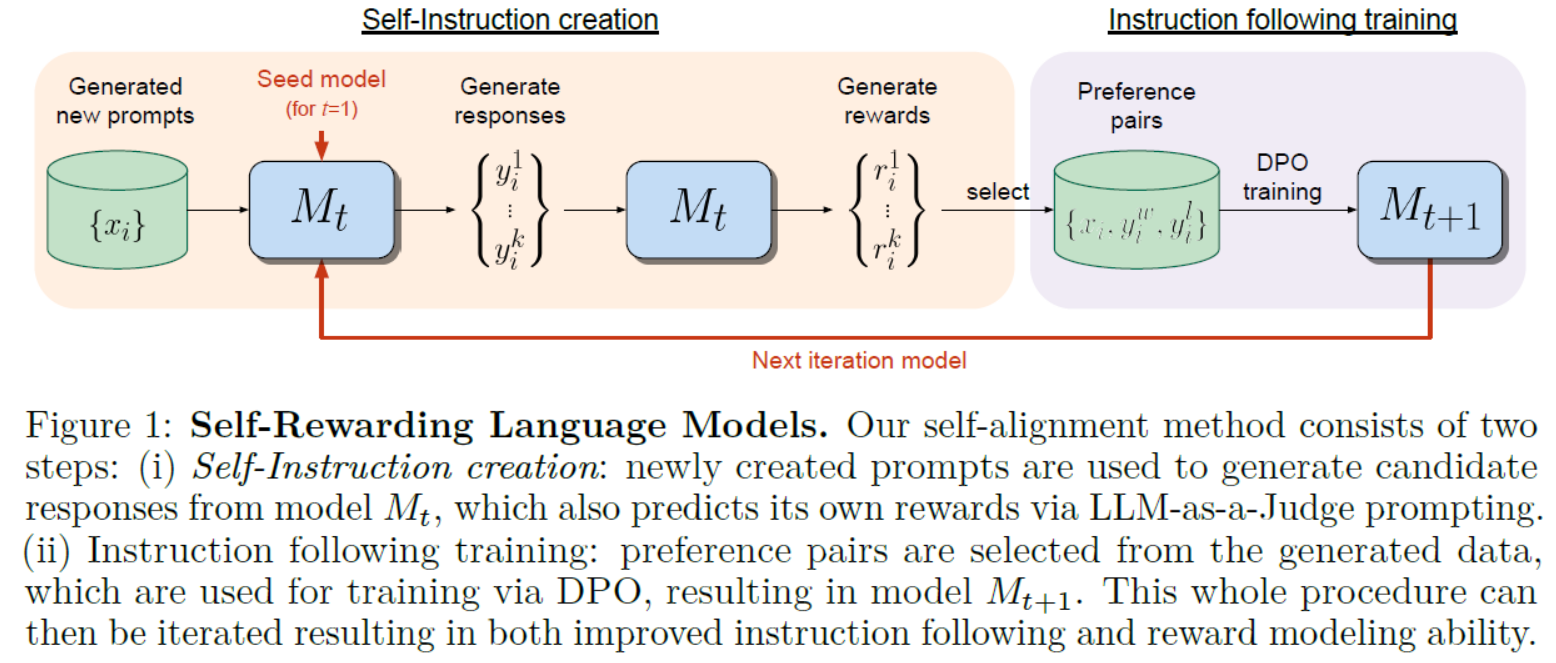
本文介绍: 1. 有时候我们输入转化后的一组向量之间会有关联。比如 “I saw a saw—–我看见一把锯子” 这句话,对于传统的模型,可能会将第一个 saw 和第二个 saw 输出相同的结果,但事实上两个 saw 是完全不一样的意义,第一个 saw 意思是”看见”,而第二个 saw 意思是”锯子”。2. 所以出现了自注意力机制(Self-attention)模型来解决上述这个问题。对于输入 Seg 中向量不确定多的情况,Self-attention会考虑所有向量。
一、输入与输出
1. 一般情况下在简单模型中我们输入一个向量,输出结果可能是一个数值或者一个类别。但是在复杂的模型中我们一般会输入一组向量,那么输出结果可能是一组数值或一组类别。

2. 一句话、一段语音、一张图等都可以转换成一组向量。




二、Self-attention
2.1 介绍


2.2 运作过程







2.3 矩阵相乘理解运作过程


三、位置编码




四、Truncated Self-attention
4.1 概述


4.2 和CNN对比



4.3 和RNN对比


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。