本文介绍: 索引,在sql底层的B+树中,就是各个节点的key。通过索引,可以快速地锁定数据的位置。
案例
熟悉C++的同学知道,上述案例中,我们map底层是一颗红黑树,一个节点存储了一对kv(键值对),k是int类型,v是结构体类型。我们把大量的数据记录到这颗红黑树中。
对应到sql中,语法变成了
其中PRIMARY KEY(‘id’)相当于C++案例中的map指定KEY的步骤。存储结构也由红黑树变成了B+树。
如果在其中再添加 KEY ‘name_idx‘ (‘name’)语句,在C++中相当于再建立Map<string,int>。如果要搜寻某些数据,则通过Map<string,int>获取到int,再根据这个int获取Map<int,index_failure>里的数据,这种做法叫做“回表查询”。这里的索引也叫二级索引或者辅助索引。
细节上有所差异,业务上高度相似。红黑树是二叉平衡搜索树,B+树是多路平衡搜索树。
Sql中的索引简介
索引,在sql底层的B+树中,就是各个节点的key。通过索引,可以快速地锁定数据的位置。
主键索引
唯一索引
普通索引
组合索引
索引代价
索引的使用场景

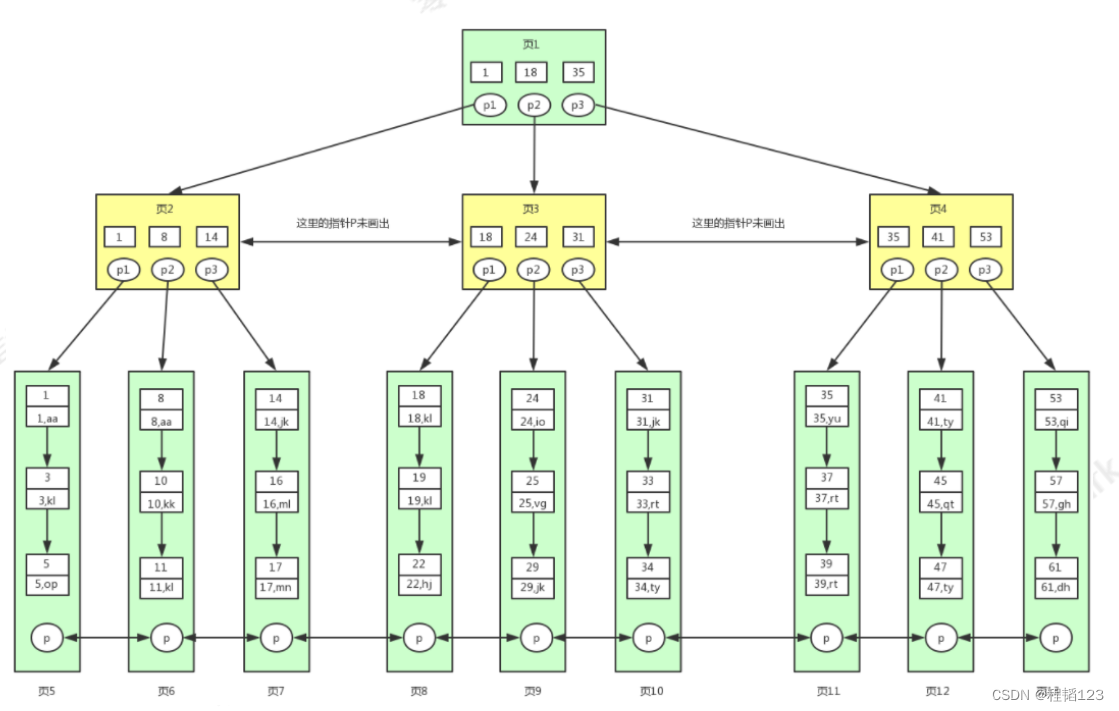
B+树和红黑树

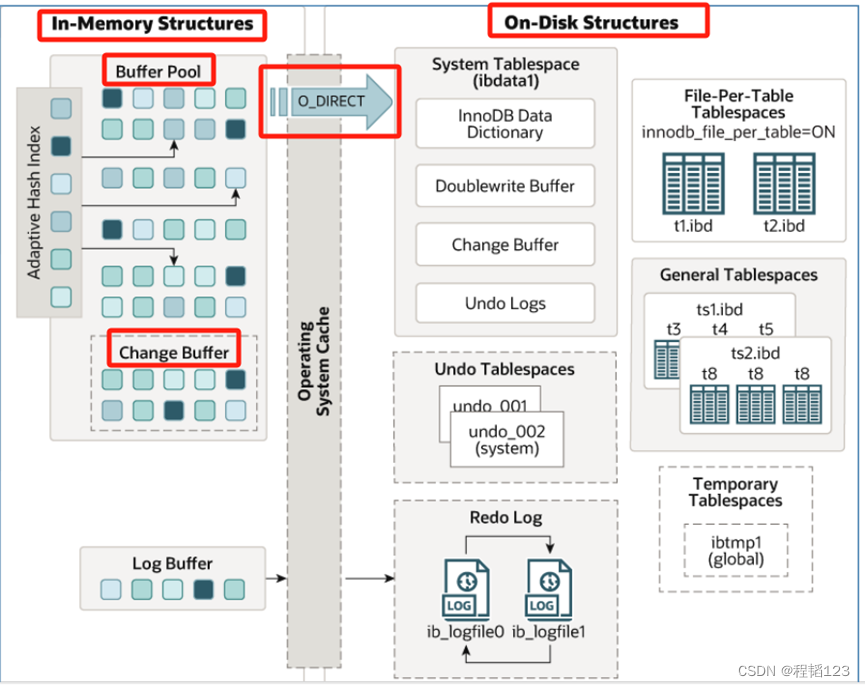
innodb 体系结构
SQL查询优化涉及原则及思路
EXPLAIN查询sql优化器方案
覆盖索引

最左匹配原则

索引下推

索引存储

索引失效
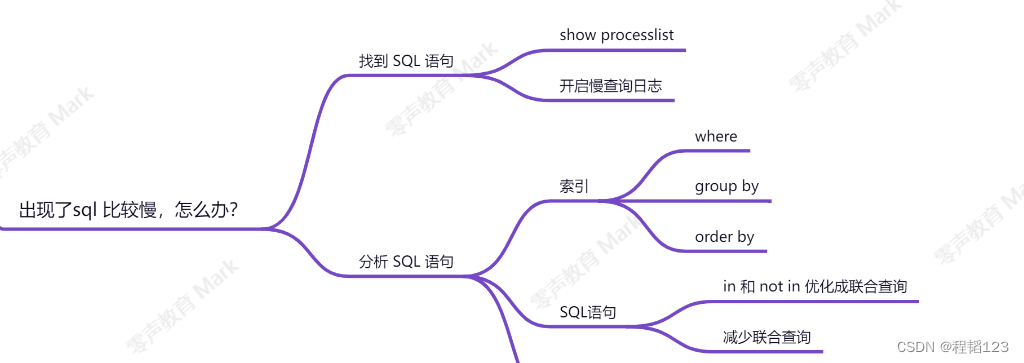
Sql查询优化思路
Sql查询优化方法
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






