本文介绍: 在上面的介绍中,我们解释了Elasticsearch是如何通过增加系统字段来扩充Lucene的功能,开篇提出的Lucene的多个不足中,前四个都在文章中做了说明,最后一个没法通过增加系统字段实现,我们将会在下一篇《Elasticsearch写流程简介》中介绍如何通过其他方式来实现,下一篇见。另外,我们招人:Elasticsearch和Lucene的开发,有兴趣的可以私信联系我。
Elasticsearch内核解析 – 数据模型篇 – 知乎
Elasticsearch是一个实时的分布式搜索和分析引擎,它可以帮助我们用很快的速度去处理大规模数据,可以用于全文检索、结构化检索、推荐、分析以及统计聚合等多种场景。
Elasticsearch是一个建立在全文搜索引擎库Apache Lucene 基础上的分布式搜索引擎,Lucene最早的版本是2000年发布的,距今已经18年,是当今最先进,最高效的全功能开源搜索引擎框架,众多搜索领域的系统都基于Lucene开发,比如Nutch,Solr和Elasticsearch等。Elasticsearch第一个版本发布于2010年,发布后就以非常快的速度霸占了开源搜索系统领域,成为目前搜索领域的首选,著名的维基百科,GitHub和Stack Overflow都在使用它。
既然有Lucene娥,为啥还会出现很火的Elasticsearch?回答这个问题之前, 我们先来简单看一下Lucene中的一些数据模型:
Lucene数据模型
Lucene中包含了四种基本数据类型,分别是:
上述四种类型在Elasticsearch中同样存在,意思也一样。
Lucene的不足
Elasticsearch怎么做
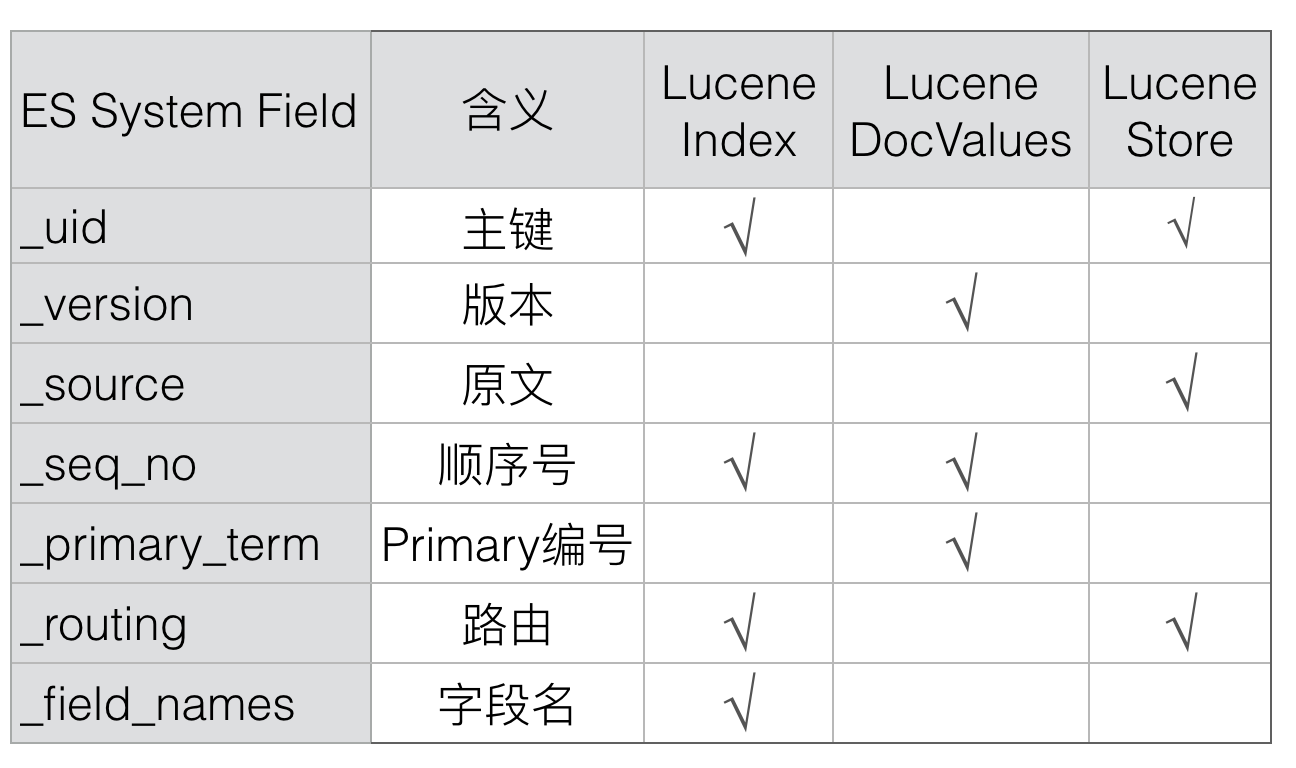
1. _id
2. _uid

3. _version

4. _source

5. _seq_no

6. _primary_term

7. _routing

8. _field_names

总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[Lucene]核心类和概念介绍](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)