本文介绍: 说明:http://IP:8080/做健康检测,但有问题的是,我们的服务不一定都是/结尾,有时需要加后缀才能访问到资源。check_http_send字段 HEAD后面的 / 就是路径的配置,与其对应的正确能被识别到的地址为”HEAD /ierp/checkk8shealth HTTP/1.0rnrn”,/后面可以为项目中的某个url只要能请求到就可以。用法: check_http_expect_alive [ http_2xx | http_3xx | http_4xx | http_5xx ]
被动检查
proxy_next_upstream

nginx被动健康检查的缺陷
(1)Nginx只有当有访问时后,才发起对后端节点探测。
(2)如果本次请求中,节点正好出现故障,Nginx依然将请求转交给故障的节点,然后再转交给健康的节点处理。所以不会影响到这次请求的正常进行。但是会影响效率,因为多了一次转发。
(3)自带模块无法做到预警。
主动检查
下载地址 https://github.com/yaoweibin/nginx_upstream_check_module
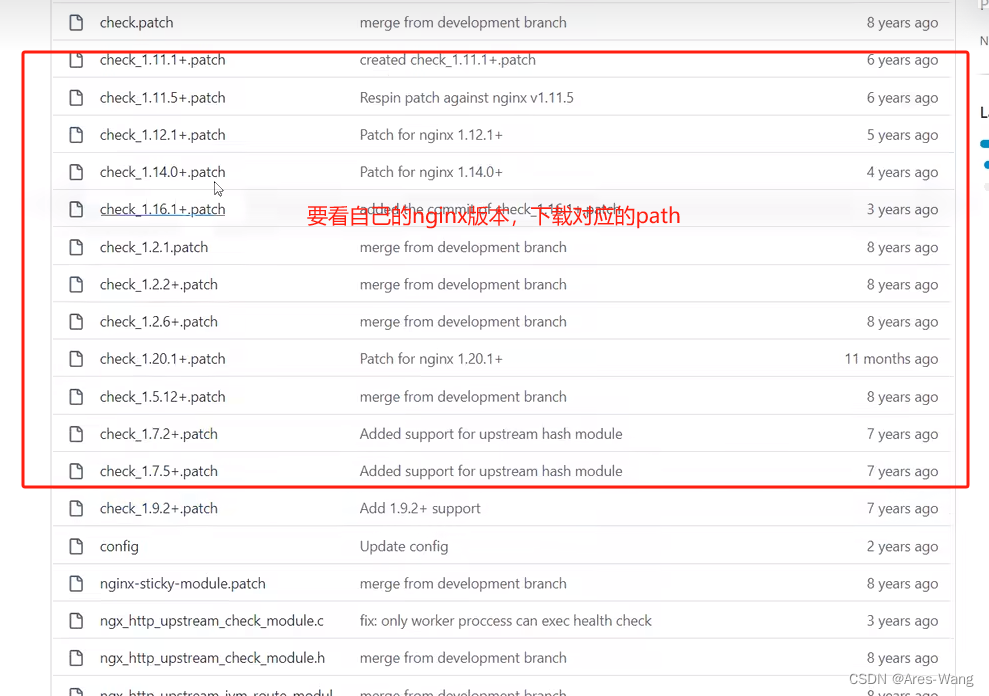
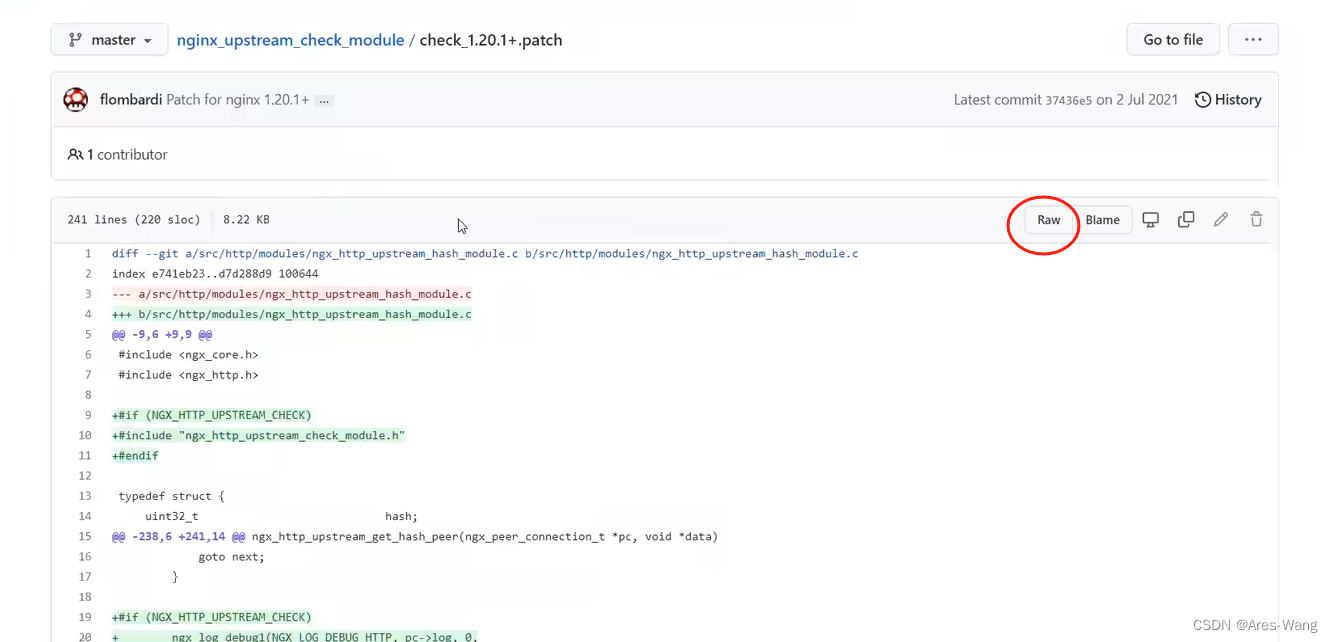
raw之后,复制里面的内容,
在nginx中 vim path


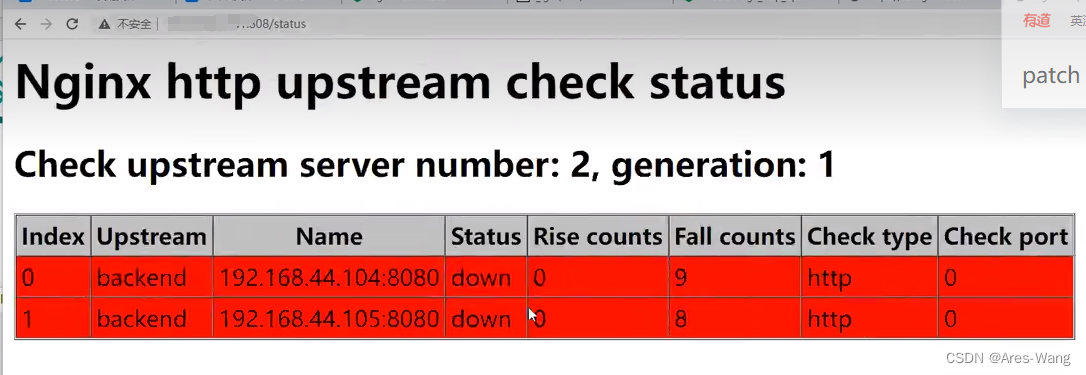
check功能
check_http_send 功能
check_http_expect_alive功能:
check_keepalive_requests功能:
check_fastcgi_param功能:

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。