本文介绍: 【代码】数据分析 – python 数据处理。
数据处理
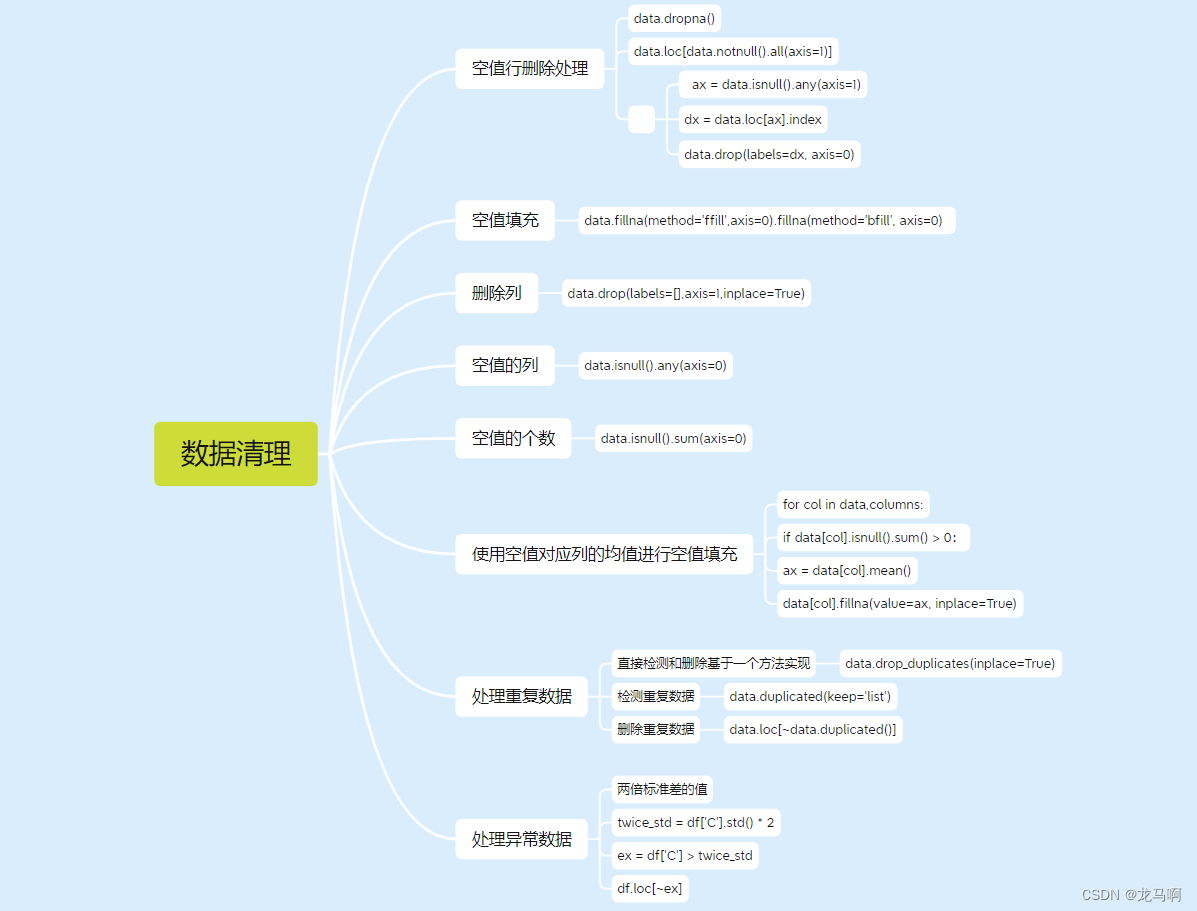
- 去除重复数据
# 删除重复值 保留重复行 第一行的数据
data.drop_duplicates(inplace=True, keep='first')
- 数据格式转化
日期格式化
data['order_date'] = pd.to_datetime(data['order_dt'], format='%Y%m%d')
data['销售时间'] = pd.to_datetime(data['销售时间']) # 交货时间 销售时间
data['月份'] = data['销售时间'].map(lambda x: x.month)
# dir = {'1': '一季度', '2': '一季度', '3': '一季度', '4': '二季度', '5': '二季度', '6': '二季度', '7': '三季度', '8': '三季度', '9': '三季度', '10': '四季度', '11': '四季度', '12': '四季度'}
# data['季度'] = data['月份'].map(lambda x: str(x)).map(lambda x: dir[x])
# data.groupby(by='季度')['货品'].count().plot.bar()
# 将 order_date 转成 精度是 月份的数据列
data_text['order_date_month'] = data_text['order_date'].values.astype('datetime64[M]')
去除前后空格
# 去除前后空格
data['货品交货状况'] = data['货品交货状况'].str.strip()
- 删除空值行
# 第一部分
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
plt.rcParams['font.sans-serif'] = 'SimHei' ## 设置中文显示
%matplotlib inline
route = 'meal_order_detail.xlsx'
data1 = pd.read_excel(route, sheet_name='meal_order_detail1')
data2 = pd.read_excel(route, sheet_name='meal_order_detail2')
data3= pd.read_excel(route, sheet_name='meal_order_detail3')
data = pd.concat([data1, data2,data3],axis=0)
data.head(5)
# 第二部分 清除 Na 的值 删除空值行
data.dropna(axis=1, inplace=True)
- 删除指定列,或者空值列
# 删除订单这一列数据
data.drop(columns=['订单行'], inplace=True, axis=1)
# 删除空值列 axis=0
data.dropna(axis=0, inplace=True, how='any | all')
- 异常数据处理
取出 索引值 1 2 3 , 列名 'A' 'B'
data.loc[[1,2,3] , ['A','B']]
异常值处理原则 数值分布在(μ-3σ,μ+3σ)中的概率为0.9973
最小值
平均数 - 3*标准差
最大值
平均数 + 3*标准差
# 第一部分
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
plt.rcParams['font.sans-serif'] = 'SimHei' ## 设置中文显示
%matplotlib inline
route = 'meal_order_detail.xlsx'
data1 = pd.read_excel(route, sheet_name='meal_order_detail1')
data2 = pd.read_excel(route, sheet_name='meal_order_detail2')
data3= pd.read_excel(route, sheet_name='meal_order_detail3')
data = pd.concat([data1, data2,data3],axis=0)
def three_sigma(ser):
"""
自实现3sigma 原则
:param ser: 数据
:return: 处理完成的数据
"""
bool_id = ((ser.mean() - 3 * ser.std()) <= ser) & (ser <= (ser.mean() + 3 * ser.std()))
# bool_id 数组索引
# ser[bool_id]
return ser.index[bool_id]
# 调用3sigma原则,进行异常值过滤
index_name_list = three_sigma(data['amounts'])
deatil = data.loc[index_name_list,:]
- 空值填充
# 相邻前面的值或者后面的值填充
data.fillna(method='ffill',axis=0).fillna(method='bfill', axis=0)
# 使用空值对应列的均值进行空值填充
for col in data,columns:
if data[col].isnull().sum() > 0:
ax = data[col].mean()
data[col].fillna(value=ax, inplace=True)
原文地址:https://blog.csdn.net/qq_43853213/article/details/135848653
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_62341.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





