本文介绍: 大型语言模型(LLMs)展示了显著的能力,但面临幻觉、过时知识和不透明、不可追溯的推理过程等挑战。检索增强生成(RAG)已经成为一个有希望的解决方案,通过整合外部数据库中的知识来提升模型的准确性和可信度,特别适用于知识密集型任务,并允许不断更新知识和整合领域特定信息。RAG通过协同作用,将LLMs固有的知识与外部数据库的庞大、动态存储库相结合。本综述论文详细审视了RAG范例的发展,包括朴素RAG、高级RAG和模块化RAG。它对RAG框架的三方面基础进行了细致的审查,其中包括检索、生成和增强技术。
大型语言模型(LLMs)已经成为我们生活和工作的一部分,它们以惊人的多功能性和智能化改变了我们与信息的互动方式。
然而,尽管它们的能力令人印象深刻,但它们并非无懈可击。这些模型可能会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。
在现实世界的应用中,数据需要不断更新以反映最新的发展,生成的内容必须是透明可追溯的,以便控制成本并保护数据隐私。因此,简单依赖于这些 “黑盒” 模型是不够的,我们需要更精细的解决方案来满足这些复杂的需求。
正是在这样的背景下,检索增强生成技术(Retrieval-Augmented Generation,RAG)应时而生,成为 AI 时代的一大趋势。
RAG 通过在语言模型生成答案之前,先从广泛的文档数据库中检索相关信息,然后利用这些信息来引导生成过程,极大地提升了内容的准确性和相关性。RAG 有效地缓解了幻觉问题,提高了知识更新的速度,并增强了内容生成的可追溯性,使得大型语言模型在实际应用中变得更加实用和可信。RAG 的出现无疑是人工智能研究领域最激动人心的进展之一。
本篇综述将带你全面了解 RAG,深入探讨其核心范式、关键技术及未来趋势,为读者和实践者提供对大型模型以及 RAG 的深入和系统的认识,同时阐述检索增强技术的最新进展和关键挑战。
摘要
RAG 是什么?
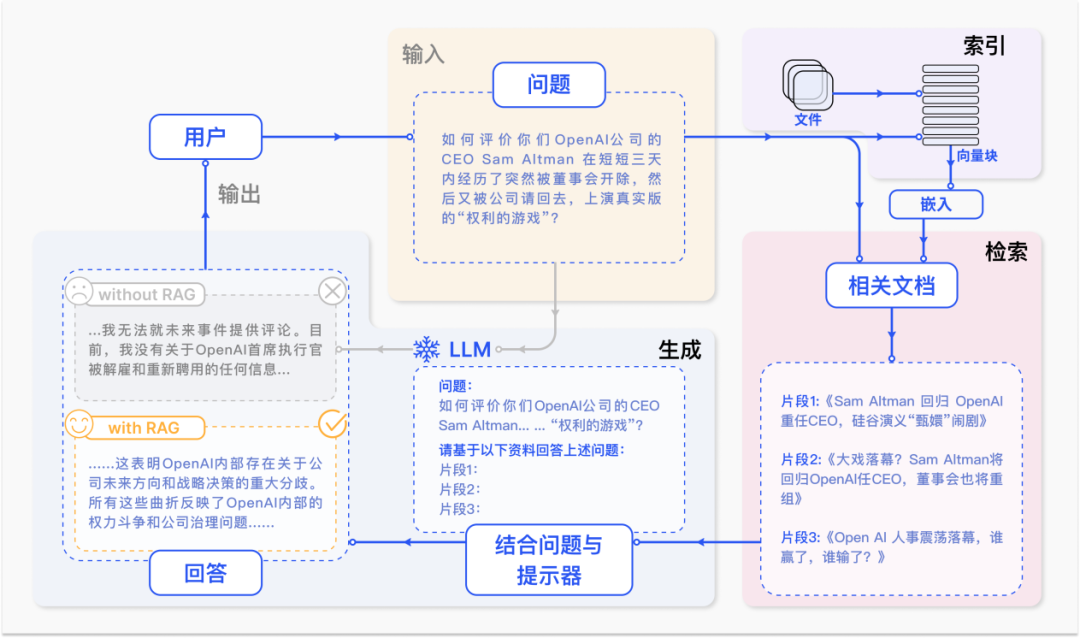
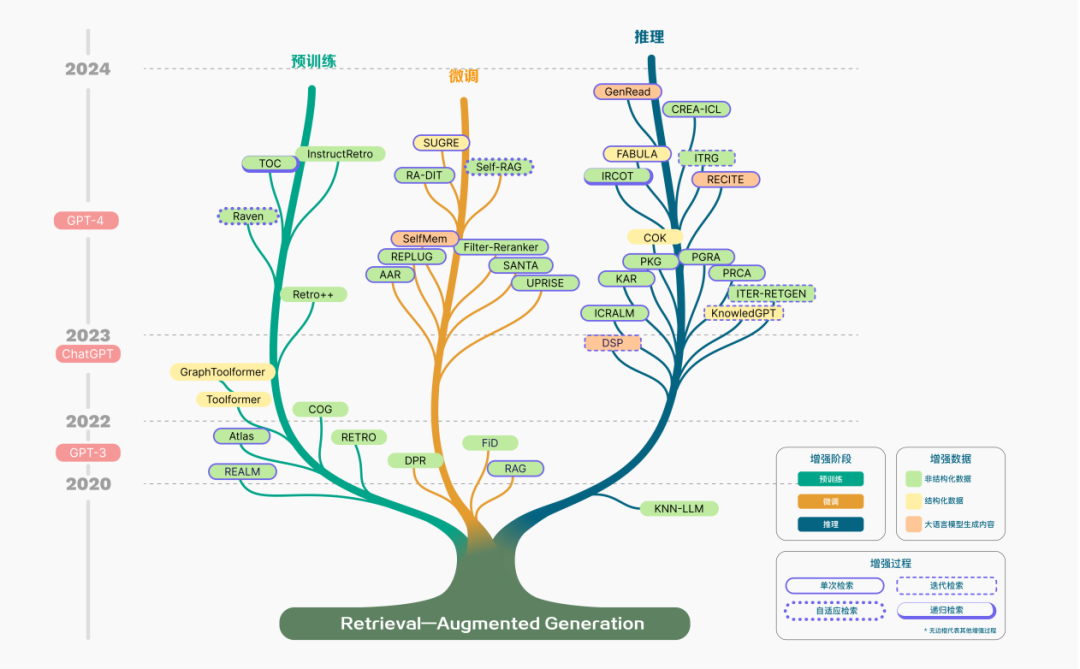
RAG 技术范式发展
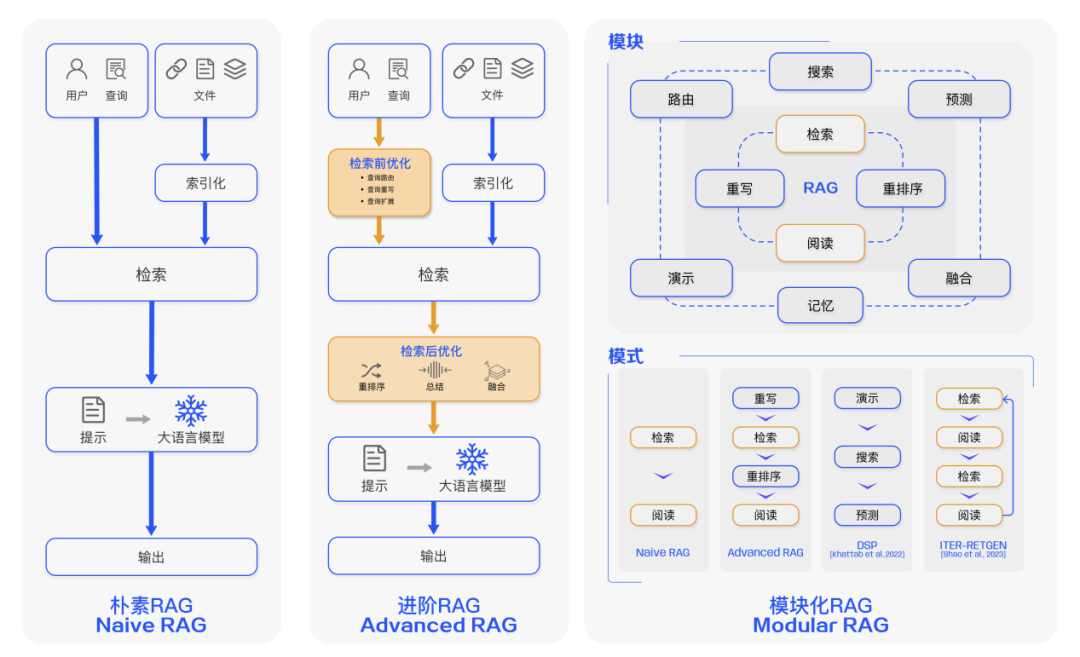
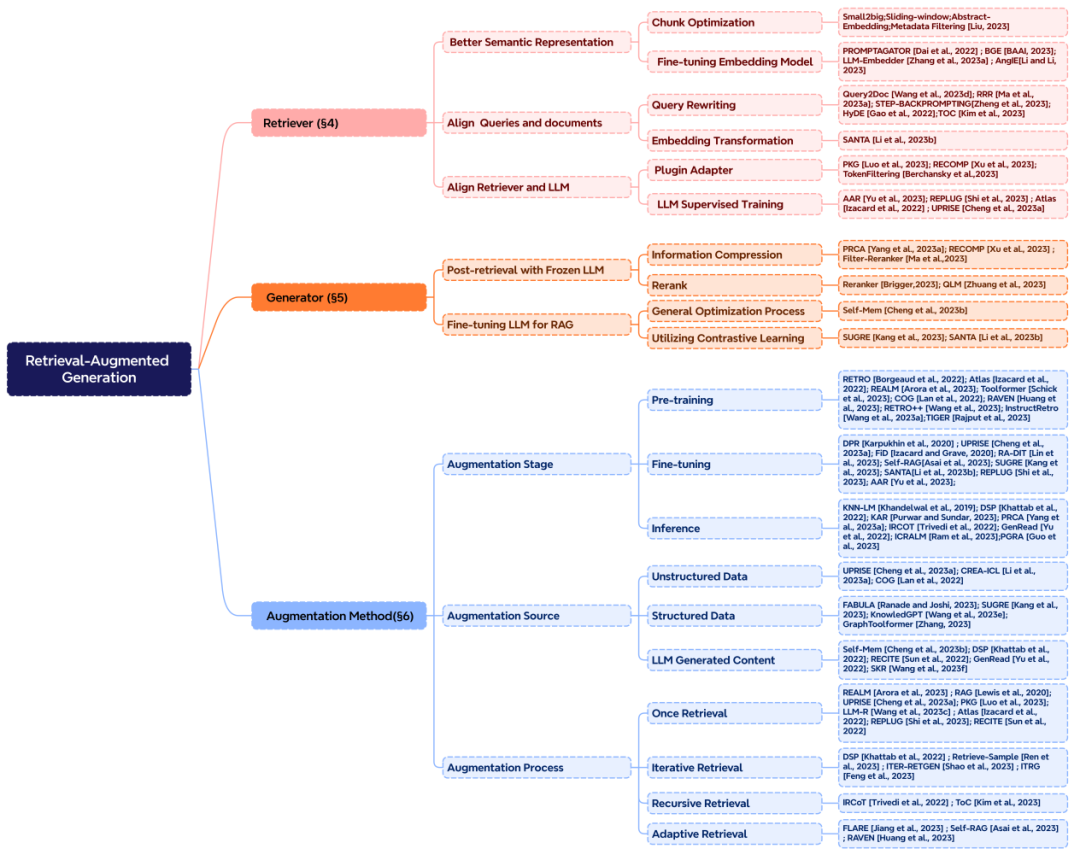
如何进行检索增强?
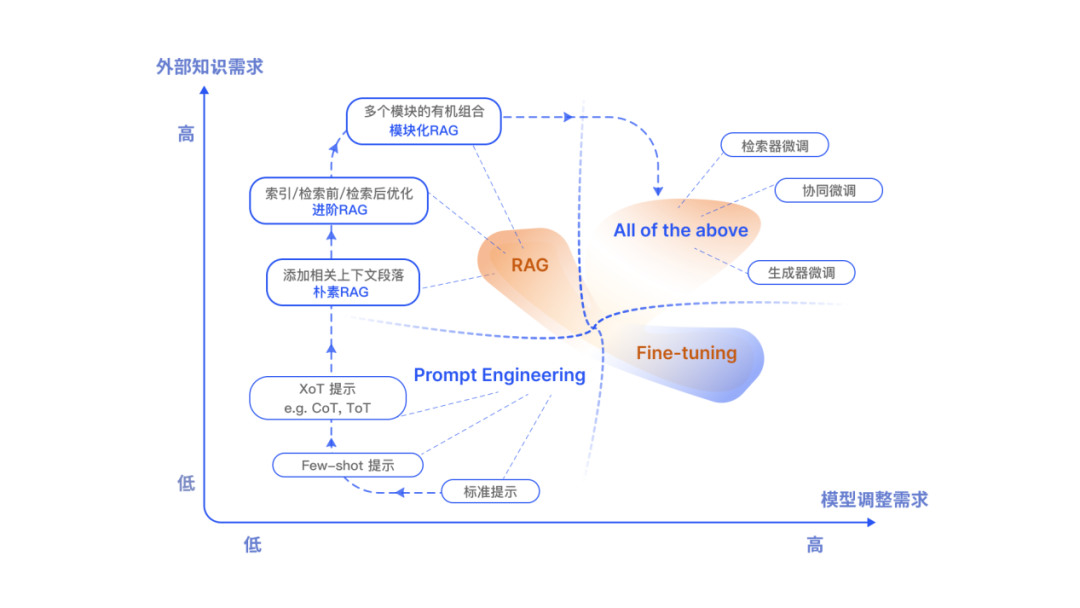
RAG 和微调应该如何选择?

如何评价 RAG?


9 结论
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。