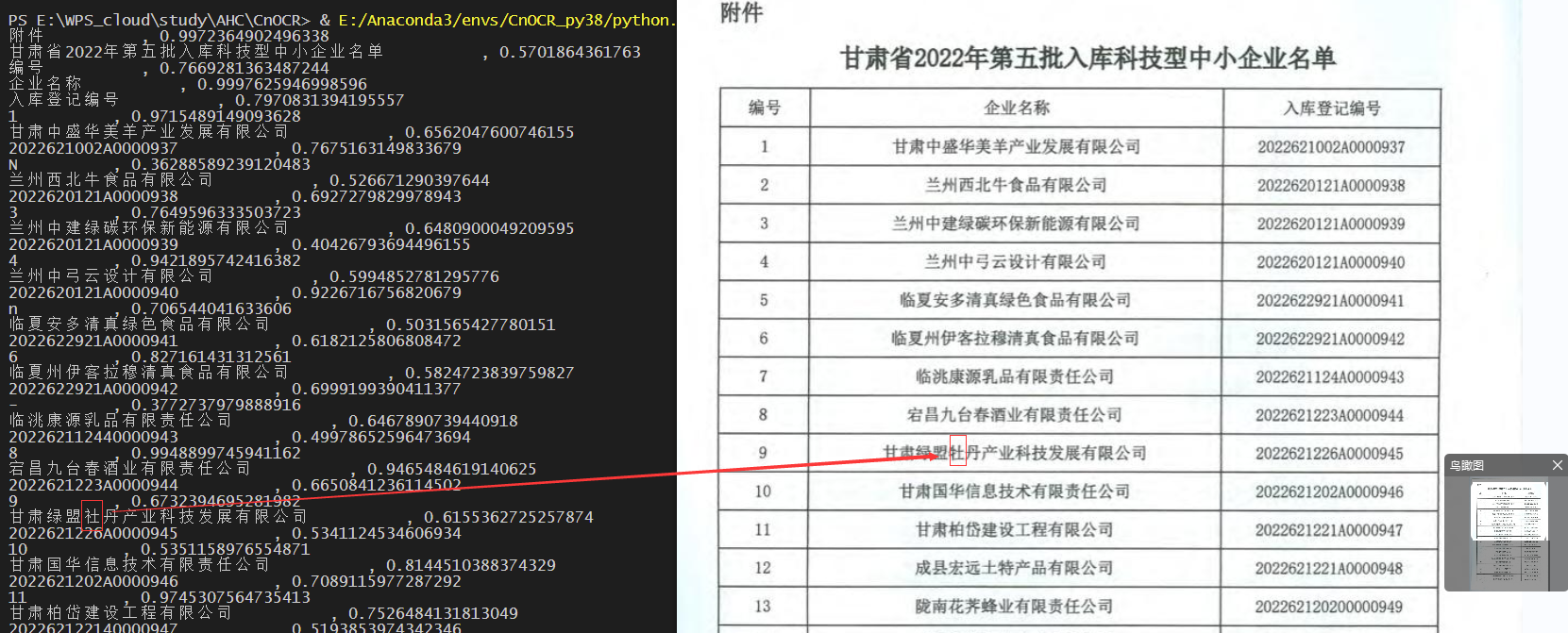
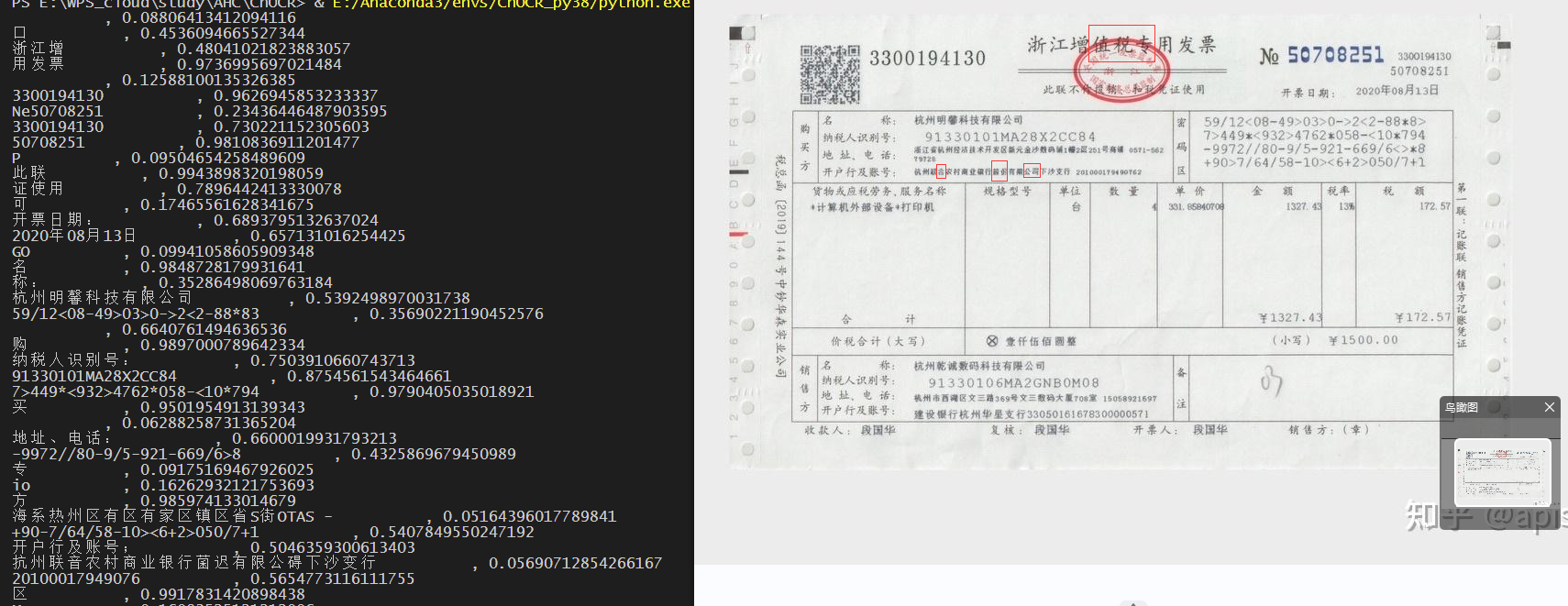
1号发票:
3.2.总结
比起paddle中文模型,有较大差距,
表格问题较小,但比如”牡“丹识别成了”社“丹
发票比较模糊,问题很多,比如联合识别成联音,公司识别成公碍等错误
特殊字符也同paddle一样无法识别, 识别成了8,不过可以补充训练
识别成了8,不过可以补充训练
4.TesseractOCR
4.1.效果如下
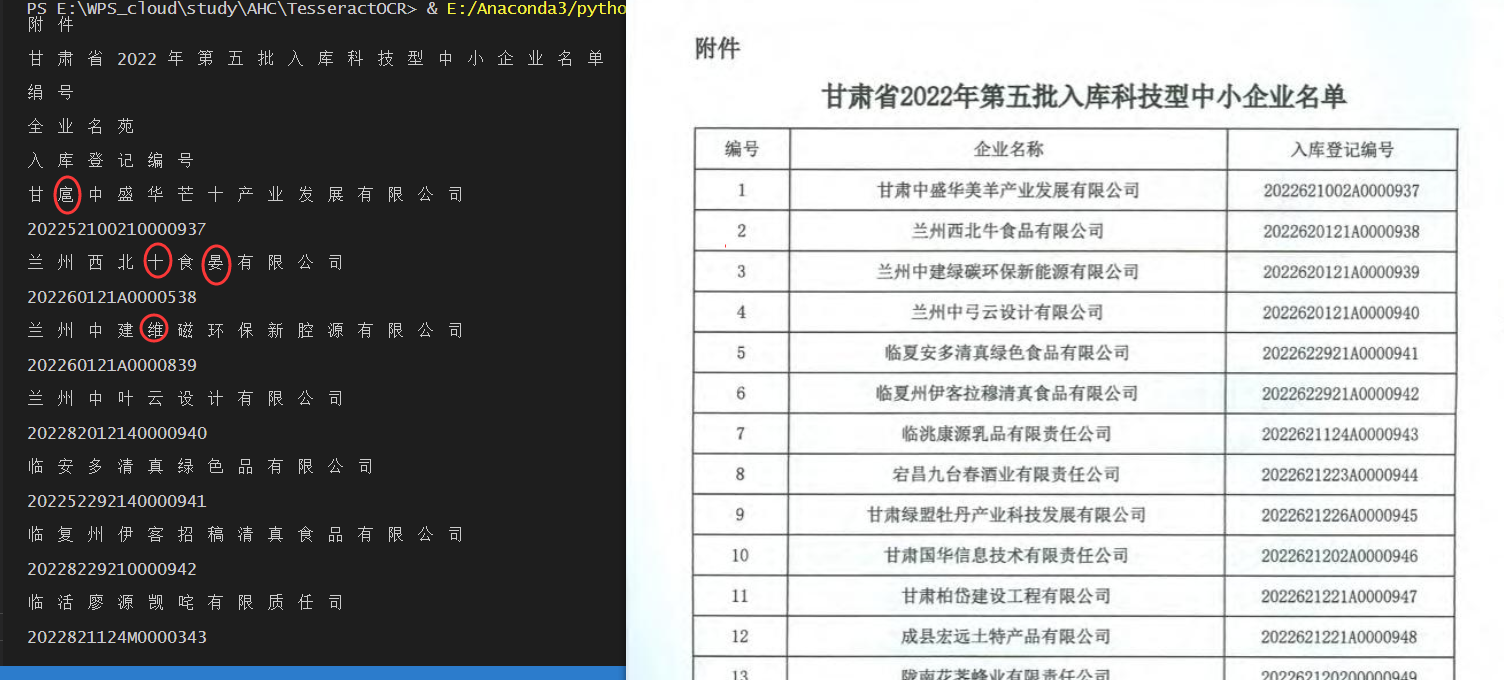
1号表格:
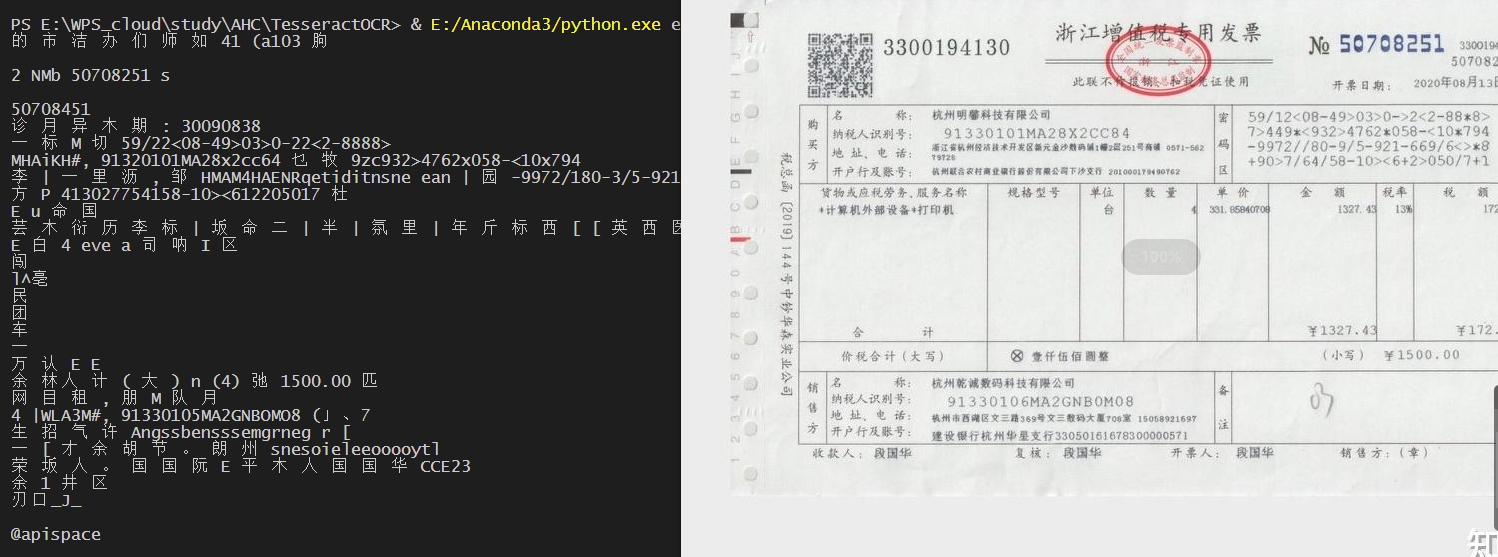
1号发票:
4.2.总结
中文识别一团浆糊,完全不能用
5.后续想法
基于paddle2.6发布的版本,PP-OCRv3表现最好,也是百度最新的OCR中文检测识别模型(paddle2.7下的v4没测),百度通用模型的效果相比而言差了很多。CnOCR比paddle差距明显,特别是模糊图片,Tesseract在中文场景下则是完全不能用。
此外,由于发票文档分布非常复杂,导致大部分识别模型无法对齐,但由于发票的模板非常固定,可以通过坐标变换先调整发票摆正,再裁剪图片喂给模型识别,以此来控制各个识别区域,避免文字错位。
原文地址:https://blog.csdn.net/code_bro/article/details/135847345
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_62199.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!