本文介绍: 1、压力比较大的服务中,尽量不要存放大量的缓存或者定时任务,会影响到服务的内存使用。2、内存分析发现有大量线程创建时,可以使用导出线程栈来查看线程的运行情况。3、如果请求确实创建了大量的内存超过了内存上限,只能考虑减少请求时创建的对象,或者使用更大的内存。4、推荐使用g1垃圾回收器,并且使用较新的JDK可以获得更好的性能。
GC调优
GC调优指的是对 垃圾回收(Garbage Collection) 进行调优。GC调优的主要目标是避免由垃圾回收引起程序性能下降。
GC调优的核心分成三部分:
1、通用Jvm参数的设置。
2、特定垃圾回收器的Jvm参数的设置。
3、解决由频繁的FULLGC引起的程序性能问题。
GC调优没有没有唯一的标准答案,如何调优与硬件、程序本身、使用情况均有关系,重点学习调优的工具和方法。
GC调优的核心指标
吞吐量
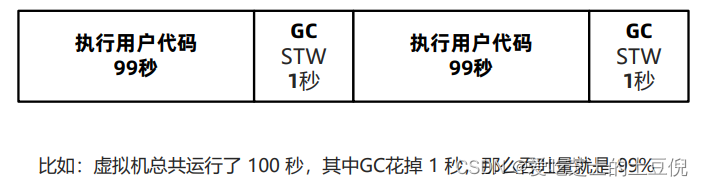
延迟

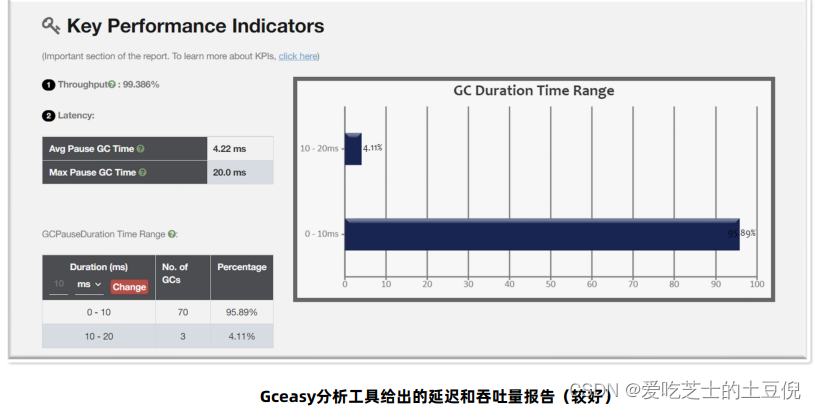
内存使用量

GC调优的方法
发现问题
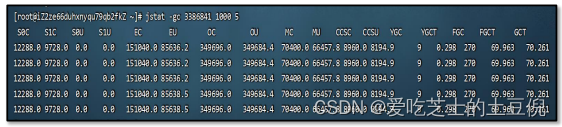
jstat工具
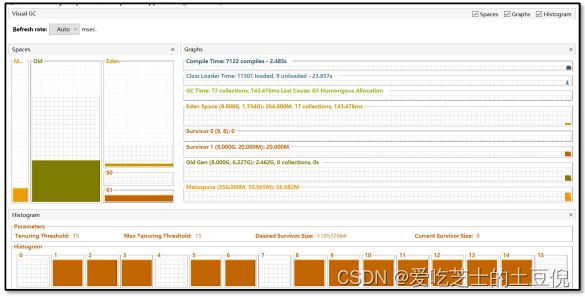
visualvm插件
Prometheus + Grafana
GC日志

GC Viewer
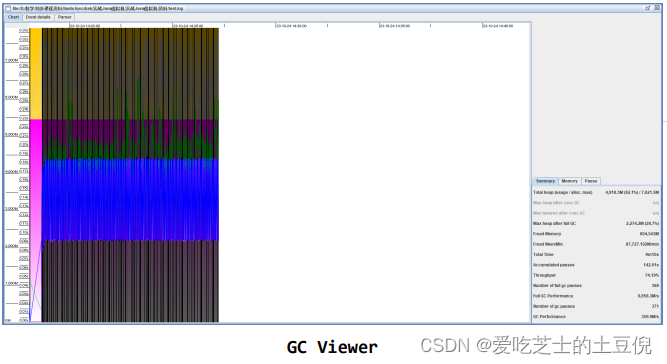
GCeasy

常见的GC模式
正常情况
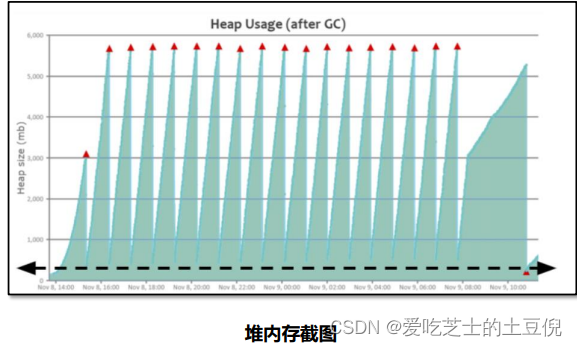
缓存对象过多

内存泄漏
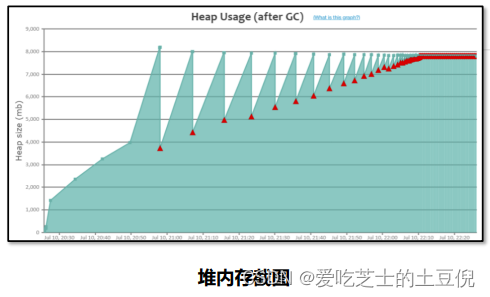
持续的FullGC
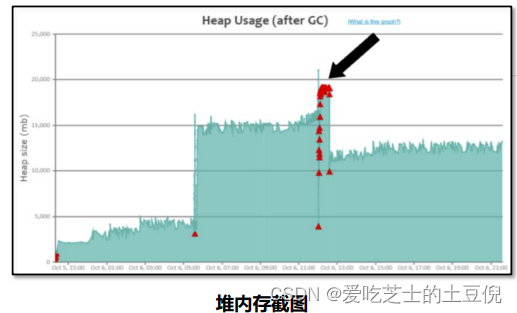
元空间不足导致的FULLGC
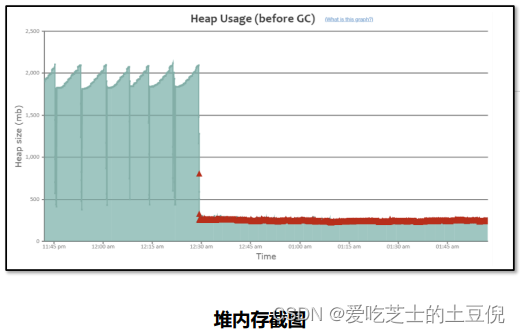
解决GC问题的手段

优化基础JVM参数
参数1 : -Xmx 和 –Xms

参数2 : -XX:MaxMetaspaceSize 和 –XX:MetaspaceSize

参数3 : -Xss虚拟机栈大小
参数4 : 不建议手动设置的参数

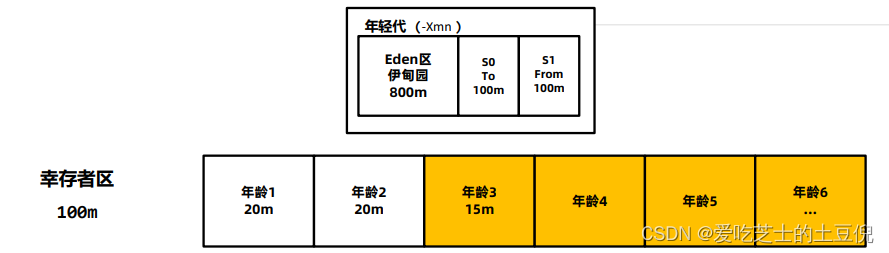
JVM参数模板:
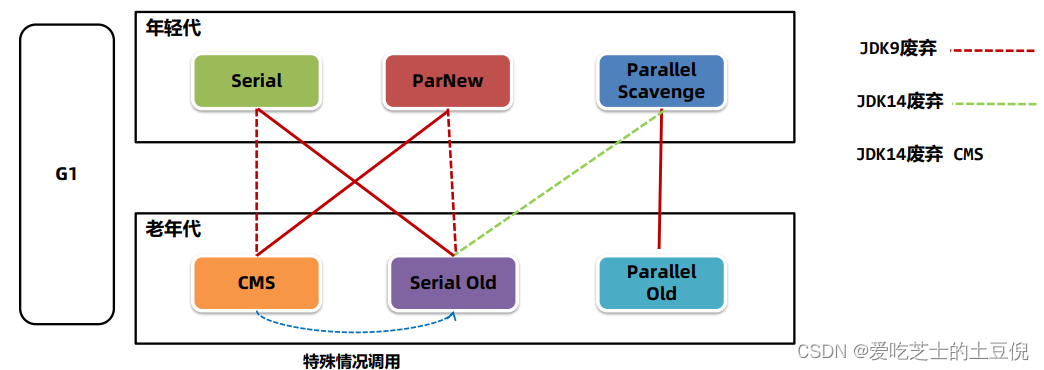
垃圾回收器的选择
垃圾回收器的组合关系
优化垃圾回收器的参数
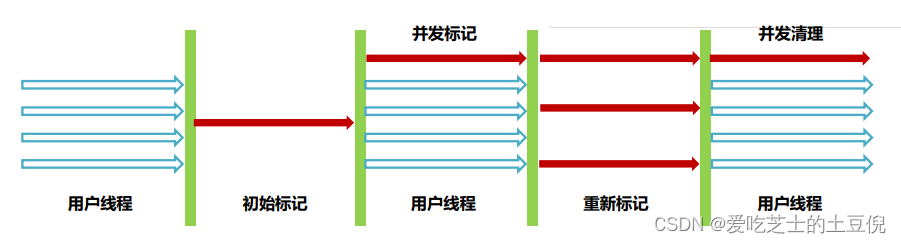
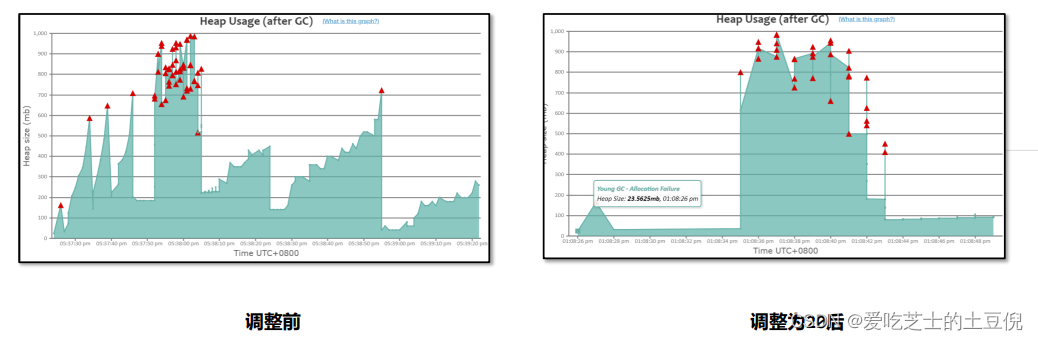
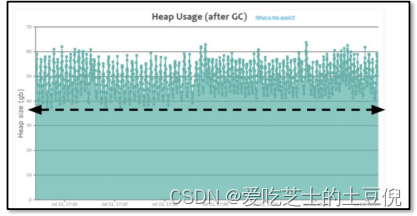
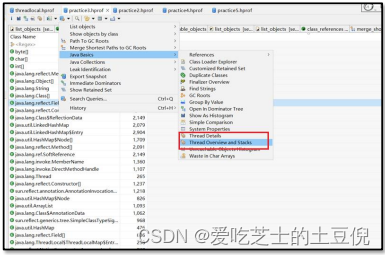
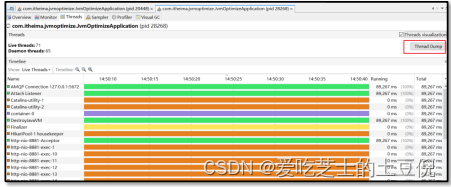
案例实战
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。