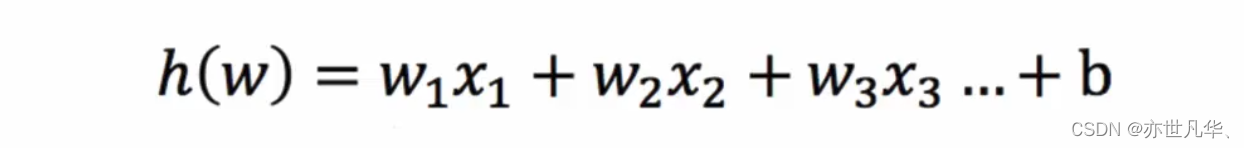本文介绍: 数学建模常见算法的通俗理解(3)
11 Logistic模型(计算是/否的概率)
11.1 粗浅理解
我们有m张图片,并且获取了这些图片的特征向量的矩阵,我们需要判断这些图片中是否满足我们某个要求,如是否含有猫🐱这种动物。那么此时我们的每张图片传进模型后的输出就是一个概率。因为概率的大小都是趋于0到1之间的,此时我们就不能利用简单的线性回归来作为输出。我们可以考虑使用logistic回归。logistic回归函数的参数也是一个大小为n的向量,它可以看成是对应每个像素的权重,并且还含有一个b的标量表示偏移。而要实现逻辑回归就需要控制y的输出位于0到1之间,这里利用的方法是使用sigmoid函数,它可以将输出y控制到0-1之间,sigmoid函数如下:

它的函数表达式是: ![]()
我们可以看到这个函数将输出控制在0-1之间。此时我们的logistic回归的表达式就是:
![]()
损失函数和代价函数:
上面我们讨论了logistic回归,我们的目的是要使用这个回归来得到预测输出y,但是我们知道,我们需要一个标准来衡量我们的输出是否好,即训练值中的输出和预测是否一致。而这个衡量标准就是损失函数。对于单个样本,我们定义一个函数loss来计算真实值和预测值的误差:loss=ylog(y^)+(1−y)log(1−y^)


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。