项目代码地址:
02-basicgrammar
基础语法
值
- 基本类型值
Go 最基础的数据类型,比如整型、浮点型、布尔型。
- 复合类型值
由基本类型组成的复杂数据类型,比如数组、切片、结构体、函数、map、通道、接口、字符串。
- 指针类型值
指针类型的变量与指针类型值绑定,它内部存储的是另外一个内存单元的地址。
简单示例:
// 值
func function01() {
fmt.Println(123_456) // 123456
fmt.Println("go" + "lang") // golang
fmt.Println("1 + 1 = ", 1+1) // 1 + 1 = 2
fmt.Println("3 / 2 = ", 3/2) // 3 / 2 = 1
fmt.Println("7.0 / 3 = ", 7.0/3) // 7.0 / 3 = 2.3333333333333335
fmt.Println(true && false) // false
fmt.Println(true || false) // true
fmt.Println(!true) // false
}
Go 中的值类型和引用类型:
- 值类型:int系列、float系列、bool、string、数组、结构体
- 引用类型:指针、slice切片、管道channel、接口interface、map、函数
值类型:变量直接存储值,内存通常在栈中分配
引用类型:变量存储的是一个地址,地址空间存储真正的值,内存通常在堆中分配
在Go语言中,所有东西都是以值的形式存在的,只有值传递没有引用传递。
- 传值:你是你,我是我
- 传指针:你是你,我是我,但我们共同指向他
- 传“引用”:你是你,我是我,但我们有一部分共同指向他
// 指针类型
func function02() {
a := 1
ptr := func(b *int) {
fmt.Println(&b, b) // 0xc000088028 0xc00000a0c8
*b = 2
fmt.Println(*b) // 2
}
fmt.Println(&a) // 0xc00000a0c8
ptr(&a)
fmt.Println(a) // 2
}
// 引用类型
func function03() {
s := []int{1, 2}
ref := func(a []int) {
fmt.Printf("%pn", &a) // 0xc000008060
a[1] = 0
fmt.Println(a) // [1 0]
}
fmt.Printf("%pn", &s) // 0xc000008048
ref(s)
fmt.Println(s) // [1 0]
}
不难看出,上述在传递参数过程中都是进行值传递的。尽管切片是引用类型,但传递时仍然会拷贝新的变量,只不过新变量的底层结构有对另一个基础类型的指向。
Go 的引用类型不同于 C++ 的引用,引用并不是同一个地址,不过底层指针是同一个指向。
对比 C++ 的引用:引用传递地址不变,a,b变量共享同一地址
#include<iostream>
using namespace std;
struct Node {
int a, b, c;
};
void func(Node &a) {
cout << &a << endl; // 0x7ffc43a4a21c
}
int main() {
Node b = {1, 2, 3};
func(b);
cout << &b << endl; // 0x7ffc43a4a21c
return 0;
}
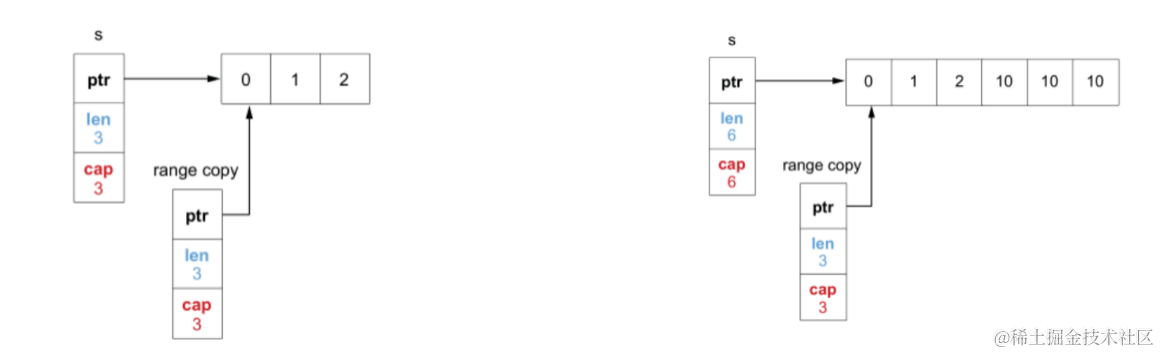
额外补充,切片容易踩的坑:
切片在运行时由三个字段构成,值拷贝创建副本也就是对 Data、Len、Cap字段进行拷贝,而 Data 指针指向与原slice 同一地址。
type SliceHeader struct {
Data uintptr // 指向底层数组的指针
Len int // 切片长度
Cap int // 切片容量
}
所以在副本中修改元素时,原 slice 的元素也会被修改。但是修改的是副本的 Len、Cap 时,原 slice 保持不变。如果副本由于扩容导致 Data 地址重新分配,那么之后副本的操作完全无法影响到原 slice。
// 传"引用"
func function04() {
a := make([]int, 1, 2) // 指定len(a)=1,cap(a)=2
a[0] = 1
fmt.Println(len(a), cap(a), a) // 1 2 [1]
ref := func(b []int) {
b[0] = 4
fmt.Println(len(b), cap(b), b, len(a), cap(a), a) // 1 2 [4] 1 2 [4]
b = append(b, 2)
fmt.Println(len(b), cap(b), b, len(a), cap(a), a) // 2 2 [4 2] 1 2 [4]
b[0] = 0
fmt.Println(len(b), cap(b), b, len(a), cap(a), a) // 2 2 [0 2] 1 2 [0]
b = append(b, 3)
fmt.Println(len(b), cap(b), b, len(a), cap(a), a) // 3 4 [0 2 3] 1 2 [0]
b[0] = 1
fmt.Println(len(b), cap(b), b, len(a), cap(a), a) // 3 4 [1 2 3] 1 2 [0]
}
ref(a)
}
上面的例子阐明了两点:
- “引用” 是我们共同一部分指向它:b 添加元素后,len 变为 2,而原 a 的 len 还是 1,所以切片的第一个元素是被共同指向的
- 扩容后“引用”的元素地址改变:b 扩容后,cap 变为 4,Data 地址改变,再修改第一个元素时,不再能影响原 a 的元素
如果上述不能理解,可以先放着,等下章学习了切片等类型后,再来回顾。
变量
常用两种声明变量格式:
-
var用来声明变量,标准声明格式:var 变量名 变量类型 -
:=短变量只能用于声明局部变量,不能用于全局变量声明,即在函数或方法内部使用。
变量只声明未初始化,则为默认值。
// 变量
func function05() {
var a int64 // 声明未初始化,默认 int64(0)
var b string = "ABC" // 标准声明并初始化
var c = 1 // 自动类型推导
var d, e = 2, "3" // 一次初始化多个变量
// 批量声明
var (
f float64 = 3.1
g bool = false
)
h := .1 // 简短变量声明
fmt.Println(a, b, c, d, e, f, g, h) // 0 ABC 1 2 3 3.1 false 0.1
}
常量
var 换为 const 即可定义常量
// 常量
func function06() {
const pi = 3.1415
// 同时声明多个常量,某个常量省略值,则和上一个相同
const (
e = 2.7182
a // 2.7182
b // 2.7182
c = 3
d // 3
)
// iota 预声明标识符,表示连续的无类型整数常量,初始值 0
const (
level1 = iota + 1 // 1
level2 // 2
level3 // 3
_ // 跳过某些值
level5 // 5
n = 1000 // 在 iota 声明中插队
level6 = iota // 6, 需要再使用 iota
)
// 多个 iota 定义在一行,iota 值逐行增加
const (
A, B = iota + 1, iota + 2 // 1 2
C, D // 2 3
E, F // 3 4
)
// 用来定义数量级
const (
_ = iota
KB = 1 << (10 * iota) // 1 << (10 * 1)
MB = 1 << (10 * iota) // 1 << (10 * 2)
GM = 1 << (10 * iota) // 1 << (10 * 3)
TB = 1 << (10 * iota) // 1 << (10 * 4)
)
}
运算符
需要注意的是
++(自增)和--(自减)在 Go 中是单独的语句,并不属于运算符&^按位清除;z := x &^ y,y 中位 1,z 位 0,y 中位 0,z 位为 x 位
// 运算符
func function10() {
var a int
a++
fmt.Println(a) // 1
// b := a-- 错误!i++、i--只能单独使用
// ++a 错误!没有 ++i、--i 操作
x := 11
y := (1 << 0) | (1 << 3) // 保证 z 中的第 0 位和第 3 位为 0
z := x &^ y
fmt.Printf("x = %bn", x)
fmt.Println("t&^")
fmt.Printf("y = %bn", y)
fmt.Println("————————")
fmt.Printf("z = %04bn", z)
/*
x = 1011
&^
y = 1001
————————
z = 0010
*/
}
指针
指针用法和其他语言类似,而且 Go 中使用了垃圾回收机制,不需要手动释放内存。
// 指针
func function15() {
str := "123"
var strPtr *string = &str
fmt.Println(str, *strPtr) // 123 123
fmt.Println(&str, strPtr, &strPtr) // 0xc000026070 0xc000026070 0xc000088020
}
new 和 make 区别
Go 语言中 new 和 make 是内建的两个函数,主要用来分配内存。
-
new:用于类型的内存分配,返回值是一个指向新分配类型零值的指针 -
make:只用于 slice、map、channel 初始化,返回这三个引用类型本身
// new、make
func function16() {
a := new(bool)
fmt.Printf("%T %t %vn", a, *a, a) // *bool false 0xc000192068
b := make([]int, 1, 2)
fmt.Printf("%T %v %p %p %pn", b, b, b, &b, &b[0]) // []int [0] 0xc0001920b0 0xc000190030 0xc0001920b0
}
这里重点关注 make 后返回的切片引用类型本身 b,可见 b 和 &b[0] 的地址是一样的,都是指向底层数组的指针。而 &b 则是表示当前这个切片结构体的地址。
字符串
在运行时字符串类型表示如下:
type StringHeader struct {
Data uintptr // 指向底层字节数组指针
Len int // 字节数组长度
}
Go 在编程语言层面对值做了限制,常量值是不可变的,字符串类型值是不可变的,其他则为可变值。
Go 中只允许用双引号和反引号定义字符串,使用单引号定义字符类型。字符串是一个只读的 byte 类型切片,组成每个字符串的元素叫字符,字符变量默认 rune 型。
// 字符串
func function07() {
s1 := "123"
s2 := "字符串"
s3 := `第一行
第二行
第三行
`
// s1[0] = '4' // 不能修改
s1 += "456" // 123456
fmt.Println(len(s1), len(s2), len(s3)) // 3 9 30
}
byte 和 rune 类型
Go 语言字符有两种类型,byte 代表 ASCII 码的一个字符,rune 代表一个 UTF-8 字符。
byte型,本质上是uint8rune型,本质上是int32
特殊的 rune 类型表示 Unicode 编码的整数,能让基于 Unicode 的文本处理更方便,比如处理中文或其他复合字符。
-
内建函数
len()函数用来获取字符串的 ASCII 字符个数或字节长度。Go 语言的字符串都以 UTF-8 格式保存,每个中文占用 3 个字节 -
unicode/utf8包提供的utf8.RuneCountInString()函数用来统计 Unicode 字符数量 -
unsafe包提供的unsafe.Sizeof返回数据类型的大小 -
for 循环遍历,对应 ASCII 码;for range 遍历,对应 Unicode 码
// byte、rune
func function08() {
var a = 'a'
var b byte = 'b'
fmt.Println(unsafe.Sizeof(a), unsafe.Sizeof(b)) // 4 1
s1 := "Golang语言"
fmt.Println(len(s1), utf8.RuneCountInString(s1)) // 12 8
for i := 0; i < len(s1); i++ {
fmt.Printf("%c", s1[i])
} // Golangè¯è¨
fmt.Println()
for _, s := range s1 {
fmt.Printf("%c", s)
} // Golang语言
}
读者可能会疑惑,之前代码中 s1 += "456" 这不是修改了字符串本身了吗?
func function09() {
// 仅声明字符串
var str string
var stringHeader = (*reflect.StringHeader)(unsafe.Pointer(&str))
fmt.Printf("%p %p %dn", &str, unsafe.Pointer(stringHeader.Data), stringHeader.Len)
// 字符串赋值
str = "快速入门"
fmt.Printf("%p %p %dn", &str, unsafe.Pointer(stringHeader.Data), stringHeader.Len)
// 字符串拼接
str += "GO语言"
fmt.Printf("%p %p %dn", &str, unsafe.Pointer(stringHeader.Data), stringHeader.Len)
// 字符串转 byte 切片
var bytes = []byte(str)
fmt.Printf("%p %p %dn", bytes, unsafe.Pointer(stringHeader.Data), stringHeader.Len)
bytes[3] = 1
fmt.Println(str)
// 0拷贝 byte 切片转换
var bytes1 = *(*[]byte)(unsafe.Pointer(&str))
fmt.Printf("%p %p %dn", bytes1, unsafe.Pointer(stringHeader.Data), stringHeader.Len)
bytes1[3] = 1
fmt.Println(str)
}
0xc000026070 0x0 0
0xc000026070 0x541808 12
0xc000026070 0xc000012108 20
0xc000012120 0xc000012108 20
快速入门GO语言
0xc000012108 0xc000012108 20
快��入门GO语言
unsafe.Pointer 类似于 C 语言中的 void * 指针,能接收任意类型的指针变量转为通用型指针,再可强转为其他指针类型。
分析上述代码:字符串在赋值和拼接后,实际变量的地址没发生变化,但是 stringHeader 的 Data 字节数组改变了地址,证明字符串本身不可被修改,变的是内部的字节数组。上述进行了强转 byte 字节数组,会实际拷贝一份 string 内部的字节数组,要想实现 0 拷贝,则可通过 unsafe.Pointer 转换。
流程控制
for 循环
基本格式:
for 初始语句; 条件表达式; 结束语句 {
循环体
}
for – range 循环:
- 数组、切片、字符串返回索引和值
- map返回键和值
- 通道(channel)只返回通道内的值
基本格式:
for k, v := range x {
}
常见的循环写法:
// for
func function11() {
i := 1
for i < 2 {
fmt.Println(i)
i++
} // 1
for j := 8; j < 9; j++ {
fmt.Println(j)
} // 8
for {
fmt.Println("loop")
break
} // loop
for n := 1; n <= 3; n++ {
if n%2 == 0 {
continue
}
fmt.Println(n)
} // 1 3
var num int
flag:
num++
for num <= 3 {
fmt.Println(num)
goto flag
} // 1 2 3
s := []int{11, 12}
for k, v := range s {
fmt.Println(k, v)
} // 0 11; 1 12
}
If else 分支
// if-else
func function12() {
score := 70
if score < 60 {
fmt.Println("不及格")
} else if score >= 60 && score <= 80 {
fmt.Println("良好")
} else {
fmt.Println("优秀")
} // 良好
if err := 1; err != 0 {
fmt.Println("没有出错")
} // 没有出错
}
switch 分支
switch 不同于 C 语言,break 不写会跳出 case,并且一个分支可以有多个值:
// switch case
func function13() {
switch suf := ".a"; suf {
case ".html":
fmt.Println("页面")
case ".doc", ".txt":
fmt.Println("文档")
case ".js":
fmt.Println("脚本文件")
default:
fmt.Println("其它后缀")
} // 其它后缀
}
为了兼容 C 语言的 case 设计,fallthrough 语法可以执行满足条件的 case 的下一个case:
// fallthrough
func function14() {
var suf = ".doc"
switch suf {
case ".html":
fmt.Println("页面")
case ".doc":
fmt.Println("文档")
fallthrough
case ".js":
fmt.Println("脚本文件")
default:
fmt.Println("其它后缀")
} // 文档 脚本文件
}
原文地址:https://blog.csdn.net/qq_52678569/article/details/135852821
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_63077.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!