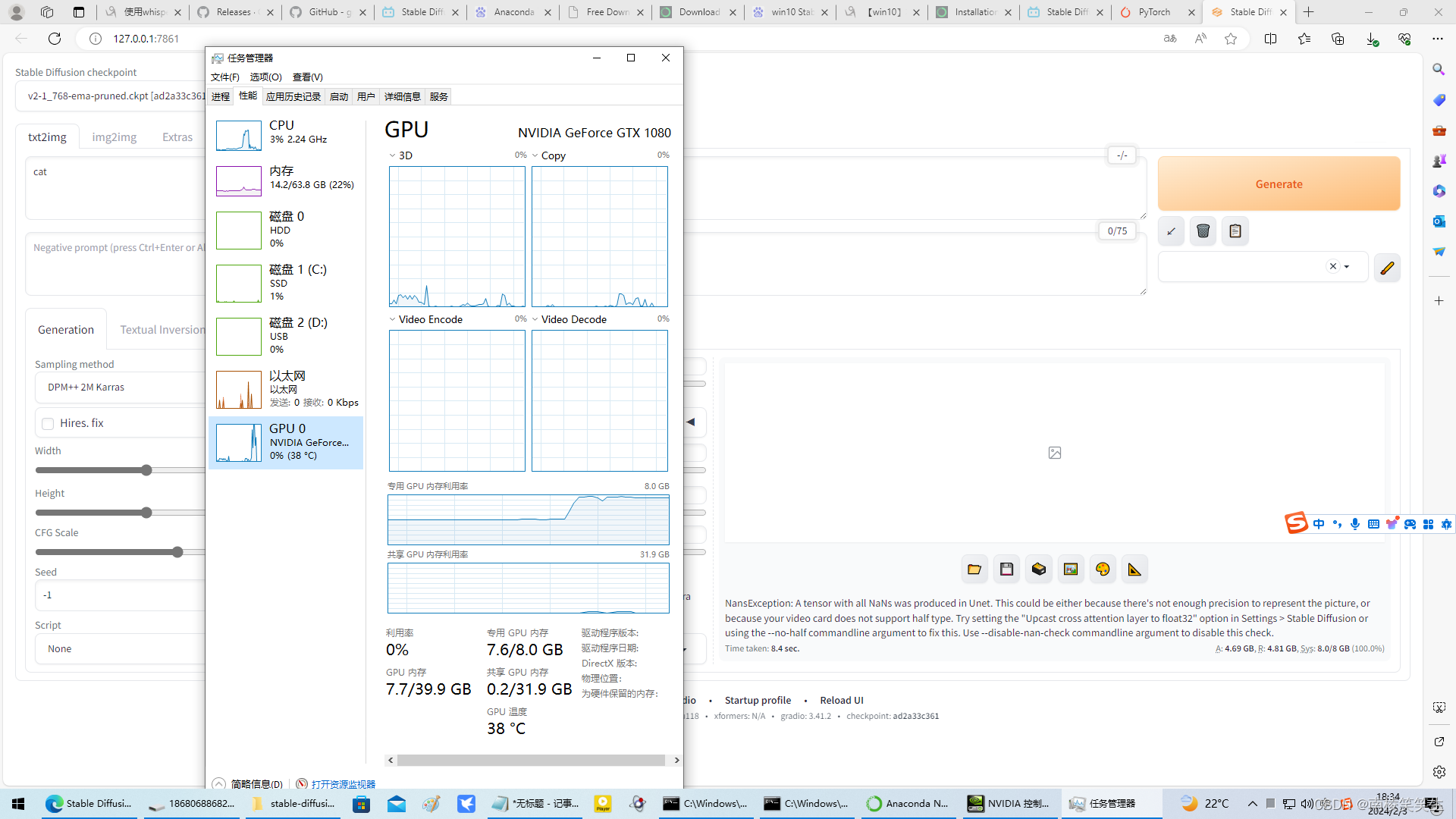
本文介绍: 不知道是不是玩novelai被boss看到了,推荐了我学。
不知道是不是玩novelai被boss看到了,推荐了我学stable diffusion
扩散模型
DALL E
Midjourney
stable diffusion
latent diffusion
说是改进点在于“给输入图片压缩降低维度,所以有个latent,从而减少计算量”,类似于下采样吧,编码后在特征空间搞动作,而不是像diffusion那样直接在像素上搞动作。当然减少计算量的代价就是细节的丢失。
-》stable diffusion
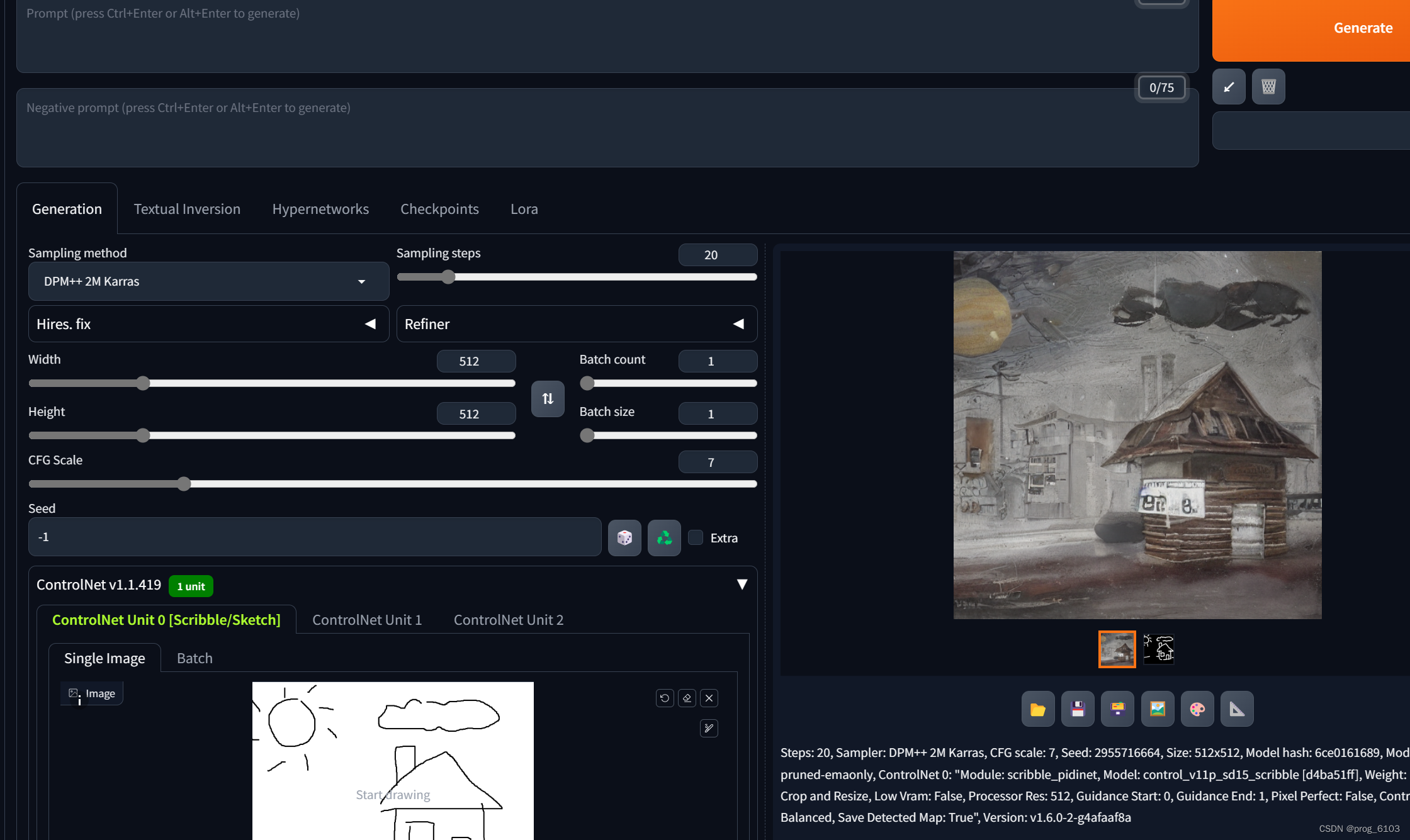
diffusion
文本-》CLIP的文本编码器-》diffusion(unet+scheduler)-》VAE的解码器
关于图像生成,提到了“给原始图片逐渐加入噪声,然后再逐步去除噪声以还原图片”这个过程,可以理解为生成模块学习到了哪些像素是必需的,哪些像素是无关紧要的,识别和保留那些对于图像的整体结构和识别最为重要的特征,同时忽略或去除那些不影响图像识别或结构的变化。这对于生成图像、图像编辑、图像压缩等任务特别有用,因为它使模型能够创造出既精确又具有视觉上可信度的结果。

有文本提示生成的噪声和无文本提示生成的噪声相减,得到文本带来的噪声变化,将这个噪声变化视作信号放大(这个放大倍数7.5就是UI上的guidance scale参数)后,再附加到无提示的噪声上就得到了一个心仪的噪声
其中50是个噪声步长scheduler,相当于指示加入噪声的程度,刚才得到的心仪噪声是50对应的噪声变化量加到49对应的无提示噪声上,从而这样一步步重构原图去除噪声
所以负向提示其实就是让正向提示噪声-负向提示噪声,从而原理负向提示
VAE
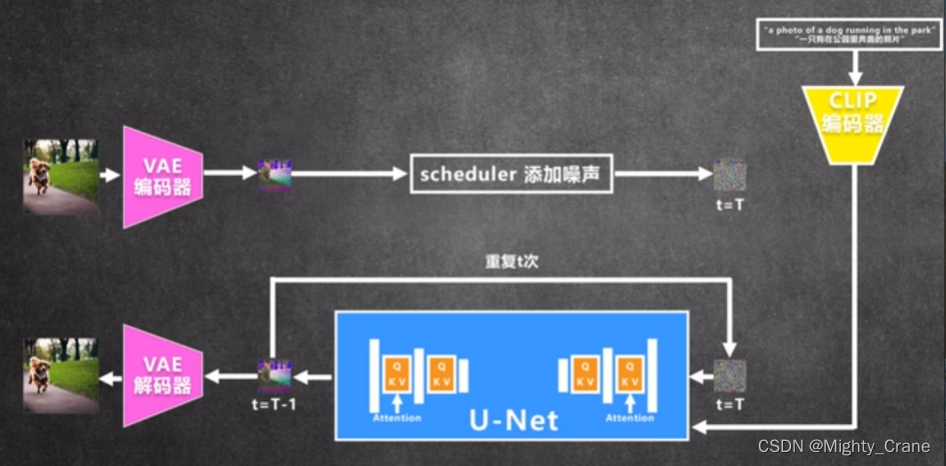
其他模型
dreambooth
LORA
textual inversion
controlnet
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。