本文介绍: 主数据区域中保留了数据仓库的所有基础数据及历史数据,是数据仓库中最重要的数据区域之一,那主数据区域中主要分为近源模型区和整合(主题)模型区。上一节讲到了模型的设计流程如下图所示。那近源模型层的设计在第2.3和3这两个步骤中相对简化,模型表设计的结构同源系统的表结构,字段也一一映射即可。那下面以整合(主题)模型的设计步骤来进行介绍:整合(主题)模型层主要按主题进行数据整合,以第3范式为主进行表设计,有以下优点:(1)主题模型从全行角度对客户、产品、交易、账户等进行分类梳理,获得全行业务数据视图;
主数据区域中保留了数据仓库的所有基础数据及历史数据,是数据仓库中最重要的数据区域之一,那主数据区域中主要分为近源模型区和整合(主题)模型区。上一节讲到了模型的设计流程如下图所示。那近源模型层的设计在第2.3和3这两个步骤中相对简化,模型表设计的结构同源系统的表结构,字段也一一映射即可。那下面以整合(主题)模型的设计步骤来进行介绍:
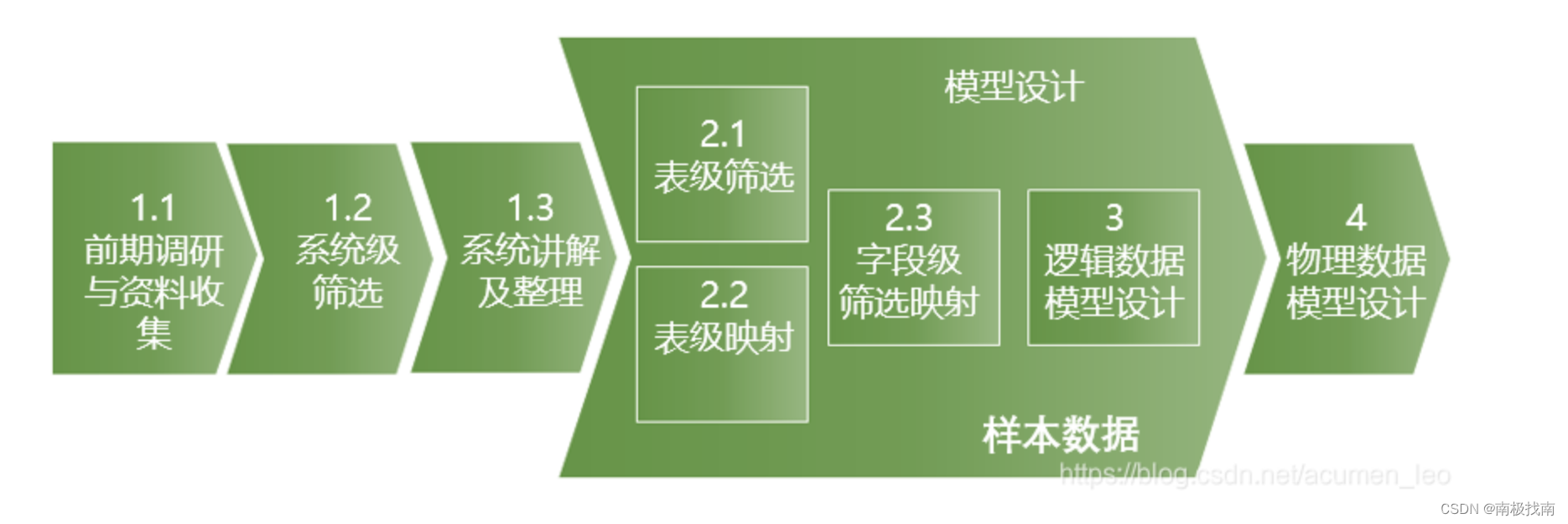
整合(主题)模型层主要按主题进行数据整合,以第3范式为主进行表设计,有以下优点:
(1)主题模型从全行角度对客户、产品、交易、账户等进行分类梳理,获得全行业务数据视图;
(2)数据模型比较稳定,只要业务实体关系没有大的变化,不会因为源系统替换或升级导致整合模型出现大的变动。对于数据使用系统和集市来说比较稳定。
(3)模型灵活易扩展,在增加功能的时可扩展模型,不需要重构数据模型,不影响已有数据实体。
1、主题模型设计步骤
1.1系统调研及筛选
1.2确定入仓表及字段


1.3逻辑模型设计
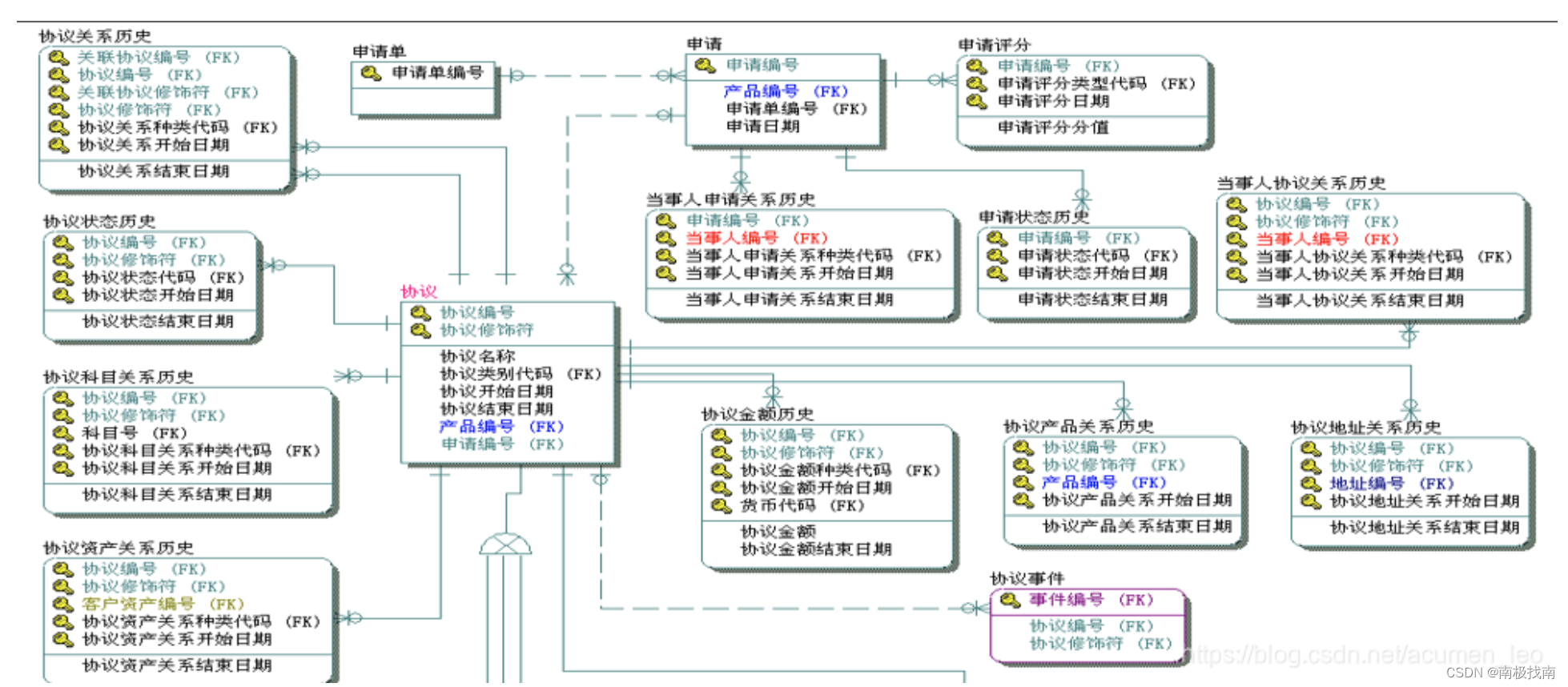
1.4物理模型设计
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






