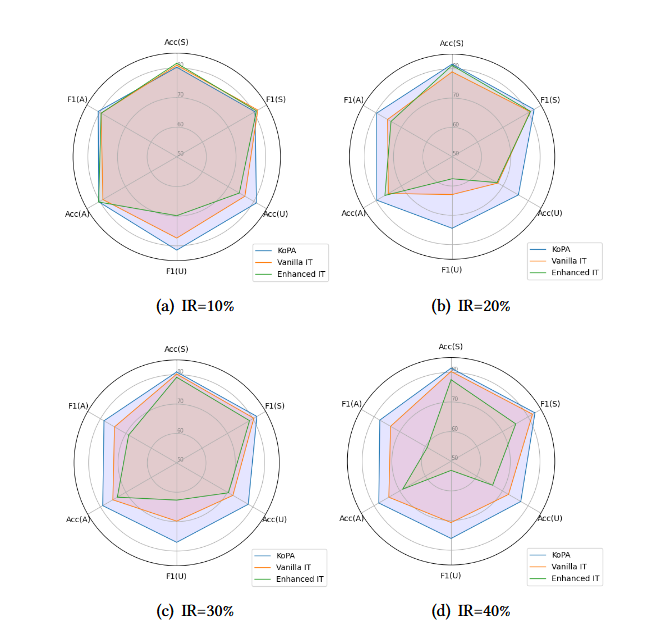
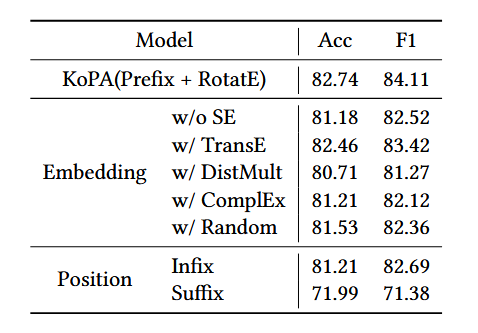
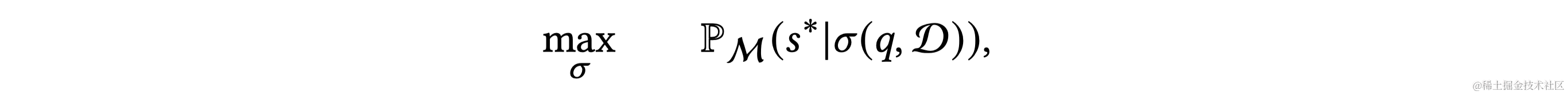原文链接:
Making Large Language Models Perform Better in Knowledge Graph Completion
摘要
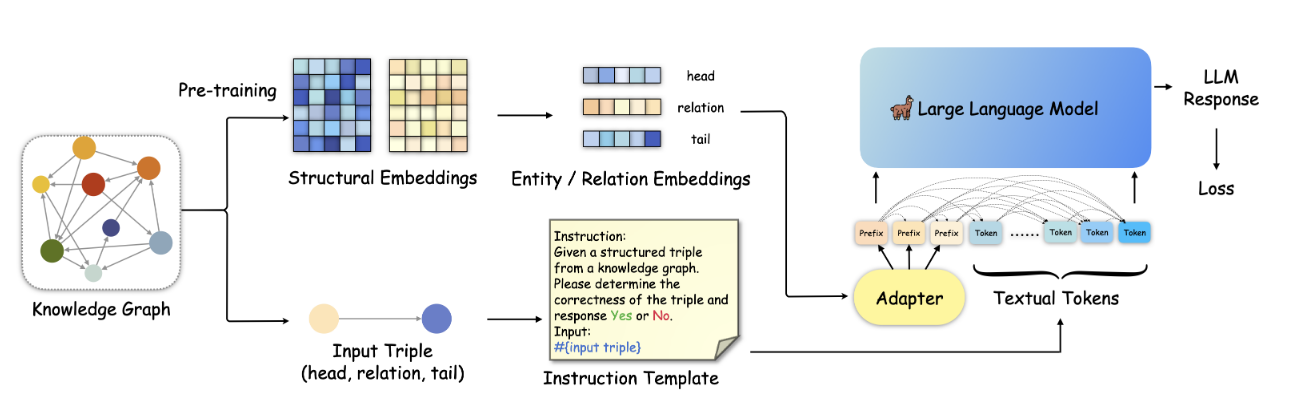
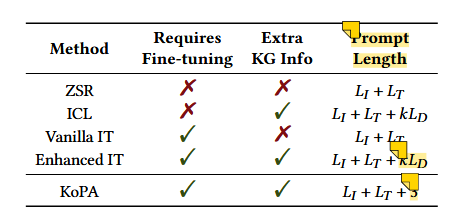
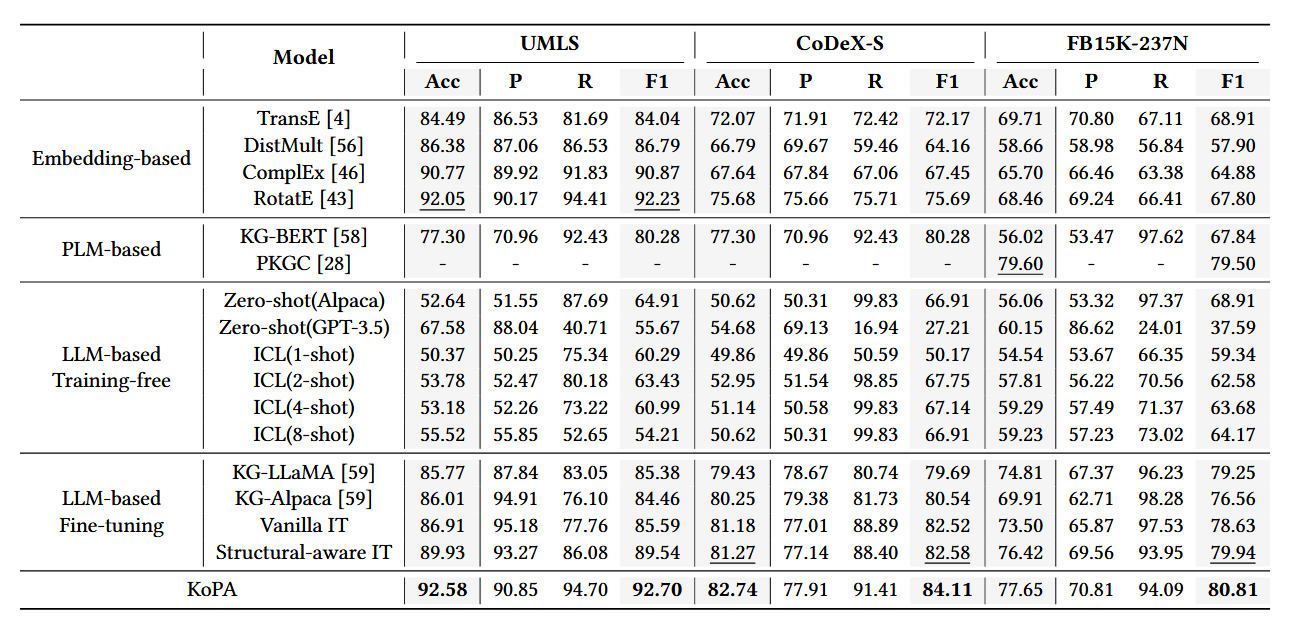
基于大语言模型(LLM)的知识图补全(KGC)旨在利用 LLM 预测知识图谱中缺失的三元组,并丰富知识图谱,使其成为更好的网络基础设施,这可以使许多基于网络的自动化服务受益。然而,基于LLM的KGC研究有限,缺乏对LLM推理能力的有效利用,忽略了KG中的重要结构信息,阻碍了LLM获取准确的事实知识。在本文中,论文中讨论如何将有用的知识图谱结构信息融入到LLM中,旨在实现LLM中的结构感知推理。论文中首先将现有的LLM范式转移到结构感知设置,并进一步提出知识前缀适配器(KoPA)来实现这一既定目标。 KoPA 采用结构embedding预训练来捕获知识图谱中实体和关系的结构信息。然后,KoPA 通知 LLM 知识前缀适配器,该适配器将结构embedding投影到文本空间中,并获取虚拟知识标记作为输入提示的前缀。论文中对这些基于结构感知的 LLM 的 KGC 方法进行了全面的实验,并进行了深入的分析,比较了结构信息的引入如何更好地提高 LLM 的知识推理能力。
KEYWORDS
Knowledge Graphs, Knowledge Graph Completion, Triple Classification, Large Language Models, Instruction Tuning
1.问题的提出
引出当前研究的不足与问题
KGC方法
知识图补全(KGC)其目的是挖掘给定不完整知识图谱中缺失的三元组。KGC包含几个子任务,例如三元分类、实体预测和关系预测
主流的KGC方法: 基于embedding的方法和基于PLM的方法
– 基于embedding:充分利用知识图谱的结构信息,忽略了 KG 中的文本信息
– 基于PLM:利用了PLM的强大功能,但将训练过程变成基于文本的学习,很难捕获知识图谱中的复杂结构信息。
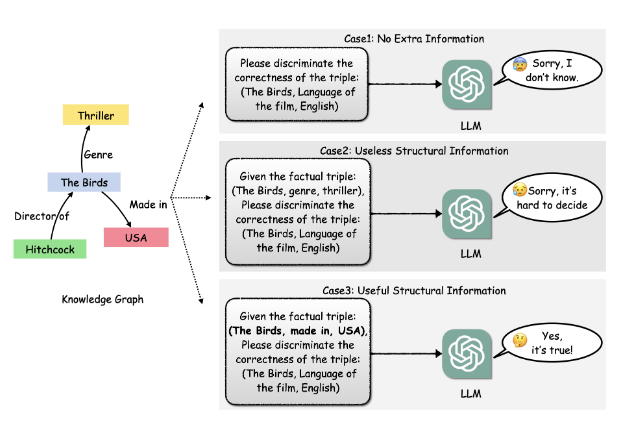
LLM幻觉现象
LLM对细粒度的事实知识记忆力不足,会导致幻觉现象。因此,将KG信息融入到提示中,提供更多的辅助信息,引导LLM进行结构感知推理,是实现优秀的基于LLM的KGC的关键。