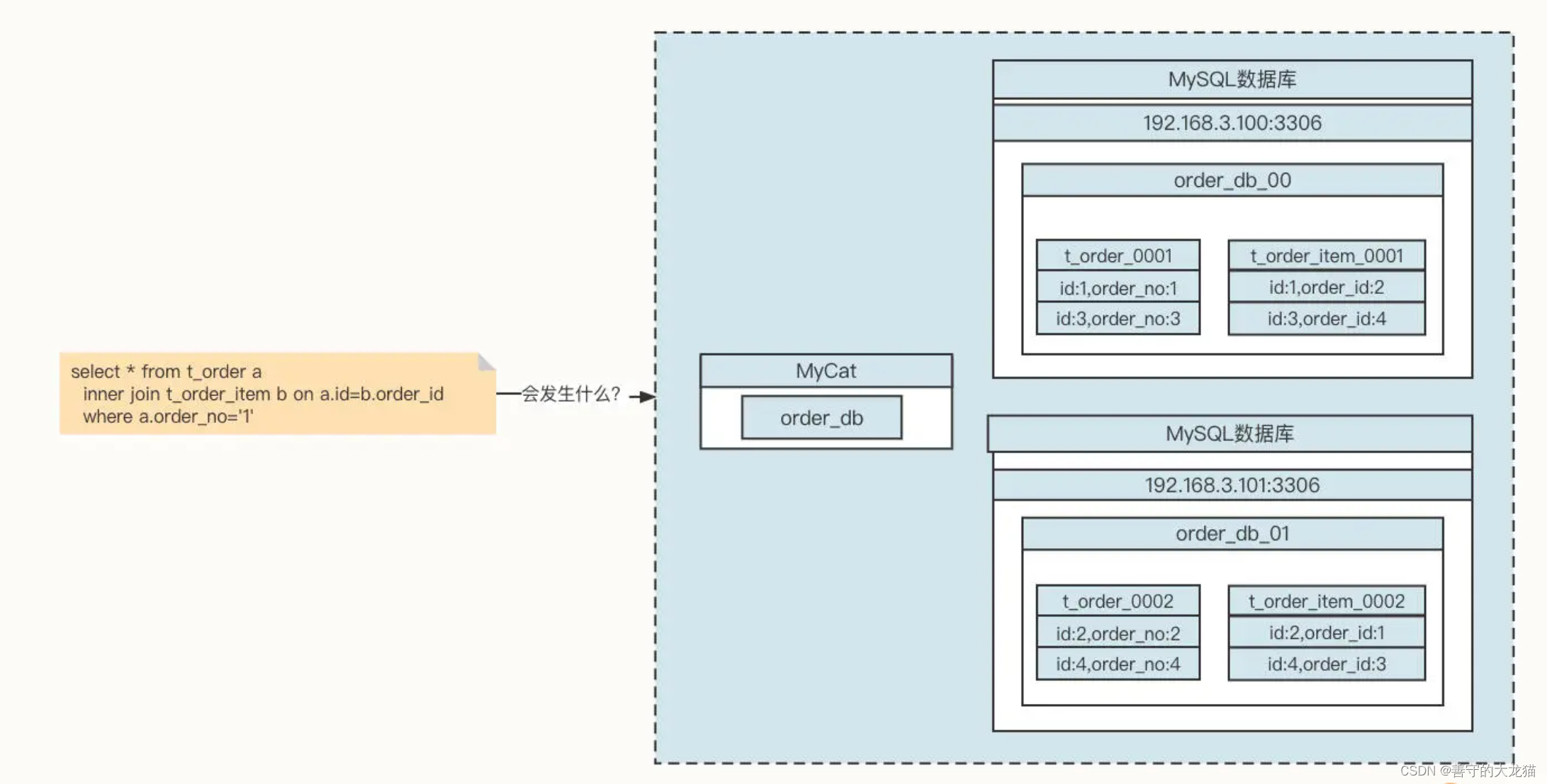
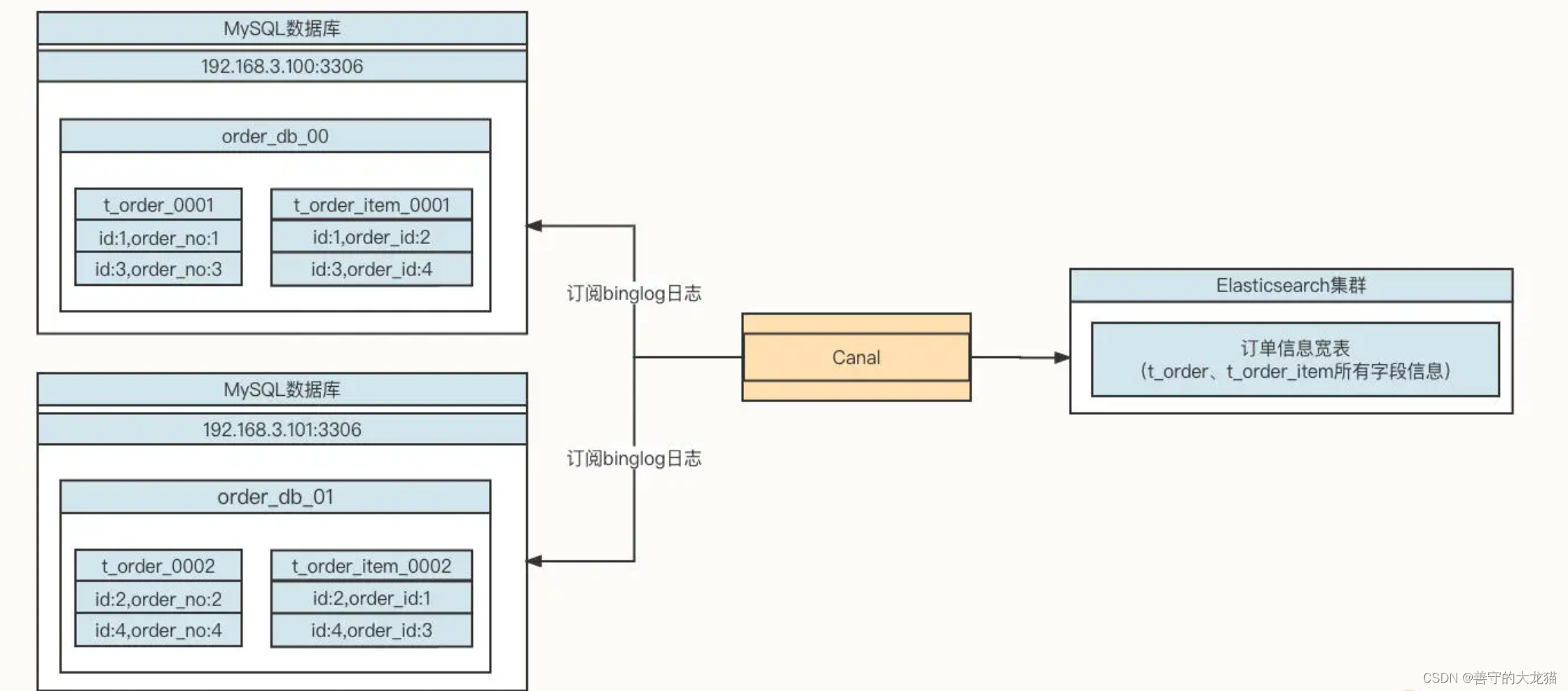
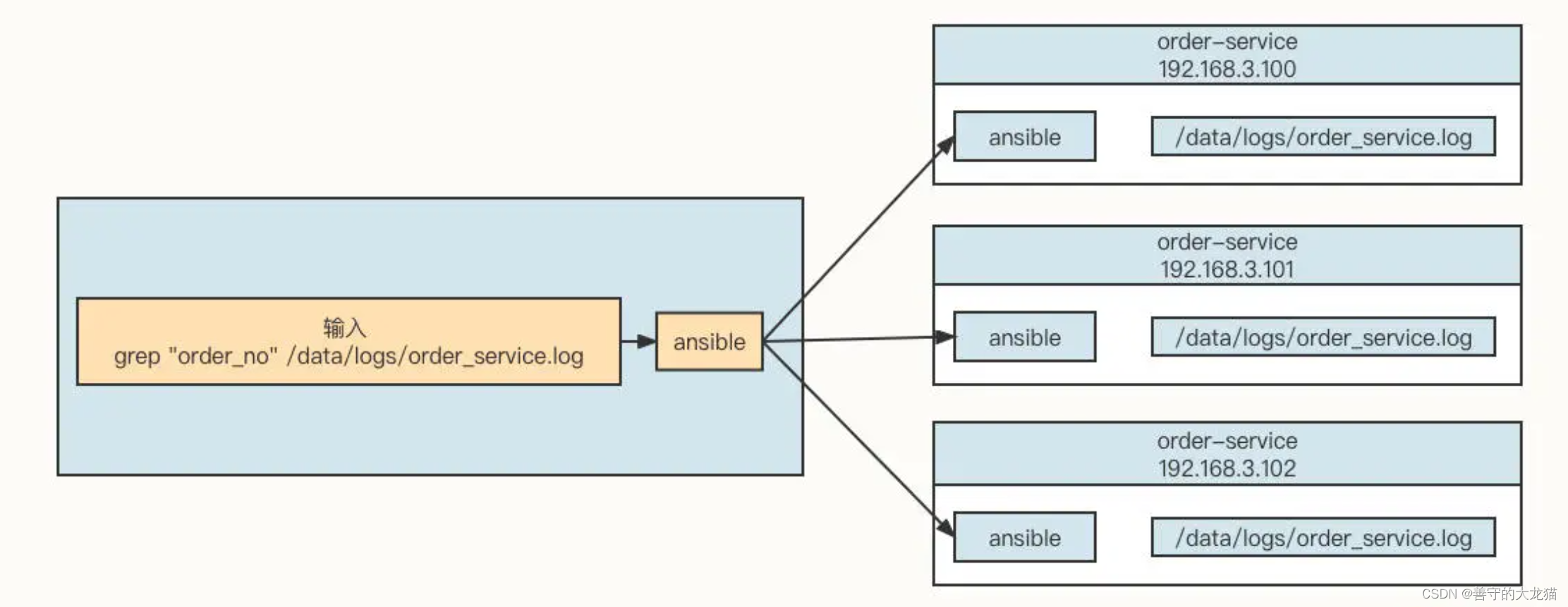
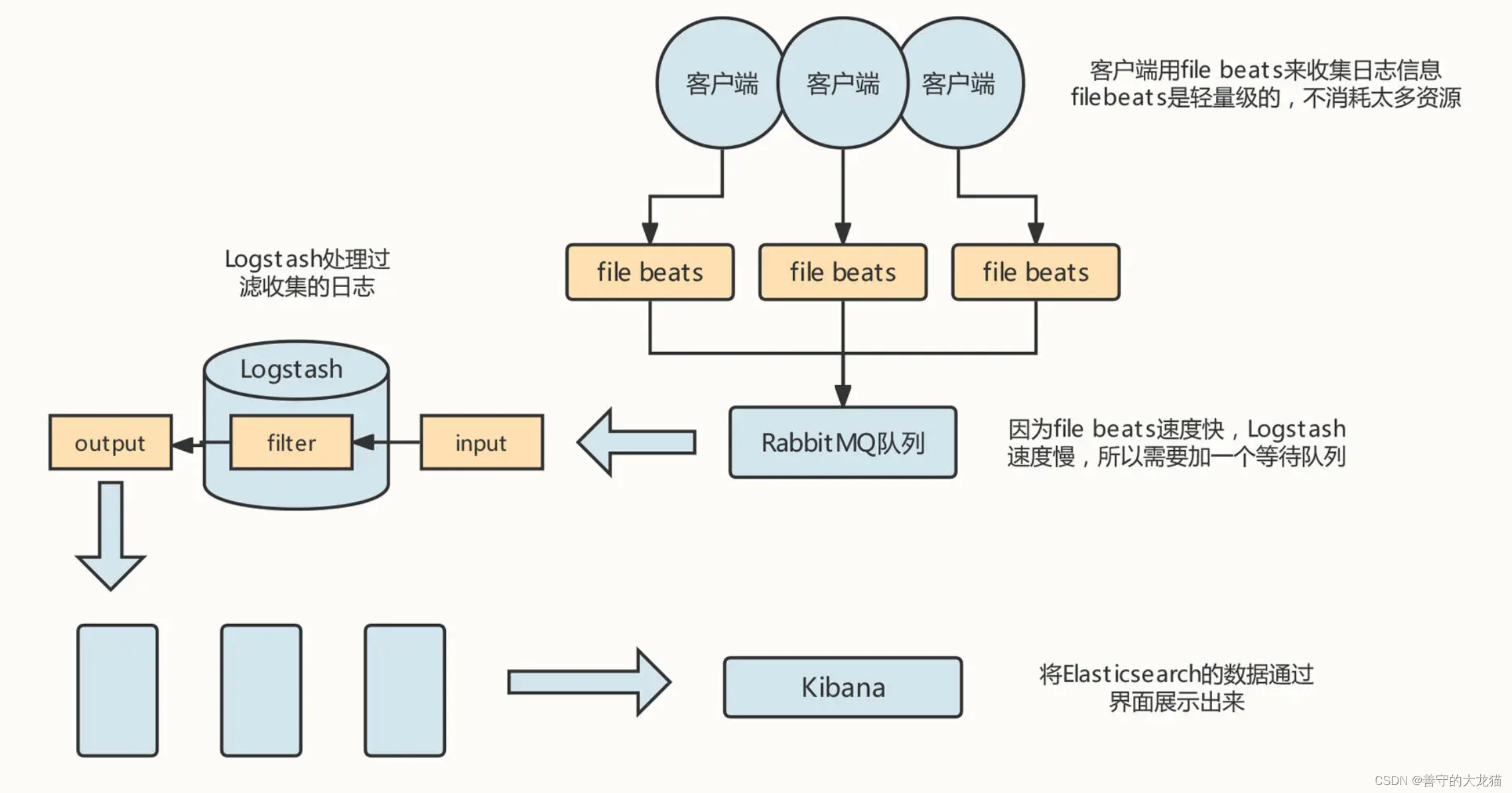
本文介绍: 然后,在需要采集的机器中安装 Logstash 进程,通过 Logstash 将日志数据存储到 Elasticsearch 服务器,用户可以通过 Kibana 查询存储在 Elasticsearch 中的日志数据,这样,我们就可以有针对性地查询所需要的日志了。由于订单编号为 1 的订单信息存储在 order_db_00 中,但与这条订单关联的订单字表却存储在 order_db_01 中,而 Join 操作需要的笛卡尔积操作存在于不同的数据库实例中,所以我们就要将多个数据库中的数据统一加载到内存中。
缓存中间件
缓存是性能优化的一大利器
我们先一起来看一个用户中心查询用户信息的基本流程
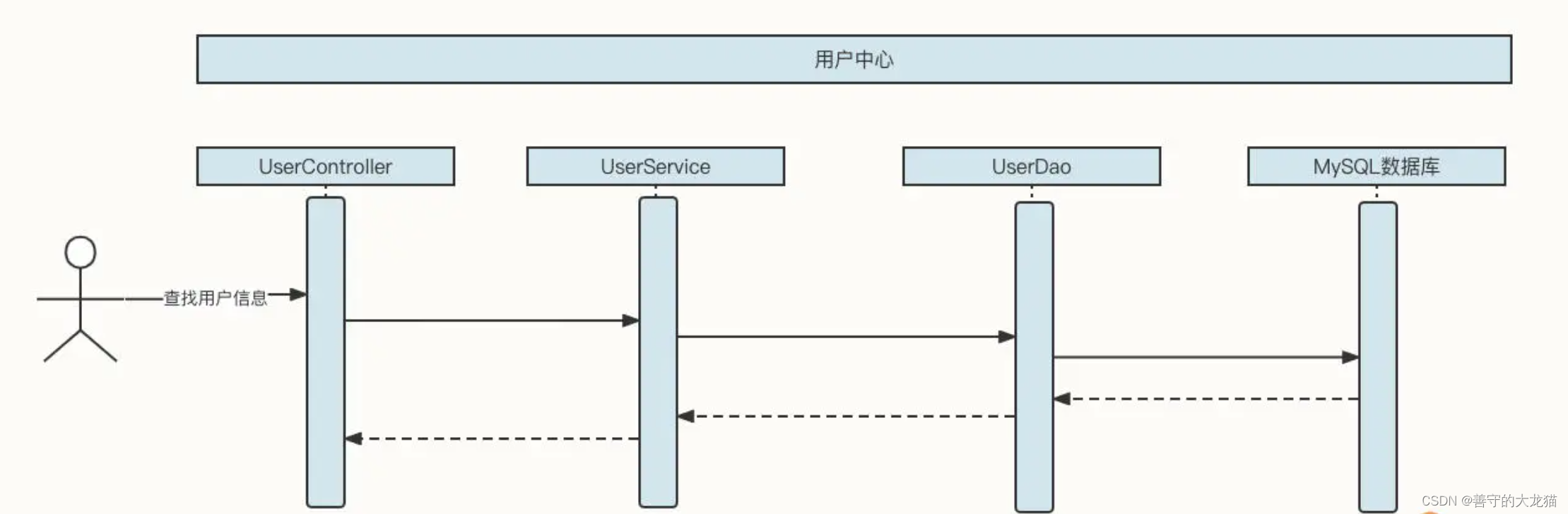
这时候,如果查找用户信息这个 API 的调用频率增加,并且在整个业务流程中,同一个用户的信息会多次被调用,那么我们可以引入缓存机制来提升性能:
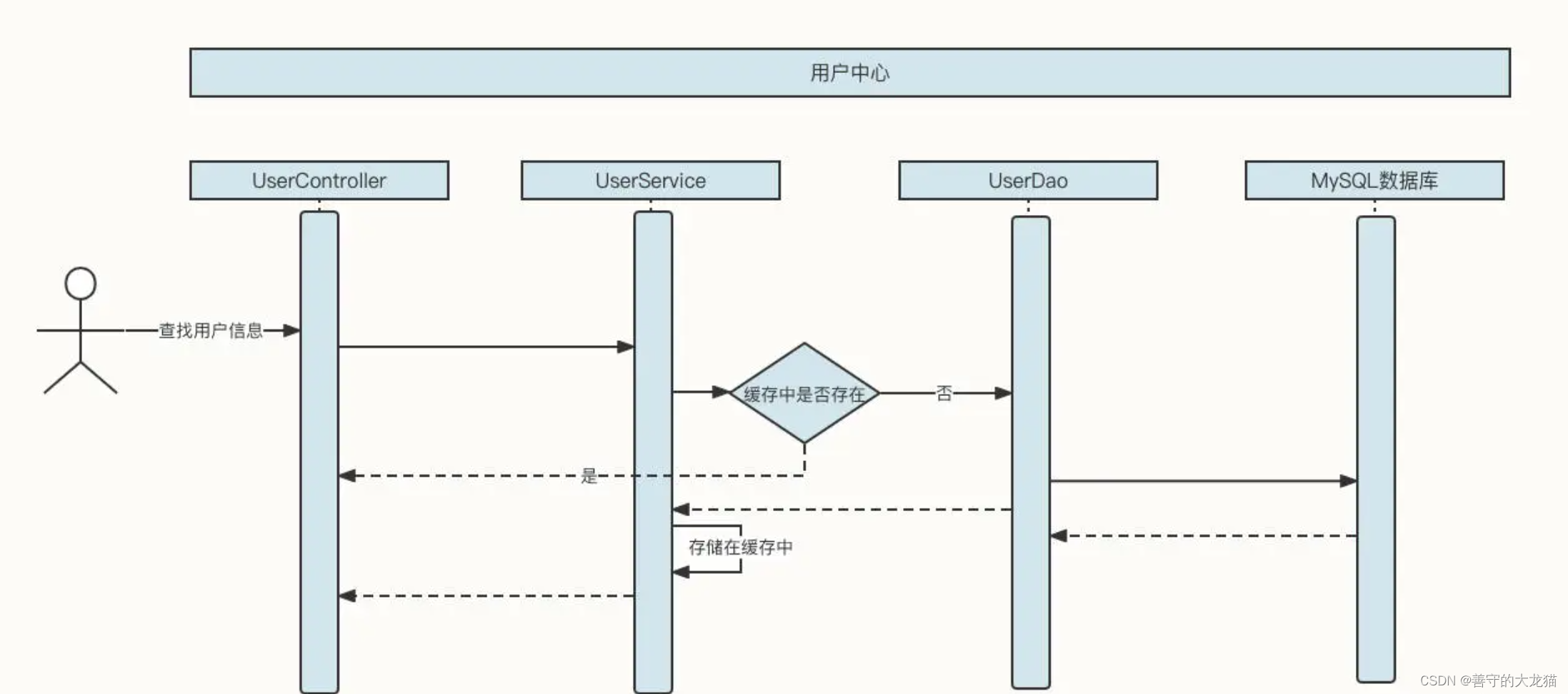
也就是说,在 UserService 中引入一个 LinkedHashMap 结构的内存容器,用它存储已经查询到的数据。如果新的查询请求能命中缓存,那么我们就不需要再查询数据库了,这就降低了数据库的压力,将网络 IO、磁盘 IO 转变为了直接访问内存,性能自然而然也提升了。
但上面这个方案实在算不上一个优秀的方案,因为它考虑得非常不全面,存在下面这几个明显的缺陷:内存容量有限、容易引发内存溢出,缓存在节点之间不一致,数据量非常庞大。
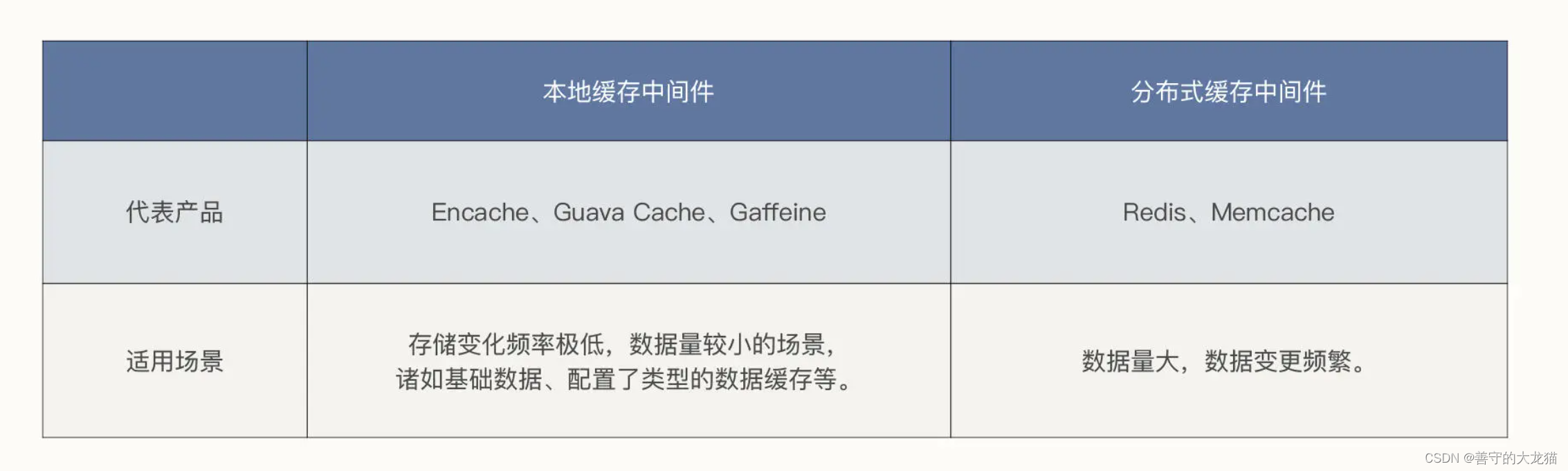
本地缓存中间件
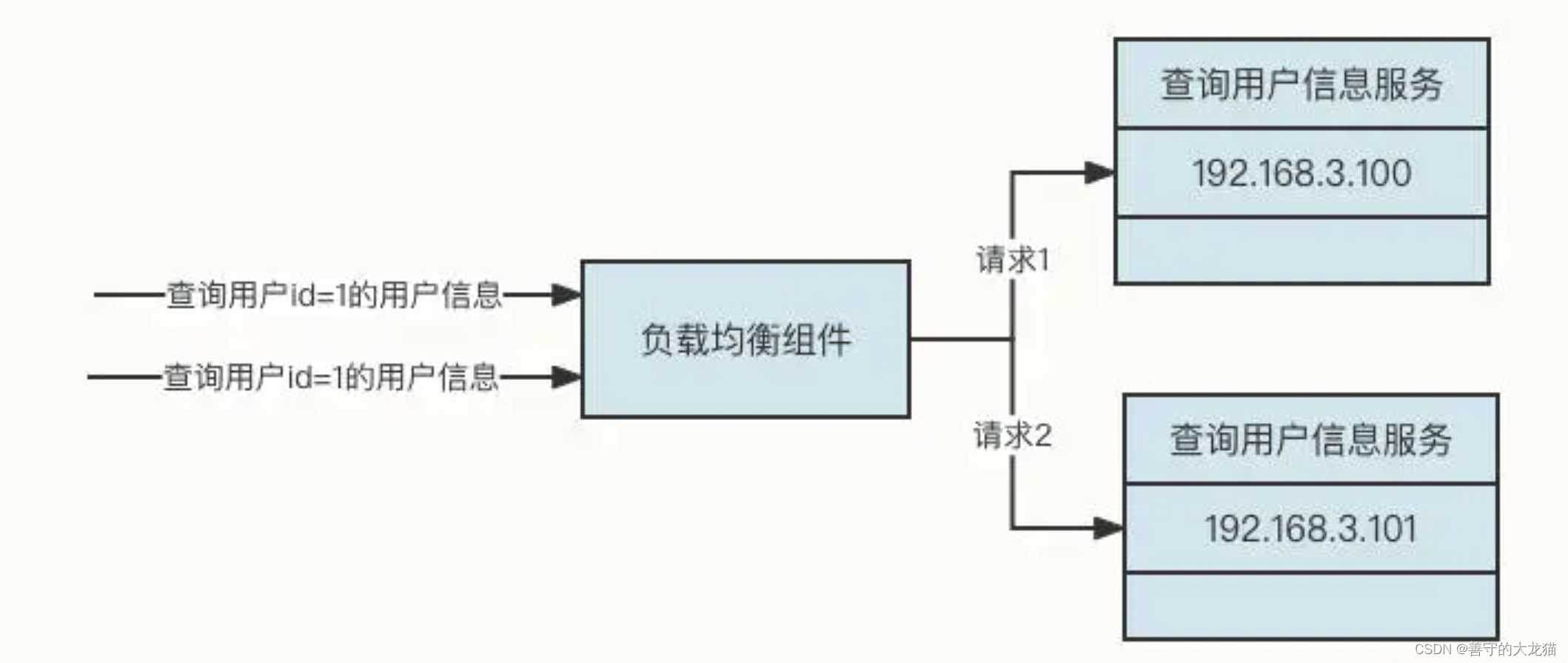
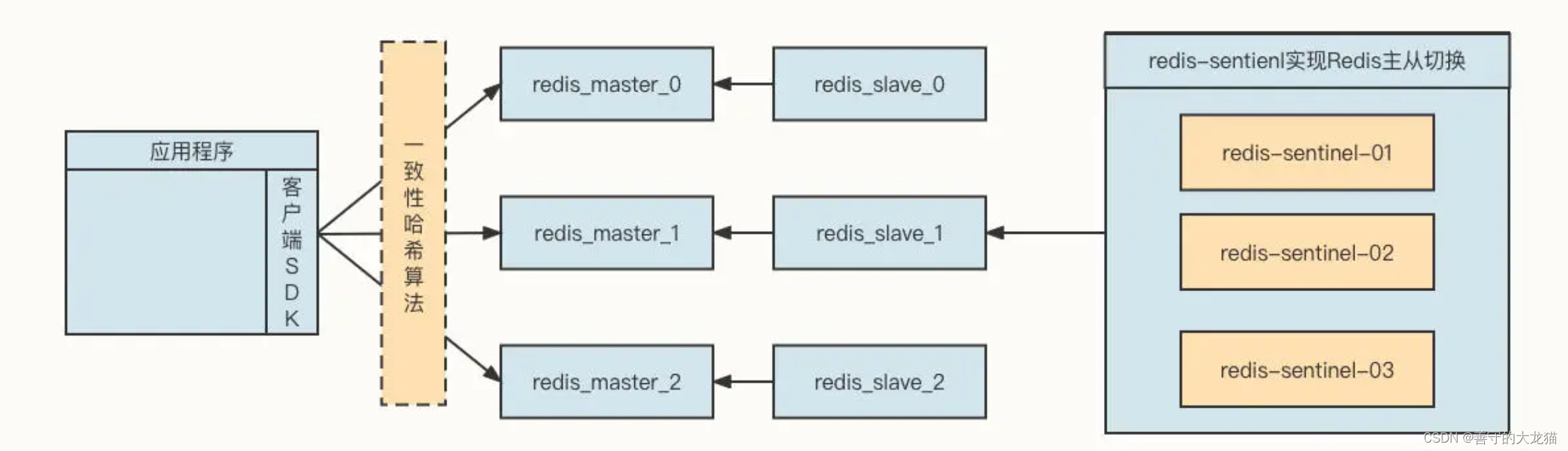
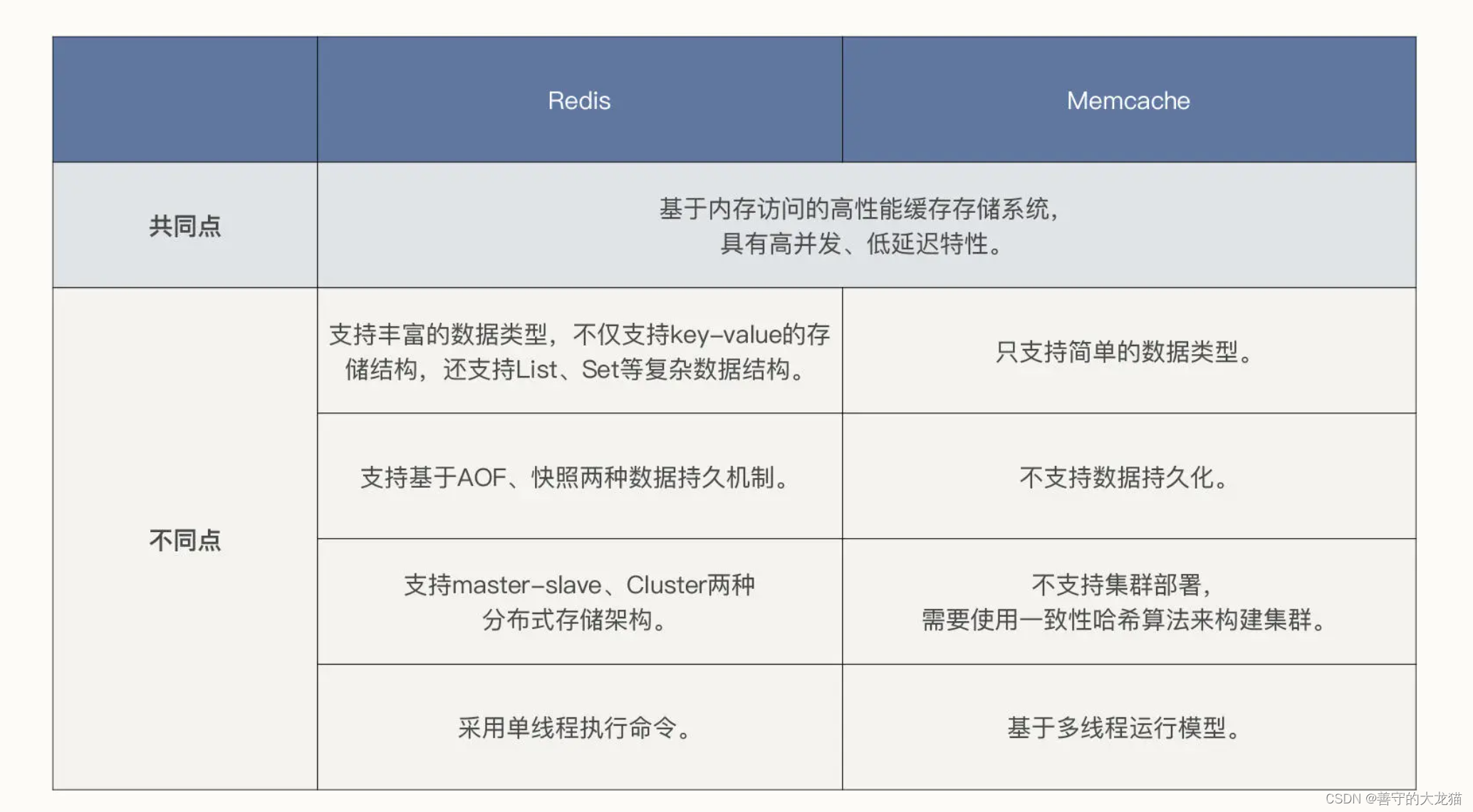
分布式缓存中间件
全文索引中间件
分布式日志中间件
小结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。