1. SQL的运行顺序
from --> where -- > group by -- > having -- > select -- > order by -- > limit
2. SQL常用知识
- select
筛选的字段名称
- from
后面跟数据库名称
- where
条件筛选
- distinct – 去重
select distinct name, age
select count(distinct name)
- order by – 排序
order by age desc # 年龄倒序
order by age asc # 年龄升序
- limit
offset 跳过多少页
limit 限制多少条数据
用于SQL查询最后使用
select name from table order by age asc limit 1
- group by – 分组(去重)
group by 用于数据分组展示
select name from table group by name
- having
一般和 group by 连用
group by having
用于 数据 筛选
group by name having name = 'zs'
- 常见函数
求和函数
sum()
平均值函数
avg()
中位数函数
median()
标准差函数
stddev()
求最大值函数
max()
求最小值函数
min()
计数函数
count()
类型转换函数
cast(字段名 AS 格式类型 )
日期格式转换函数
date_format(date,'%Y %m %d %H:%i %s')
返回统计的年份
select YEAR('2020-10-10') from table
返回统计的月份
MONTH()
返回统计的天
DAY()
返回小时值
HOUR()
返回分钟值
MINUTE()
返回秒数
SECOND()
全年第几周
WEEK()
取年-月-日函数
DATE()
计算时间差函数,interval代表指定的单位,常用可选:
timestampdiff(interval,start_time,end_time)
YEAR 年数
MONTH 月数
DAY 天数(返回秒数差除以3600*24的整数部分)
HOUR 小时(返回秒数差除以3600的整数部分)
MINUTE 分钟(返回秒数差除以60的整数部分)
SECOND 秒
两个日期相减,返回天数,大的值在前
datediff(end_time,start_time)
两个日期相减,返回 time 差值(时分秒格式),大的值在前
timediff(end_time,start_time)
百分比格式表示
CONCAT(字段名,'%')
替换函数
replace(字符串,原字符,新字符)
字符串的截取函数
substring(字符串,起始位置,截取字符数)
四舍五入函数
Round() --将数值四舍五入为指定数值,用法:Round(数值,返回的小数位)
- 窗口函数
row_number() # 1 2 3 4
select
s_id,avg(score) as '平均成绩',
row_number() over(order by avg(score) DESC) as '排名'
from
sc
rank() # 1 2 2 4
select
*,
rank() over(PARTITION by c_id order by score desc) as '排名'
from
sc
dense_rank() # 1 2 2 3
Lag() 求当前行的前 N 行 #用来计算 与前一天相比 新增的销售额
select (nowTime - (lag(nowTime, 1) over(PARTITION by c_id order by score desc)) )
Lead() 求当前行之后第 N 行对应的字段的值
select *,Lead(score,3) over(PARTITION by c_id order by score desc) as '排名' from sc
- 表连接 – 内连接 左连接 右连接 外连接
left
right
inner
outer
- 子查询
select
emp_no
from
employees where emp_no not in (select emp_no from dept_manager)
- like
1.% (任意字符) 的用法 查询名字以 网结尾的
%占位符表示0个或多个字符,可放在查询条件的任意位置
select
name
from
table
where
name like '%网'
2._的用法 查询四个字符,并且是以 abc结尾
_占位符表示一个字符,可放在查询条件的任意位置用法和%类似
select
str
from
table
where
name like '_abc'
3.[ ] 指定范围 ([a-f]) 或集合 ([abcdef]) 中的任何单个字符
like’[CK]ars[eo]n’ 将搜索下列字符串:Carsen、Karsen、Carson 和 Karson(如 Carson)。
like’[M-Z]inger’ 将搜索以字符串 inger 结尾、以从 M 到 Z 的任何单个字母开头的所有名称(如 Ringer)。
4.[^] 不属于指定范围 ([a-f]) 或集合 ([abcdef]) 的任何单个字符
like’M[^c]%’ 将搜索以字母 M 开头,并且第二个字母不是 c 的所有名称(如MacFeather)。
5.* 它同于DOS命令中的通配符,代表多个字符
c*c代表cc,cBc,cbc,cabdfec等多个字符。
6.?同于DOS命令中的?通配符,代表单个字符
b?b代表brb,bFb等
- between and
SELECT *
FROM
table_name
WHERE
date_column BETWEEN '1998-01-01' AND '2020-01-01';
*not – in
select
emp_no
from
employees where emp_no not in (select emp_no from dept_manager)
- or
select age from table where age > 10 or age < 5
- 逻辑判断
select if(score>60, '及格', '不及格') as 标准 from table
- 聚合函数 sum max min count avg stdev median
sum() 求和
max() 最大值
min() 最小值
count() 计数
avg() 平均值
median() 中位数
stdev() 标准差
- case when
select
name,
case when home = 'beijing' then 'shoudu'
case when home = 'beijing' then 'shoudu'
end as shoudu_yes
from
table
- 分组查询严格模式
SQL的分组查询可以通过使用GROUP BY子句来进行。
在MySQL中,默认情况下,如果SELECT语句包含了非聚合列(没有被聚合函数处理)
而不是所有的列都在GROUP BY子句中指定,则会引发错误。这种模式称为"严格模式"。
- 临时表
-- student 学生表
-- s_course 选课关系表
-- course 课程表
查询同时选修了 Java基础和高等数学这两门课程,并且Java基础成绩高于高等数学的学生信息
--临时表
with tl as
(
select
s.sno,
s.sex,
s.sname,
sc.mark
from
student s,
s course sc,
course c
where
s.sno = sc.sno
and sc.cno = c.cno
and c.cname ='java基础'
),
t2 as
(
select
s.sno, s.sname, sc.mark
from
student s,
s course sc,
course c
where
s.sno = sc.sno
and sc.cno = c.cnoand c.cname = '高等数学'
)
select
t1.sno,
t1.sname,
t1.sex
from
t1, t2
where t1.sno = t2.sno
and t1.mark > t2 .mark;
- 自连接
select
b.*
from
age_table as a,
age_table as b
where
a.age = 12 and b.name = 'zs'
-------------------------------------------
select
a.ename,
(select ename from emp as b where b.empno = a.mgr ) as manager
from
emp as a
- 空值影响处理
SELECT * FROM table_name WHERE column_name IS NULL;
SELECT * FROM table_name WHERE column_name IS NOT NULL;
- exists
exists 子查询
基本语法
where exists(查询语句) // 根据查询的结果进行判断,如果结果存在就返回 1 ,否则就返回 0
--- 求出,有学生所在的班级
select
*
from
my_class as c
where
exists
(select stu_id from my_student as s where s.class_id = c.class_id)
-
文本 | 时间函数
文本函数
-
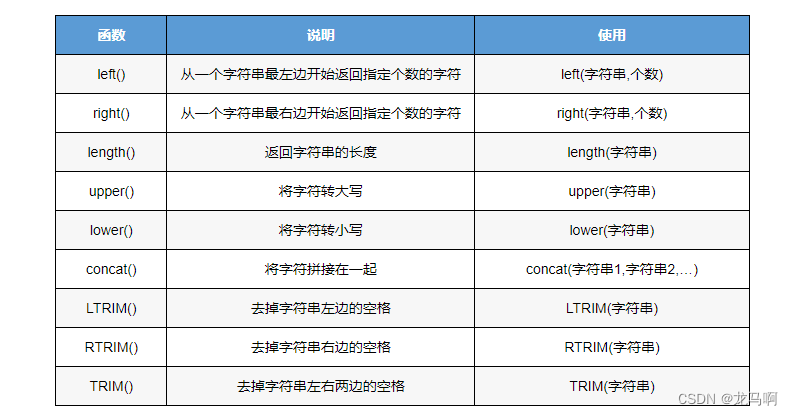
substring()函数
字符串的截取:substring(字符串,起始位置,截取字符数) -
concat()字符串拼接
语法:concat(字符串1,字符串2,…) -
replace() 替换函数
语法:replace(字符串,原字符,新字符)
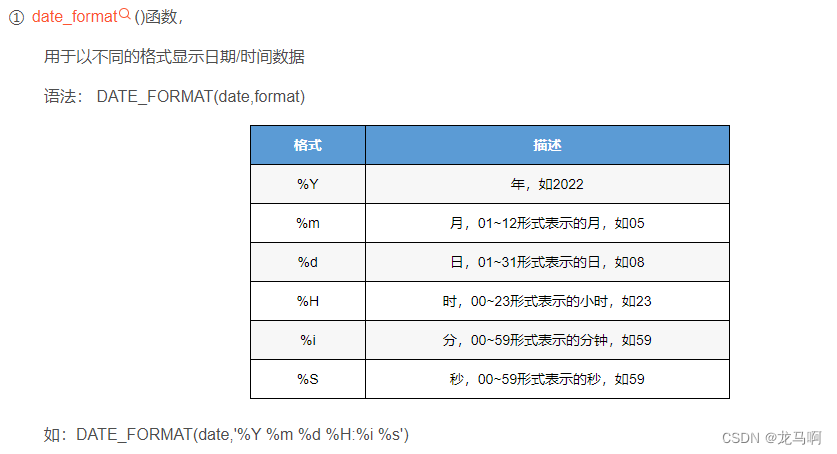
时间函数



3. SQL牛客面试题
1.SQL195 查找最晚入职员工的所有信息
找出最晚入职,就是找出最近的入职员工
order by hire_date desc字段倒序
limit 1
select
*
from
employees order by hire_date desc limit 1
select
*
from
employees where hire_date = (select max( hire_date ) from employees )
- SQL196 查找入职员工时间排名倒数第三的员工所有信息
使用了 子表查询
窗口函数 dense_rank() over(order by hire_date desc) # 1 2 2 3
select
emp_no, birth_date,
first_name,
last_name,gender,
hire_date
from
(select *, dense_rank() over(order by hire_date desc) as n from employees where n = 3 )
- SQL197 查找当前薪水详情以及部门编号dept_no
联表查询内连接
排序
select
s.emp_no emp_no,
s.salary salary ,
s.from_date from_date ,
s.to_date to_date,
d.dept_no dept_no
from salaries s
join dept_manager d on s.emp_no = d.emp_no
order by s.emp_no asc;
- SQL198 查找所有已经分配部门的员工的last_name和first_name以及dept_no
表查询的左连接
select
e.last_name last_name ,
e.first_name first_name ,
d.dept_no dept_no
from
dept_emp d left join employees e on d.emp_no = e.emp_no
- SQL199 查找所有员工的last_name和first_name以及对应部门编号dept_no
左表查询
select
e.last_name last_name,
e.first_name first_name,
d.dept_no dept_no
from
employees e
left join dept_emp d on d.emp_no = e.emp_no
- SQL201 查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t
group by 字段 having 字段
count(字段)
select
emp_no , count(emp_no) t
from
salaries group by emp_no having count(emp_no) > 15;
- SQL202 找出所有员工当前薪水salary情况
distinct salary 去重
order by salary desc 排序
select
distinct salary
from
salaries order by salary desc
- SQL204 获取所有非manager的员工emp_no
not in()
子查询 select emp_no from dept_manager
select
emp_no
from
employees where emp_no not in (select emp_no from dept_manager)
- SQL205 获取所有员工当前的manager
内连接查询
select
d.emp_no emp_no,
de.emp_no manager
from
dept_emp d inner join dept_manager de on d.dept_no = de.dept_no
where
d.emp_no != de.emp_no
- SQL206 获取每个部门中当前员工薪水最高的相关信息
子表查询
内连接
窗口函数 rank( ) # 1 2 2 4
partition by 分组
order by sa.salary desc 排序
select
a.dept_no dept_no,
a.emp_no emp_no,
a.salary maxSalary
from
(
select
de.dept_no,
de.emp_no,
sa.salary,
rank() over (
partition by
de.dept_no
order by
sa.salary desc
) rank_n
from
dept_emp de
join salaries sa on de.emp_no = sa.emp_no
) a
where
a.rank_n = 1
- 查找employees表emp_no与last_name的员工信息
where
and
order by
select
emp_no,
birth_date,
first_name,
last_name,
gender,
hire_date
from
employees
where
emp_no %2 != 0 and last_name != 'Mary'
order by hire_date desc
- SQL210 统计出当前各个title类型对应的员工当前薪水对应的平均工资
avg() 函数
内连接
分组
排序
select
t.title ,
avg(s.salary) average
from
titles t join salaries s on t.emp_no = s.emp_no
group by t.title order by average asc
- xxxxx
4. 网上收集面试题
- having和where的区别
having是在分组后对数据进行过滤where是在分组前对数据进行过滤
having后面可以使用聚合函数where后面不可以使用聚合
HAVING SUM(population)>1000000
- SQL语句中的执行顺序是怎样的
form -> where -> group by -> having -> select -> order by -> limit
- SQL中如何实现去重操作
第一种
distinct
select distinct name,id form table
select count(distinct name) form table
第二种
group by
select 重复的字段名 from 表名 group by 重复的字段名
- SQL中 count(*), count(字段), count(distinct 字段)的区别是什么
count(*)表示的是直接查询符合条件的数据库表的行数
COUNT(字段)表示的是查询符合条件的列的值不为NULL的行数
count(distinct 字段) 表示的是查询去重之后符合条件的列的值不为NULL的行数
- SQL如何求’yyyy-MM-dd’ 的日期差
select datediff(day, ‘2008-12-29’, ‘2018-12-30’) as date
select datediff(day,convert(date,‘20220824’,112),convert(date,‘20230824’,112)) from your_table;
- SQL中 if、case when的区别
case when
select name, case when home = ‘beijing’ then ‘shoudu’ end as shoudu_yes from table
表达式 | 多条件判断 | 适合复杂逻辑
if
SELECT id, name, IF(score >= 60, ‘及格’, ‘不及格’) AS result FROM students;
单条件判断 | 函数形式 | 简单逻辑
- SQL中什么是笛卡尔积,笛卡尔积一般出现在什么情况下
笛卡尔积
是两张表的行数的乘积
一般出现在联表查询的时候
内连接可以解决这个问题
- SQL中除了rank以外还有哪些窗口函数
窗口函数
除了rank,sql还提供了许多其他窗口函数,用于在指定的范围内进行计算、排序和分析。以下是一些常见的窗口函数。
①dense_mark:分配连续的、不重复的排名给结果集中的行,相同的值会获得相同的排名,而且不会跳过排名。
②row_number:为结果集中的每一行分配唯一的、连续的整数排名,不考虑相同值的行。
③ntile(n):将结果集分成n个大小相等的部分,并为每个部分的行分配一个整数值表示部分号(1到n)。
④lead(column , offset):返回当前行之后的某一行中的列值。
⑤lag(column,offset):返回当前行之前的某一行中的列值。
⑥first_value:获取分组集合中第一行的某个列值。
⑦last_value:获取分组集合中最后一行的某个列值。
⑧sum/avg/min/max(column) over(partition by … order by …):计算指定窗口中某列的总和/平均值/最小/最大值。
- 简述一下max()聚合函数和窗口函数max(A)over(partiton by B)的区别
①max聚合函数:用于在查询中对某个列的值进行聚合计算,得出整个结果集的最大值。
②max窗口函数:在查询结果集的某个窗口(或分区)上进行计算的函数。窗口函数可以同时获得每个分区的最大值。
- sql如何将类型为float的字段保留两位小数
mysql 使用format函数
select format(float_column,2) as formatted_float from your_table;sql server
select round(float_column,2) as formatted_float from your_table;
- sql中,left join , right join , inner join 有什么差别
①inner join返回两个表中的匹配行,如果某行一个表中找不到匹配的行,那么这个行不会在结果中显示。
②left join返回左表中的所有行以及右表中与坐标匹配的行。如果在右表中找不到匹配的行,那么对应的右表列将会显示为NULL。
③right join返回右表的所有行,以及左表中与右表匹配的行。如果在左表中找不到匹配的行,那么对应的左表列将会显示为NULL。
join操作的效率通常比单纯使用子查询的效率要高,但应尽量避免多重嵌套join或join多张表,以免影响查询性能。
- sql中如何将int类型的字段转换为string类型
mysql
select cast(int_column as char) as string_column from your_table;
- 窗口函数和where的执行顺序孰先孰后
在sql中,where子句通常会在窗口函数之前执行。
首先,数据库会根据where子句的条件对表进行筛选,过滤出符合条件的行。然后,在已经筛选出的结果集上,窗口函数开始计算。
这个执行顺序确保了窗口函数在筛选和过滤数据后进行计算,以及在计算窗口函数不会考虑不满足where子句条件的行。
- sql中,如何求字段整体的标准差和均值
均值使用聚合函数avg计算:
select avg(column) as mean from your_table;
标准差用聚合函数stdev计算:
select stdev(column) as std from your_table;
- SQL中如何将’yyyy-MM-dd’的日期格式转换为’yyyyMMdd’形式
select convert(varchar(8),date_column,112) from your_table;
select cast(date_column as char(8)) from your_table;
原文地址:https://blog.csdn.net/qq_43853213/article/details/135817329
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_63349.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!