目录
不同队列之间的区别
Classic经典队列
这是RabbitMQ最为经典的队列类型。在单机环境中,拥有比较高的消息可靠性。

经典队列可以选择是否持久化(Durability)以及是否自动删除(Auto delete)两个属性。其中,Durability有两个选项,Durable和Transient。 Durable表示队列会将消息保存到硬盘,这样消息的安全性更高。但是同时,由于需要有更多的IO操作,所以生产和消费消息的性能,相比Transient会比较低。 Auto delete属性如果选择为是,那队列将在至少一个消费者已经连接,然后所有的消费者都断开连接后删除自己。Arguments部分,还有非常多的参数,可以点击后面的问号逐步了解。
在RabbitMQ中,经典队列是一种非常传统的队列结构。消息以FIFO先进先出的方式存入队列。消息被Consumer从队列中取出后就会从队列中删除。如果消息需要重新投递,就需要再次入队。这种队列都依靠各个Broker自己进行管理,在分布式场景下,管理效率是不太高的。并且这种经典队列不适合积累太多的消息。如果队列中积累的消息太多了,会严重影响客户端生产消息以及消费消息的性能。因此,经典队列主要用在数据量比较小,并且生产消息和消费消息的速度比较稳定的业务场景。比如内部系统之间的服务调用。
Quorum仲裁队列
仲裁队列,是RabbitMQ从3.8.0版本,引入的一个新的队列类型,整个3.8.X版本,也都是在围绕仲裁队列进行完善和优化。仲裁队列相比Classic经典队列,在分布式环境下对消息的可靠性保障更高。官方文档中表示,未来会使用Quorum仲裁队列代替传统Classic队列。

Quorum是基于Raft一致性协议实现的一种新型的分布式消息队列,他实现了持久化,多备份的FIFO队列,主要就是针对RabbitMQ的镜像模式设计的。简单理解就是quorum队列中的消息需要有集群中多半节点同意确认后,才会写入到队列中。这种队列类似于RocketMQ当中的DLedger集群。这种方式可以保证消息在集群内部不会丢失。同时,Quorum是以牺牲很多高级队列特性为代价,来进一步保证消息在分布式环境下的高可靠。从整体功能上来说,Quorum队列是在Classic经典队列的基础上做减法,因此对于RabbitMQ的长期使用者而言,其实是会影响使用体验的。
与普通队列的区别:

Quorum队列大部分功能都是在Classic队列基础上做减法,比如Non-durable queues表示是非持久化的内存队列。Exclusivity表示独占队列,即表示队列只能由声明该队列的Connection连接来进行使用,包括队列创建、删除、收发消息等,并且独占队列会在声明该队列的Connection断开后自动删除。
特例Poison Message handling(处理有毒的消息)。所谓毒消息是指消息一直不能被消费者正常消费(可能是由于消费者失败或者消费逻辑有问题等),就会导致消息不断的重新入队,这样这些消息就成为了毒消息。这些读消息应该有保障机制进行标记并及时删除。Quorum队列会持续跟踪消息的失败投递尝试次数,并记录在”x-delivery-count”这样一个头部参数中。然后,就可以通过设置 Delivery limit参数来定制一个毒消息的删除策略。当消息的重复投递次数超过了Delivery limit参数阈值时,RabbitMQ就会删除这些毒消息。当然,如果配置了死信队列的话,就会进入对应的死信队列。
Quorum队列更适合于长期存在的队列,并且在对容错、数据安全方面有更严格要求的场景。相对于追求低延迟、非持久化等高级队列,Quorum队列提供了更可靠的数据复制机制,以满足对数据一致性和高可用性的要求。
不适合使用的场景:
临时使用的队列:
比如transient临时队列,exclusive独占队列,或者经常会修改和删除的队列。
对消息低延迟要求高:
一致性算法会影响消息的延迟。
对数据安全性要求不高:
Quorum队列需要消费者手动通知或者生产者手动确认。
队列消息积压严重 :
如果队列中的消息很大,或者积压的消息很多,就不要使用Quorum队列。Quorum队列当前会将所有消息始终保存在内存中,直到达到内存使用极限。
Stream流式队列
Stream队列是RabbitMQ自3.9.0版本开始引入的一种新的数据队列类型。这种队列类型的消息是持久化到磁盘并且具备分布式备份的,更适合于消费者多,读消息非常频繁的场景。
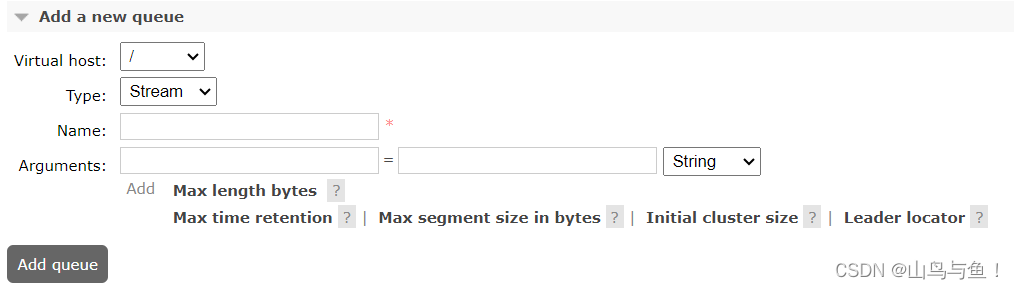
Stream队列的核心是以append-only只添加的日志来记录消息,整体来说,就是消息将以append-only的方式持久化到日志文件中,然后通过调整每个消费者的消费进度offset,来实现消息的多次分发。下方有几个属性也都是来定义日志文件的大小以及保存时间。如果你熟悉Kafka或者RocketMQ,会对这种日志记录消息的方式非常熟悉。这种队列提供了RabbitMQ已有的其他队列类型不太好实现的四个特点:
large fan-outs 大规模分发
当想要向多个订阅者发送相同的消息时,以往的队列类型必须为每个消费者绑定一个专用的队列。如果消费者的数量很大,这就会导致性能低下。而Stream队列允许任意数量的消费者使用同一个队列的消息,从而消除绑定多个队列的需求。
Replay/Time-travelling 消息回溯
RabbitMQ已有的这些队列类型,在消费者处理完消息后,消息都会从队列中删除,因此,无法重新读取已经消费过的消息。而Stream队列允许用户在日志的任何一个连接点开始重新读取数据。
Throughput Performance 高吞吐性能
Strem队列的设计以性能为主要目标,对消息传递吞吐量的提升非常明显。
Large logs 大日志
RabbitMQ一直以来有一个让人诟病的地方,就是当队列中积累的消息过多时,性能下降会非常明显。但是Stream队列的设计目标就是以最小的内存开销高效地存储大量的数据。使用Stream队列可以比较轻松的在队列中积累百万级别的消息。
整体上来说,RabbitMQ的Stream队列,其实有很多地方借鉴了其他MQ产品的优点,在保证消息可靠性的基础上,着力提高队列的消息吞吐量以及消息转发性能。因此,Stream也是在视图解决一个RabbitMQ一直以来,让人诟病的缺点,就是当队列中积累的消息过多时,性能下降会非常明显的问题。RabbitMQ以往更专注于企业级的内部使用,但是从这些队列功能可以看到,Rabbitmq也在向更复杂的互联网环境靠拢,未来对于RabbitMQ的了解,也需要随着版本推进,不断更新。
如何使用不同类型的队列
这几种不同类型的队列,虽然实现方式各有不同,但是本质上都是一种存储消息的数据结构。
Quorum队列
Quorum队列与Classic队列的使用方式是差不多的。最主要的差别就是在声明队列时有点不同。如果要声明一个Quorum队列,则只需要在后面的arguments中传入一个参数,x-queue-type,参数值设定为quorum。
Map<String,Object> params = new HashMap<>();
params.put("x-queue-type","quorum");
//声明Quorum队列的方式就是添加一个x-queue-type参数,指定为quorum。默认是classic
channel.queueDeclare(QUEUE_NAME, true, false, false, params);Quorum队列的消息是必须持久化的,所以durable参数必须设定为true,如果声明为false,就会报错。同样,exclusive参数必须设置为false。这些声明,在Producer和Consumer中是要保持一致的。
Stream队列
Stream队列相比于Classic队列,在使用上就要稍微复杂一点。如果要声明一个Stream队列,则 x-queue-type参数要设置为 stream 。
Map<String,Object> params = new HashMap<>();
params.put("x-queue-type","stream");
params.put("x-max-length-bytes", 20_000_000_000L); // maximum stream size: 20 GB
params.put("x-stream-max-segment-size-bytes", 100_000_000); // size of segment files: 100 MB
channel.queueDeclare(QUEUE_NAME, true, false, false, params);与Quorum队列类似, Stream队列的durable参数必须声明为true,exclusive参数必须声明为false。这其中,x-max-length-bytes 表示日志文件的最大字节数。x-stream-max-segment-size-bytes 每一个日志文件的最大大小。这两个是可选参数,通常为了防止stream日志无限制累计,都会配合stream队列一起声明。
当要消费Stream队列时,要重点注意他的三个必要的步骤:
1. channel必须设置basicQos属性。 与Spring框架集成使用时,channel对象可以在@RabbitListener声明的消费者方法中直接引用,Spring框架会进行注入。
2. 正确声明Stream队列。 在Queue对象中传入声明Stream队列所需要的参数。
3. 消费时需要指定offset。 与Spring框架集成时,可以通过注入Channel对象,使用原生API传入offset属性。
例如用原生API创建Stream类型的Consumer时,还必须添加一个参数x-stream-offset,表示从队列的哪个位置开始消费。
Map<String,Object> consumeParam = new HashMap<>();
consumeParam.put("x-stream-offset","last");
channel.basicConsume(QUEUE_NAME, false,consumeParam, myconsumer);x-stream-offset的可选值有以下几种:
first: 从日志队列中第一个可消费的消息开始消费
last: 消费消息日志中最后一个消息
next: 相当于不指定offset,消费不到消息。
Offset: 一个数字型的偏移量
Timestamp:一个代表时间的Data类型变量,表示从这个时间点开始消费。例如 一个小时前 Date timestamp = new Date(System.currentTimeMillis() – 60 * 60 * 1_000)
由于在Consumer中必须传入x-stream-offset这个参数,所以在与SpringBoot集成时,stream队列目前暂时无法正常消费。在目前版本下,使用RabbitMQ的SpringBoot框架集成,可以正常声明Stream队列,往Stream队列发送消息,但是无法直接消费Stream队列了。
SpringBoot框架集成RabbitMQ后,为了简化编程模型,就把channel,connection等这些关键对象给隐藏了,目前框架下,无法直接接入这些对象的注入过程,所以无法直接使用。
如果非要使用Stream队列,那么有两种方式,一种是使用原生API的方式,在SpringBoot框架下自行封装。另一种是使用RabbitMQ的Stream 插件。在服务端通过Strem插件打开TCP连接接口,并配合单独提供的Stream客户端使用。这种方式对应用端的影响太重了,并且并没有提供与SpringBoot框架的集成,还需要自行完善,因此Stream队列使用较少。
原文地址:https://blog.csdn.net/m0_61853556/article/details/135923366
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_63389.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!

![[MFC] MFC消息机制的补充](https://img-blog.csdnimg.cn/direct/4e6d632d6c144126a691d901337a1749.png)