本文介绍: DATAX呢就是把各个不同构的数据库进行同步的过程,具体有hdfs hive Oracle 等等吧。
一.概念
DATAX呢就是把各个不同构的数据库进行同步的过程,具体有hdfs hive Oracle 等等吧。
二.架构
1.设计原理
显而易见从强连通图到星形图,大大的简化了工作量。
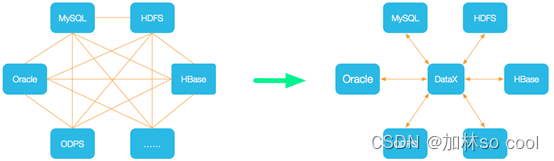
2.框架设计,变成了FrameWork和plugin的形式,以读者写者的方式(reader writer)进行数据的同步吧。

DataX在设计之初就将同步理念抽象成框架+插件的形式.框架负责内部的序列化传输,缓冲,并发,转换等而核心技术问题,数据的采集(Reader)和落地(Writer)完全交给插件执行。
4.运行原理
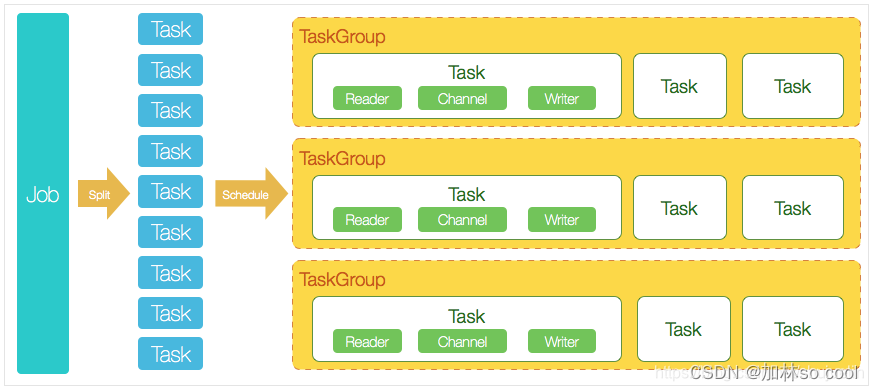
DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。