epoch:是指所有样本数据在神经网络训练一次(单次epoch=(全部训练样本/batchsize)/iteration=1)或者(1个epoch=iteration数 × batchsize数)
batch-size:顾名思义就是批次大小,也就是一次训练选取的样本个数
iteration:1个iteration=1个正向通过+1个反向通过=使用batchsize个样本训练一次。
注意:每一次迭代得到的结果都会被作为下一次迭代的初始值。
在人工神经网络中,权重是相邻两层神经元之间的连接强度。权重的更新是通过反向传播算法实现的,主要步骤如下:
- 前向传播:输入数据从输入层向前传播,在各层被激活并加权,得到输出值。
- 计算损失:使用损失函数计算输出值和真实标签之间的差距,得到总体损失。
- 求导:使用链式法则计算损失相对于各层权重的偏导数。
- 权重更新:使用梯度下降法则更新各层权重,使损失最小化。
梯度下降法的概念:
梯度下降法的基本思想是通过不断迭代,找到函数的最小值点,从而得到最优的模型参数。在梯度下降法中,我们首先需要定义一个损失函数,该函数表示了模型的预测结果与实际结果之间的差距。然后,我们初始化一组模型参数,并计算损失函数关于这些参数的梯度,即损失函数在参数空间中的斜率。接着,我们沿着负梯度方向移动一定的步长,更新模型参数,直到损失函数的值收敛或达到预定的迭代次数。
下面介绍几种常见的梯度下降算法优化方法。
1. 批量梯度下降算法(Batch Gradient Descent)
批量梯度下降算法是最基本的梯度下降算法,它在每次迭代中使用所有的样本来计算梯度。虽然批量梯度下降算法的收敛速度比较慢,但是它的收敛结果比较稳定,因此在小数据集上表现良好。
2. 随机梯度下降算法(Stochastic Gradient Descent)
随机梯度下降算法是一种每次只使用一个样本来计算梯度的算法,因此它的收敛速度比批量梯度下降算法快很多。但是,由于它只使用一个样本来计算梯度,所以收敛结果可能会受到噪声的影响,因此它的收敛结果不够稳定。
3. 小批量梯度下降算法(Mini-Batch Gradient Descent)
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的一种算法。它在每次迭代中使用一部分样本来计算梯度,通常选择的样本数是几十或几百。小批量梯度下降算法的收敛速度比批量梯度下降算法快,而且比随机梯度下降算法更稳定。
4. 动量梯度下降算法(Momentum Gradient Descent)
动量梯度下降算法是一种基于动量的优化算法,它的核心思想是在更新参数的时候,将上一次的梯度方向加入到本次梯度方向中,从而加速收敛。动量梯度下降算法通常可以减少梯度震荡,从而加速收敛。
5. 自适应学习率梯度下降算法(Adaptive Learning Rate Gradient Descent)
自适应学习率梯度下降算法是一种自适应学习率的优化算法,它的核心思想是根据梯度的大小来调整学习率,从而提高算法的效率和稳定性。常见的自适应学习率梯度下降算法有Adagrad、Adadelta和Adam等。
在深度学习中,一般采用SGD训练(随机梯度下降),即每次训练在训练集中取batchsize个样本训练;
(1)经验总结:Batch_Size的正确选择是为了在内存效率和内存容量之间寻找最佳平衡
相对于正常数据集,如果Batch_Size过小,训练数据就会非常难收敛,从而导underfitting。增大Batch_Size,相对处理速度加快。但是,增大Batch_Size,所需内存容量增加(epoch的次数需要增加以达到最好的结果)这就出现了矛盾。——因为当epoch增加以后,同样也会导致耗时增加从而速度下降。因此我们需要寻找最好的Batch_Size。
(2)适当的增加Batch_Size的优点:
1.通过并行化提高内存利用率。
2.单次epoch的迭代次数减少,提高运行速度。
3.适当的增加Batch_Size,梯度下降方向准确度增加,训练震动的幅度减小。
为什么我们必须要使用梯度下降法?
参考:一文全解梯度下降法_已知两组样本梯度下降-CSDN博客
以线性回归问题为例说明这个流程:
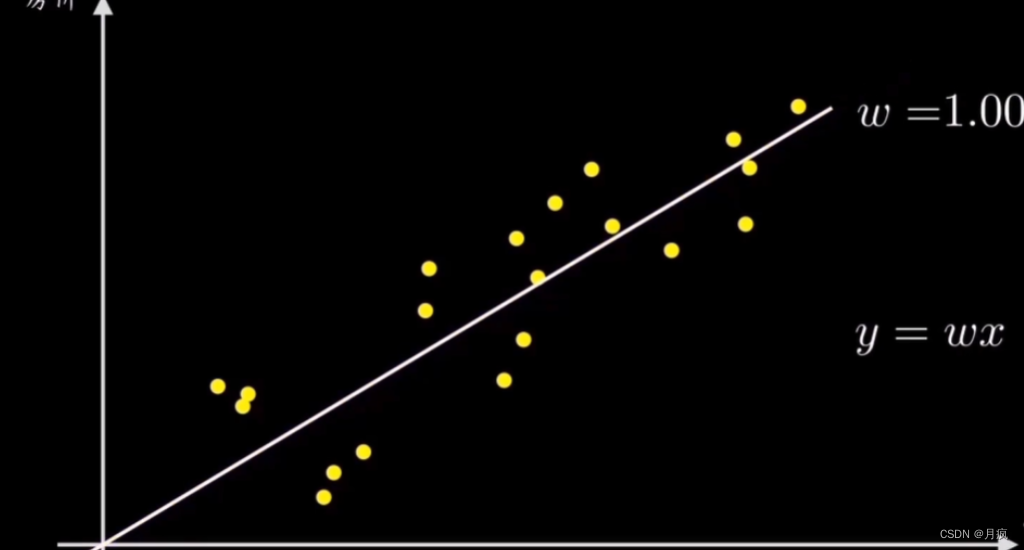
过原点的直线 y=wx 就相当于线性回归问题中用于做预测的函数,y是房价,x是面积,每个样本代表不同面积的具体房价机器的任务就是想办法计算出一条最好的直线来拟合这些样本点数据,而直线的斜率w就可以简单控制直线,所以我们的目的是要求解出最能拟合数据分布的变量w
为了方便求解出最优参数w,我们引入了与这条直线相关的损失函数
我们通过预测函数和误差公式推导出损失函数,成功的将直线拟合样本点的过程映射到了一个损失函数上,并且它是个开口向上的抛物线图像,它是以参数w为自变量、误差或者损失值作为因变量的,见下图中的右侧图
因为我们的目标是拟合出最接近这些数据分布的直线,也就是找到使得误差代价最小的参数w,对应在右图的损失函数图像上就是它的最低点,这个不断寻找最低点的过程就是梯度下降要干的活。
我们先随机选取一个参数起始点,对应到曲线上的某个误差值,然后不断的沿着损失函数曲线陡峭程度最大的方向前进,就能更快更准的找到误差的最低点。
这个陡峭程度就是梯度,它是损失函数的导数,对于抛物线而言就是曲线的斜率
另外,因为梯度的方向是损失函数值增加最快的方向,负梯度是损失函数值下降最快的方向,所以我们其实是沿着梯度的反方向前往最低点。这就是为何叫梯度下降的原因
确定了损失函数值的下降方向以后,还需要考虑前进的步长,即学习率
学习率是步长超参数,人为选择,选择学习率时,步子太大即选择数值太大会反复横跳,步子太小会走得很慢浪费计算上面我们是用线性回归做预测函数的,实际情况中房价不仅与面积,还与城市、地段、政策等相关,那么预测函数就会是非线性甚至是曲面多维的各种复杂函数,对应的损失函数也可能是更复杂的,如
上面说了梯度下降的原理,但是实际我们很少直接使用梯度下降,因为我们每次计算梯度时要对每个损失函数求导,这个损失函数是对所有训练样本的平均损失,意味着每次计算梯度都要计算一遍所有样本,花费的时间成本太大了。现在深度学习默认使用的是小批量随机梯度下降方法来训练模型得到最优参数
另外,小批量batchsize也是个超参数, 它选择越小,对收敛越好,即模型拟合数据的越好;对了,上述那个例子中的直线或者说预测函数 y=wx 就可以看作是简单的预测模型,所以才总说训练模型的参数嘛
batchsize选择越小,产生的噪音越多,噪音对神经网络是有一定好处的,深度神经网络太复杂了,一定的噪音可以避免网络模型在训练的时候不会走偏;也就是说模型对各种噪音的容忍度越好,则模型的泛化性就越好,泛化性越好就能让模型更好预测其他新数据
当然,选择太小也不行,会浪费计算,时间成本高啊;batchsize选择太大会虽然导致收敛问题,但只要不是特别大,最后多花点时间还是能收敛的。小批量随机梯度下降中的‘随机’是随机采样的意思,批量大小都是提前定义好的;假如batchsize是128,那么随机从所有样本中采样128个读进内存用于训练



常用的激活函数:
(1)sigmoid
(2)tanh
(3)ReLU
(4)Leaky ReLU
(5)softmax
优化函数:
optimizer = keras.optimizer.SGD(lr=0.001, momentum=0.9)
动量优化
optimizer = keras.optimizer.SGD(lr=0.001, momentum=0.9, nesterov=True)
optimizer = keras.optimizer.RMSprop(lr=0.001, rho=0.9)
RMSProp算法通过只是累加最近迭代中的梯度(而不是自训练开始以来的所有梯度)
optimizer = keras.optimizer.Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
Adam代表自适应钜估计,结合了动量优化和RMSProp的思想:就像动量优化一样,它跟踪过去梯度的指数衰减平均值;想RMSProp一样,它跟踪过去平方梯度的指数衰减平均值。
原文地址:https://blog.csdn.net/chehec2010/article/details/135960770
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_63763.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




