1 你知道哪几种垃圾收集器,各自的优缺点是啥,重点讲下cms和G1,包括原理,流程,优缺点?
1)首先简单介绍下 有以下这些垃圾回收器
Serial收集器: 单线程的收集器,收集垃圾时,必须stop the world,使用复制算法。
ParNew收集器: Serial收集器的多线程版本,也需要stop the world,复制算法。
Parallel Scavenge收集器: 新生代收集器,复制算法的收集器,并发的多线程收集器,目标是达到一个可控的吞吐量。如果虚拟机总共运行100分钟,其中垃圾花掉1分钟,吞吐量就是99%。
Serial Old收集器: 是Serial收集器的老年代版本,单线程收集器,使用标记整理算法。
Parallel Old收集器: 是Parallel Scavenge收集器的老年代版本,使用多线程,标记-整理算法。
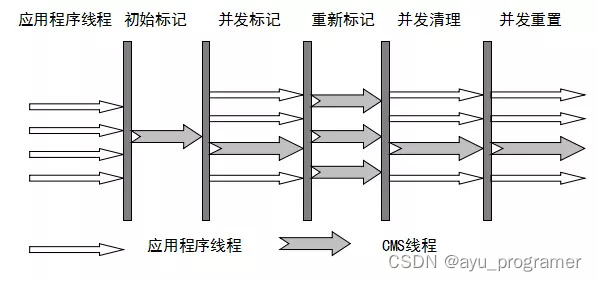
CMS(Concurrent Mark Sweep) 收集器: 是一种以获得最短回收停顿时间为目标的收集器,标记清除算法,运作过程:初始标记,并发标记,重新标记,并发清除,收集结束会产生大量空间碎片。
G1收集器: 标记整理算法实现,运作流程主要包括以下:初始标记,并发标记,最终标记,筛选标记。不会产生空间碎片,可以精确地控制停顿。(重点)
2)CMS收集器和G1收集器的区别:
2详细介绍一下 CMS 垃圾回收器?
首先CMS垃圾收集器是一种
1 老年代的垃圾收集器,
2 是以牺牲吞吐量为代价来获取最短回收停顿时间的垃圾回收器,
3 多线程并发的标记-清除算法,所以在gc的时候会产生大量的内存碎片,当剩余内存不能满足程序运行要求时,系统将会出现 Concurrent Mode Failure,临时 CMS 会采用 Serial Old 回收器进行
垃圾清除,此时的性能将会被降低。
CMS 工作机制相比其他的垃圾收集器来说更复杂。
整个过程分为以下 4 个阶段:
初始标记
只是标记一下 GC Roots 能直接关联的对象,速度很快,仍然需要暂停所有的工作线程。