elasticsearch高级应用
1.es的深度分页问题
1.浅分页from/size
浅分页适合用于小于10000数据集的业务场景属于通过业务解决es深度分页问题的方式(类似百度就是这样的),浅分页支持随机跳转分页的业务场景。
from:未指定是0 代表数据的起始值
size:未知的是10 代表返回数据条数
es定义大于10000条的分页(默认)因为性能过差是禁止查询的,所以称为浅分页。具体的数量可以通过参数max_result_window设置。
因为es集群是分片存储的同一个索引不同的数据存储在不同的分片上,所以浅分页查询的时候是类似shardingjdbc的直接查询每一个分片上所有的分页数数据并排序(query m+n)汇总到协调节点再做聚合排序(fetch)。比如from 1000 ,size 10,有3个es主分片。要查询每个分片节点的0到1010条数据,然后协调节点拿到全部分片的3030条数据再做全局排序取到前10个,这样查询的性能很差有资源浪费,深度翻页的时候数据量越大越慢。
2.深度分页scroll遍历查询
游标查询,非实时的查询,query时候在内存中建立一个快照,查询时候设置文档排序,多久删除比如scroll = 1m 1分钟后删除,会返回一个scroll_id,下次根据scroll_id查询的时候会遍历这个快照。使用后推荐直接把指定scroll_id删除掉。
适用于大量数据的遍历导出,不适合分页查询,scroll分页是非实时的,快照建立的那一刻数据就固定了之后的新增数据修改数据不会对快照数据有任何的影响。通常不建议用这种方式做分页,非实时的且浪费内存空间最多500个快照,一般深度分页还是推荐使用pit+search_after。
3.深度分页search_after
使用前一页中的一组排序值来检索匹配的下一页,search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求,无法指定页数,只能实现“下一页”这种需求。
比如想让下一次的查询不影响这一次的结果,也就是让多次查询结果一致。可以给索引创建一个轻量级的视图pit并指定存活时间使用后删除。
pit+search_after是比较推荐的深度分页处理方式,不过是不支持跳页查询的,如果跳页查询需要使用浅分页from/size具体使用根据业务来。
2.es的数据写入过程
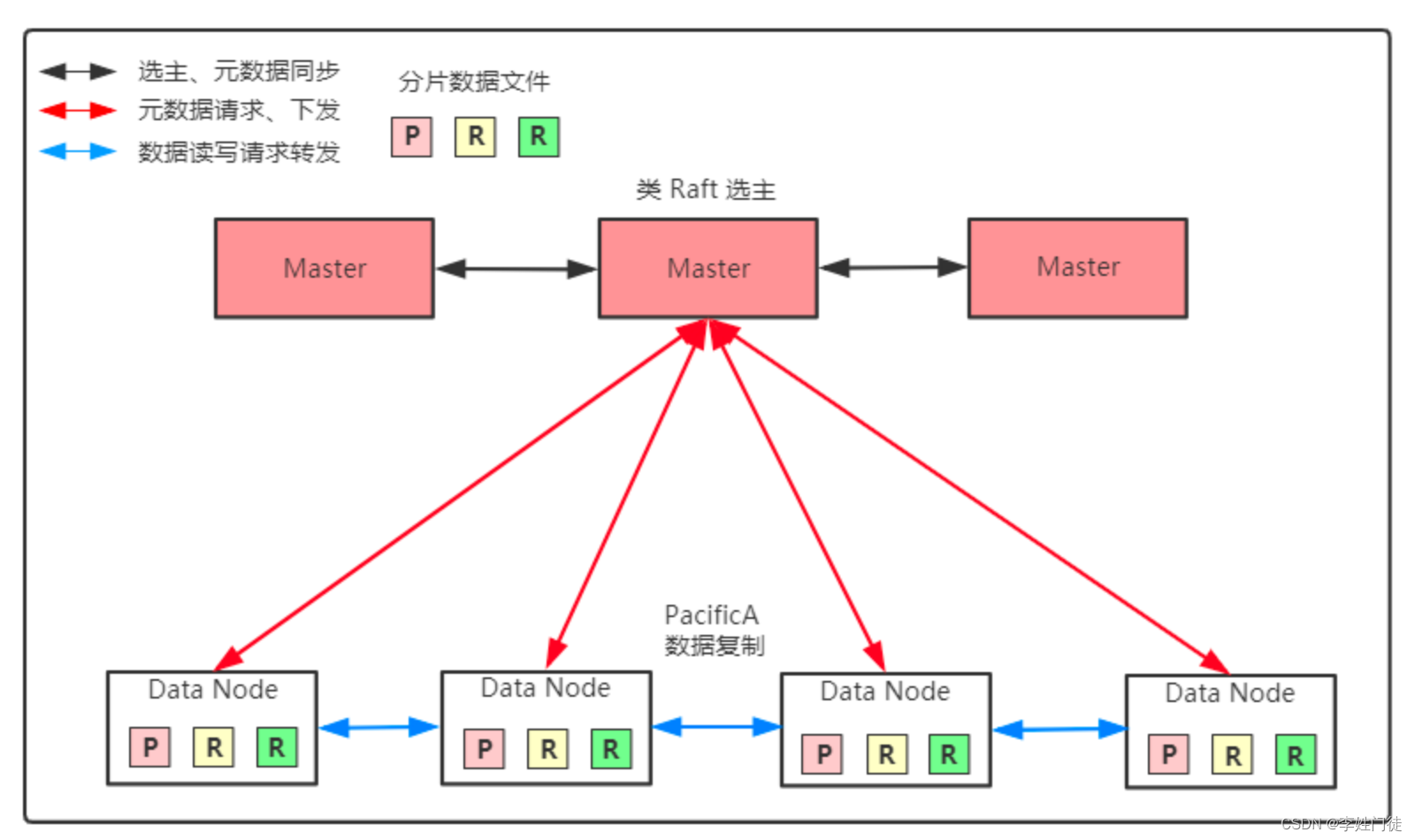
在协调节点根据 hash(routing)% 主分片数量 的值来找数据所在主分片的服务器节点。如果改了主分片数量会导致找不到数据。主分片无法改变数量副本分片可以成倍的扩容。一个索引由多个分片组成,一个分片有一个主节点和多个副本节点。写入的过程中默认写入主分片即为成功可以调整参数wait_for_active_shards,如果设置为all那么写入所有的副本分片才视为成功这样也可以保证读写数据的一致性,不然有可能写入主分片还没有写入副本分片读的是副本分片。
1.写入原理
es写入使用了多个副本来保障高可用,一个主分片多个副本分片。es基于lucence,使用延时写入的方式每隔一段时间(30min)才会把lucene的segement写入磁盘持久化,在es中采用了预写日志的机制。
数据写入 – lucene
lucene – segment – segment磁盘
内存1s生成一个segment 每30分钟写入segment磁盘
写到lucene时候是检索不到了,需要写入segment才可以被用户检索到所以es是近实时的全文检索。getid的时候是实时的通常我们用的match查询都是近实时
lucene – translog -translog磁盘
顺序写5s刷新到-translog磁盘
2.translog预写日志
es中1s生成一个segment30分钟写入segment磁盘,这样数据30分钟才可以持久化到磁盘,es引入translog预写日志以顺序写的方式写到磁盘1次提供持久性保障。类似mysql的redolog。不过mysql是先写redolog,es是先写lucene后写translog因为es内存结构比较复杂如果先写translog后写lucene可能失败,这样translog还要回滚,es设计默认写translog不会失败。 translog在es数据写入segment磁盘后通过还原点删除。
3.es的数据存储
倒排索引:词项、文档id、文档位置、相关性评分
倒排索引写入磁盘后是不可改变的。
1.段
分片下的索引文件被拆分为多个子文件,每个子文件叫作段, 每一个段本身都是一个倒排索引,并且段具有不变性,一旦索引的数据被写入硬盘,就不可再修改。
2.段合并
每1s一个段,会有大量段新增,这样消耗服务器句柄数消耗内存,段太多查询卡顿。
启动段合并搜索不会中断,合并时候会把小的段合成大的段然后把原来的段删除。
4.elk
1.elk概念
elk分别表示elasticsearch、logstash、kibana
elasticsearch是强大的数据搜索全文检索引擎
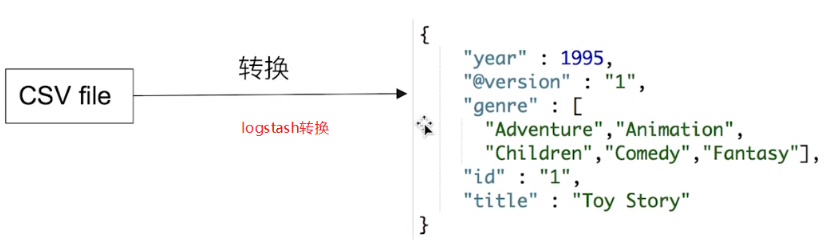
logstash是开源的数据处理通道,呢呢狗狗从多个来源搜集数据,能够对数据进行转换以及清洗,可以将转换后的数据发送到db。
kibana是es的可视化平台,可以以图表的形式展示es数据,并提供可操作界面。
2.elk能做什么
1.日志搜集
随着项目的增大我们服务器的集群可能是几十上百台这时候我们查询日志十分麻烦需要集中化的日志管理将所有服务器节点上的日志统一收集管理
大致工作流程:
filebeat(根据配置的路径收集日志) – kafka集群(数据缓冲削峰填谷) – logstash(数据清洗、转换) – es(存储、分析) – kibana(展示、告警) – 用户查看
2.异构数据同步
可以借助elk将关系型数据库的数据同步到es中。
大致工作流程:
mysql – canal(监听binlog收集数据配置的形式扔到mq中) – mq(数据缓存削峰填谷)– logstash(数据清洗、转换) – es (存储、分析)– kibana
1.canal
canal是阿里研发的组件,主要支持了mysql的binlog解析,解析完成后才利用canal client处理相关数据
canal将自己伪装成mysql slave向mysql master发送dump协议,mysql master收到canal发送过来的dump请求,开始推送binlog 给canal ,然后canal解析binlog再发送数据到存储中间件。
原文地址:https://blog.csdn.net/qq_35623417/article/details/135747199
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_62599.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!