文章目录
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的中文情感分类
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 情感文本分类
2.1 参考论文
Convolutional Neural Networks for Sentence
Classification
模型结构
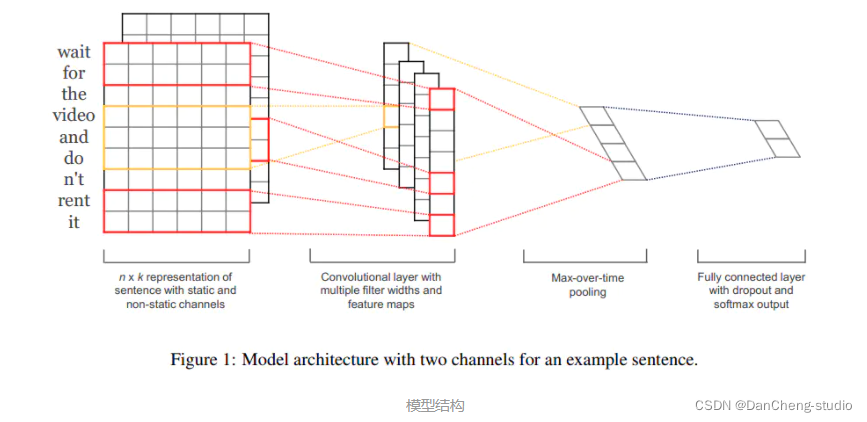
在短文本分析任务中,由于句子句长长度有限、结构紧凑、能够独立表达意思,使得CNN在处理这一类问题上成为可能,主要思想是将ngram模型与卷积操作结合起来
2.2 输入层
如图所示,输入层是句子中的词语对应的wordvector依次(从上到下)排列的矩阵,假设句子有 n 个词,vector的维数为 k ,那么这个矩阵就是 n
× k 的(在CNN中可以看作一副高度为n、宽度为k的图像)。
这个矩阵的类型可以是静态的(static),也可以是动态的(non static)。静态就是word
vector是固定不变的,而动态则是在模型训练过程中,word vector也当做是可优化的参数,通常把反向误差传播导致word
vector中值发生变化的这一过程称为Fine tune。(这里如果word
vector如果是随机初始化的,不仅训练得到了CNN分类模型,还得到了word2vec这个副产品了,如果已经有训练的word
vector,那么其实是一个迁移学习的过程)
对于未登录词的vector,可以用0或者随机小的正数来填充。
2.3 第一层卷积层:
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 h ×k ,其中 h 表示纵向词语的个数,而 k 表示word
vector的维数。通过这样一个大型的卷积窗口,将得到若干个列数为1的Feature Map。(熟悉NLP中N-GRAM模型的读者应该懂得这个意思)。
2.4 池化层:
接下来的池化层,文中用了一种称为Max-over-timePooling的方法。这种方法就是简单地从之前一维的Feature
Map中提出最大的值,文中解释最大值代表着最重要的信号。可以看出,这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature
Map中有多少个值,只需要提取其中的最大值)。最终池化层的输出为各个Feature Map的最大值们,即一个一维的向量。
2.5 全连接+softmax层:
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,Softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。
2.6 训练方案
在倒数第二层的全连接部分上使用Dropout技术,Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了,它是防止模型过拟合的一种常用的trikc。同时对全连接层上的权值参数给予L2正则化的限制。这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
在样本处理上使用minibatch方式来降低一次模型拟合计算量,使用shuffle_batch的方式来降低各批次输入样本之间的相关性(在机器学习中,如果训练数据之间相关性很大,可能会让结果很差、泛化能力得不到训练、这时通常需要将训练数据打散,称之为shuffle_batch)。
3 实现
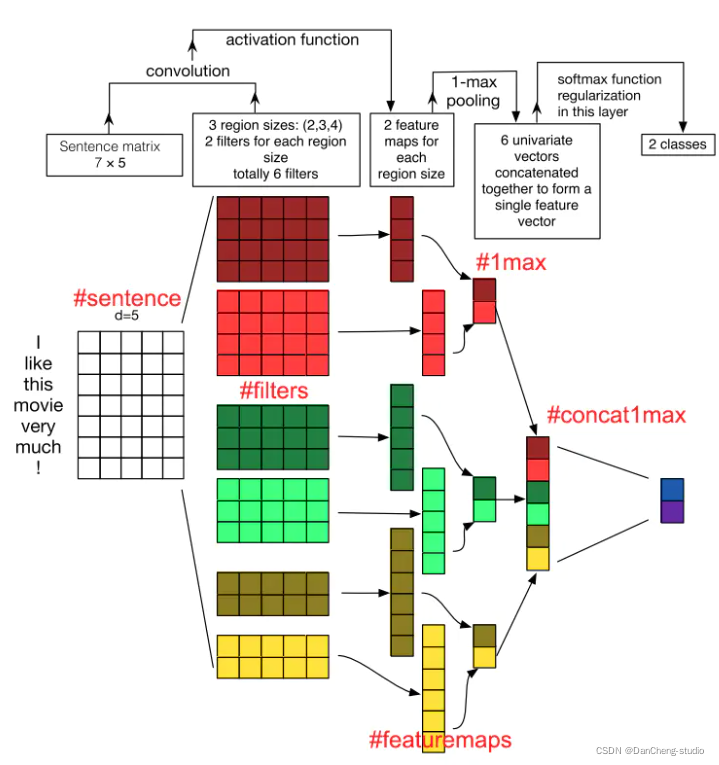
我们以上图为例,图上用红色标签标注了5部分,结合这5个标签,具体解释下整个过程的操作,来看看CNN如何解决文本分类问题的。
3.1 sentence部分
上图句子为“[I like this movie very much!”
,一共有两个单词加上一个感叹号,关于这个标点符号,不同学者有不同的操作,比如去除标点符号。在这里我们先不去除,那么整个句子有7个词,词向量维度为5,那么整个句子矩阵大小为7×5
3.2 filters部分
filters的区域大小可以使不同的,在这里取(2,3,4)3种大小,每种大小的filter有两个不同的值的filter,所以一共是有6个filter。
3.3 featuremaps部分
我们在句子矩阵和过滤器矩阵填入一些值,那么我们可以更好理解卷积计算过程,这和CNN原理那篇文章一样
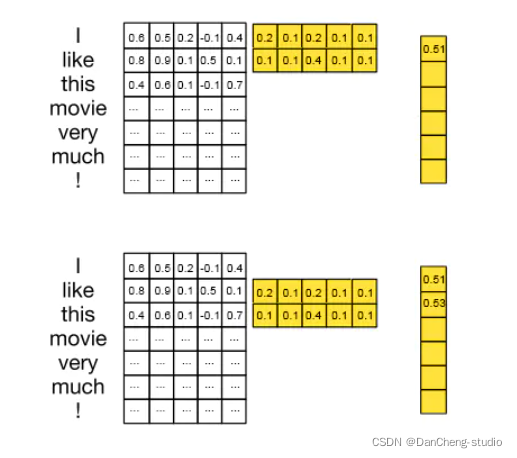
比如我们取大小为2的filter,最开始与句子矩阵的前两行做乘积相加,得到0.6 x 0.2 + 0.5 x 0.1 + … + 0.1 x 0.1 =
0.51,然后将filter向下移动1个位置得到0.53.最终生成的feature map大小为(7-2+1×1)=6。
为了获得feature map,我们添加一个bias项和一个激活函数,比如Relu
3.4 1max部分
因为不同大小的filter获取到的feature map大小也不一样,为了解决这个问题,然后添加一层max-
pooling,选取一个最大值,相同大小的组合在一起
3.5 concat1max部分
经过max-pooling操作之后,我们将固定长度的向量给sofamax,来预测文本的类别。
3.6 关键代码
下面是利用Keras实现的CNN文本分类部分代码:
# 创建tensor
print("正在创建模型...")
inputs=Input(shape=(sequence_length,),dtype='int32')
embedding=Embedding(input_dim=vocabulary_size,output_dim=embedding_dim,input_length=sequence_length)(inputs)
reshape=Reshape((sequence_length,embedding_dim,1))(embedding)
# cnn
conv_0=Conv2D(num_filters,kernel_size=(filter_sizes[0],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)
conv_1=Conv2D(num_filters,kernel_size=(filter_sizes[1],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)
conv_2=Conv2D(num_filters,kernel_size=(filter_sizes[2],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)
maxpool_0=MaxPool2D(pool_size=(sequence_length-filter_sizes[0]+1,1),strides=(1,1),padding='valid')(conv_0)
maxpool_1=MaxPool2D(pool_size=(sequence_length-filter_sizes[1]+1,1),strides=(1,1),padding='valid')(conv_1)
maxpool_2=MaxPool2D(pool_size=(sequence_length-filter_sizes[2]+1,1),strides=(1,1),padding='valid')(conv_2)
concatenated_tensor = Concatenate(axis=1)([maxpool_0, maxpool_1, maxpool_2])
flatten = Flatten()(concatenated_tensor)
dropout = Dropout(drop)(flatten)
output = Dense(units=2, activation='softmax')(dropout)
model=Model(inputs=inputs,outputs=output)
**main.py**
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # see issue #152
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import re
import numpy as np
from flask import Flask, render_template, request
from keras.models import load_model
from data_helpers_english import build_input_english
from data_helpers_chinese import build_input_chinese
app = Flask(__name__)
en_model = load_model('results/weights.007-0.7618.hdf5')
ch_model = load_model('results/chinese.weights.003-0.9083.hdf5')
# load 进来模型紧接着就执行一次 predict 函数
print('test train...')
print(en_model.predict(np.zeros((1, 56))))
print(ch_model.predict(np.zeros((1, 50))))
print('test done.')
def en_predict(input_x):
sentence = input_x
input_x = build_input_english(input_x)
y_pred = en_model.predict(input_x)
result = list(y_pred[0])
result = {'sentence': sentence, 'positive': result[1], 'negative': result[0]}
return result
def ch_predict(input_x):
sentence = input_x
input_x = build_input_chinese(input_x)
y_pred = ch_model.predict(input_x)
result = list(y_pred[0])
result = {'sentence': sentence, 'positive': result[1], 'negative': result[0]}
return result
@app.route('/classification', methods=['POST', 'GET'])
def english():
if request.method == 'POST':
review = request.form['review']
# 来判断是中文句子/还是英文句子
review_flag = re.sub(r"[^A-Za-z0-9(),!?'`]", " ", review) # 去除数字
review_flag = re.sub("[s+.!/_,$%^*(+"')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+", "", review_flag)
if review_flag:
result = en_predict(review)
# result = {'sentence': 'hello', 'positive': '03.87878', 'negative': '03.64465'}
return render_template('index.html', result=result)
else:
result = ch_predict(review)
# result = {'sentence': 'hello', 'positive': '03.87878', 'negative': '03.64465'}
return render_template('index.html', result=result)
return render_template('index.html')
#
# if __name__ == '__main__':
# app.run(host='0.0.0.0', debug=True)
4 实现效果
4.1 测试英文情感分类效果
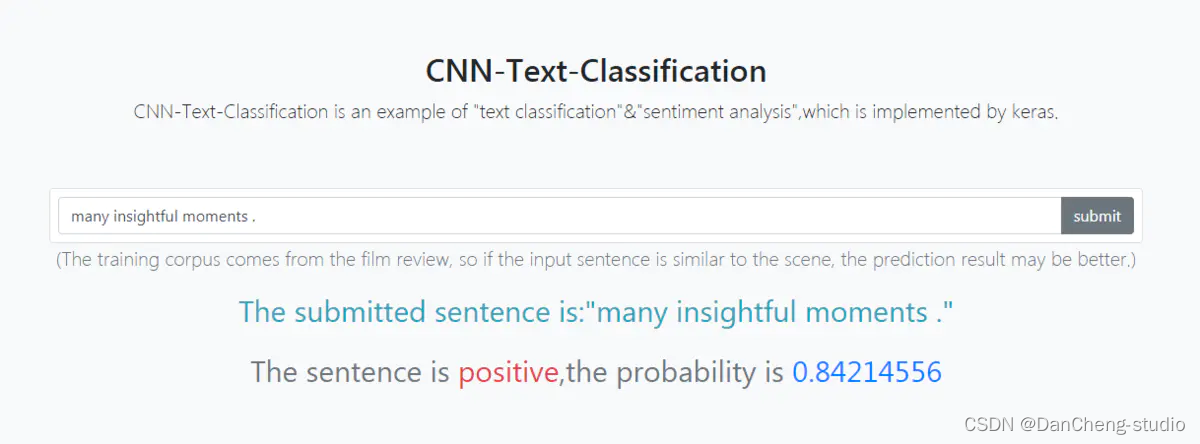
准训练结果:验证集76%左右
4.2 测试中文情感分类效果
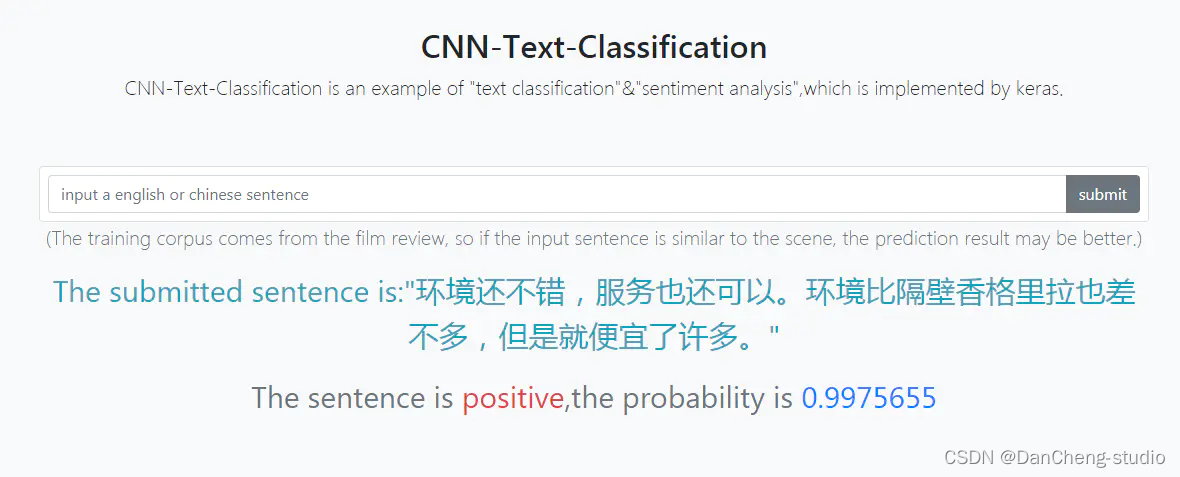
准训练结果:验证集91%左右
5 调参实验结论
- 由于模型训练过程中的随机性因素,如随机初始化的权重参数,mini-batch,随机梯度下降优化算法等,造成模型在数据集上的结果有一定的浮动,如准确率(accuracy)能达到1.5%的浮动,而AUC则有3.4%的浮动;
- 词向量是使用word2vec还是GloVe,对实验结果有一定的影响,具体哪个更好依赖于任务本身;
- Filter的大小对模型性能有较大的影响,并且Filter的参数应该是可以更新的;
- Feature Map的数量也有一定影响,但是需要兼顾模型的训练效率;
- 1-max pooling的方式已经足够好了,相比于其他的pooling方式而言;
- 正则化的作用微乎其微。
6 建议
- 使用non-static版本的word2vec或者GloVe要比单纯的one-hot representation取得的效果好得多;
- 为了找到最优的过滤器(Filter)大小,可以使用线性搜索的方法。通常过滤器的大小范围在1-10之间,当然对- 于长句,使用更大的过滤器也是有必要的;
- Feature Map的数量在100-600之间;
- 可以尽量多尝试激活函数,实验发现ReLU和tanh两种激活函数表现较佳;
- 使用简单的1-max pooling就已经足够了,可以没必要设置太复杂的pooling方式;
- 当发现增加Feature Map的数量使得模型的性能下降时,可以考虑增大正则的力度,如调高dropout的概率;
- 为了检验模型的性能水平,多次反复的交叉验证是必要的,这可以确保模型的高性能并不是偶然。
7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
原文地址:https://blog.csdn.net/m0_43533/article/details/135866958
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_63107.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!