本文介绍: 这种方法避免了计算全局的词到索引映射表,这对于大型语料库来说可能代价很高,但它会遭受潜在的哈希冲突,不同的原始特征经过哈希可能会变成相同的词项。词频-逆文档频率(Term frequency-inverse document frequency,简称TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,用以反映一个词语对于语料库中文档的重要性。一个可选的参数minDF也会影响拟合过程,它指定了一个词必须出现在多少个文档中才能被包含在词汇表中,这个数字可以是具体数目(如果小于1.0,则表示比例)。
本节介绍了用于处理特征的算法,大致可以分为以下几组:
###Feature Extractors(特征提取器)
####TF-IDF
词频-逆文档频率(Term frequency-inverse document frequency,简称TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,用以反映一个词语对于语料库中文档的重要性。用t表示一个词语,用d表示一个文档,用D表示语料库。词频TF(t,d)是词语t在文档d中出现的次数,而文档频率DF(t,D)是包含词语t的文档数量。如果我们仅使用词频来衡量重要性,那么很容易过分强调那些出现非常频繁但对文档信息贡献较小的词语,例如“a”、“the”和“of”。如果一个词语在整个语料库中出现得非常频繁,这意味着它对特定文档没有携带特殊信息。逆文档频率是衡量一个词语提供了多少信息的数值度量:
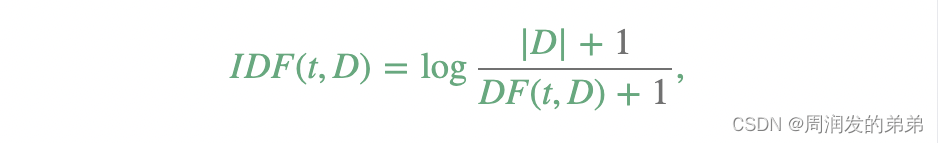
其中|D|是语料库中文档的总数。由于使用了对数,如果一个词语出现在所有文档中,其逆文档频率(IDF)值将变为0。注意,为了避免对语料库外的词语进行除零操作,应用了平滑项。TF-IDF值简单地是词频(TF)和逆文档频率(IDF)的乘积:
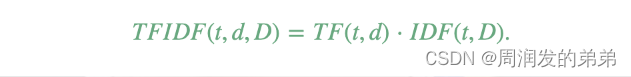
在词频和文档频率的定义上有几种不同的变体。在MLlib中,我们将TF和IDF分开,以使它们更加灵活。
TF:HashingTF和CountVectorizer都可以用来生成词频向量。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)
![[word] word中怎么插入另外一个word文档 #媒体#职场发展](https://img-blog.csdnimg.cn/img_convert/36ffef6b3060628ccf540a56f6069cb0.png)




