本文介绍: NR写在后面则在后面显示行号root 1bin 2daemon 3adm 4lp 5sync 6shutdown 7halt 8#可以用制表符root 1bin 2daemon 3adm 4lp 5#NR写在前面则在前面显示行号1 root2 bin3 daemon4 adm5 lpa[1]=20;a[2]=30;
一、awk的介绍:
1.awk的简介:
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具
可以在无交互的模式下实现复杂的文本操作
相较于sed常作用于一整个行的处理,awk则比较倾向于一行当中分成数个字段来处理,因为awk相当适合小型的文本数据。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符
2.基本格式:
3.工作原理:
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中, 并按模式或者条件执行编辑命令。
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个”字段”然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符”&&“表示”与”、”“表示”或”、”!“表示”非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
4.awk常见的内置变量:
二.打印方法:
1.基础打印:
打印其中一列:


2.打印全部:
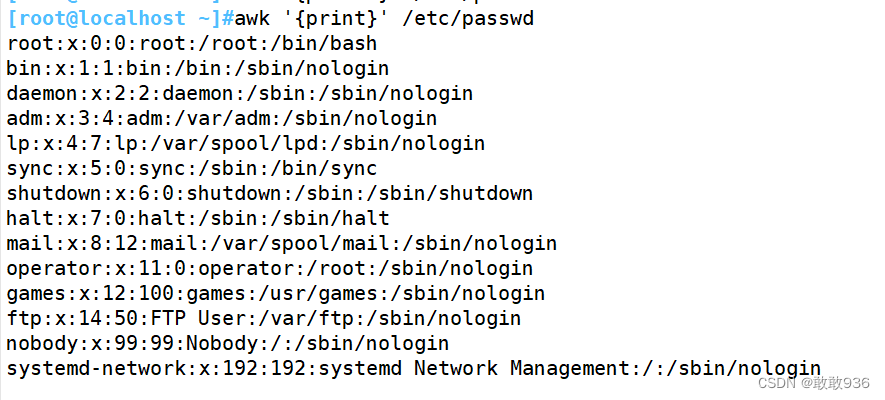


3.打印行内容及其行号:

4.打印指定行内容:


5.奇偶行打印:
5.1打印奇偶数行:


5.2奇偶行打印特殊方式–getline:


6.条件判断打印:



7.提取:
7.1根据$n以及NR提取字段


7.2 根据选项-F指定分隔符:
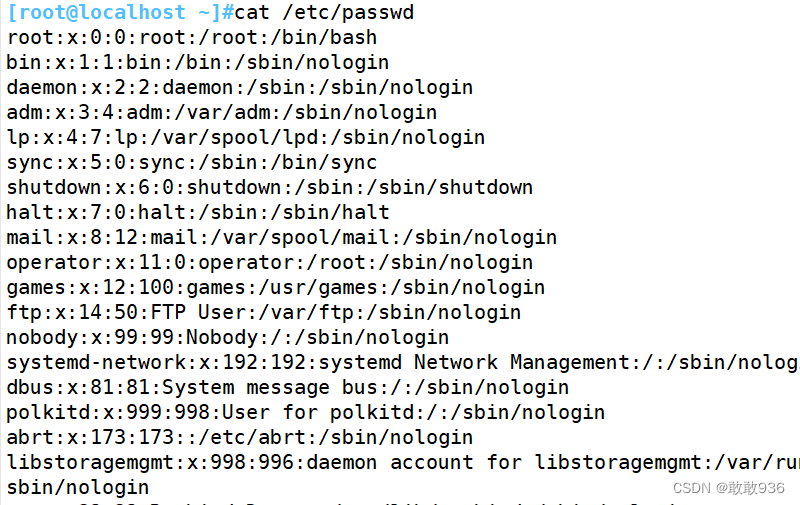

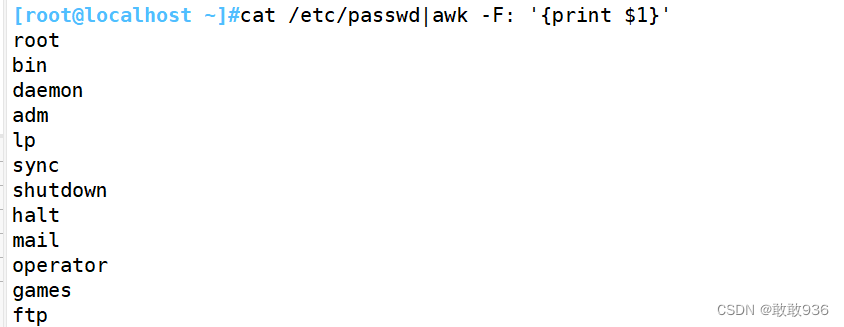
7.3提取多列内容:
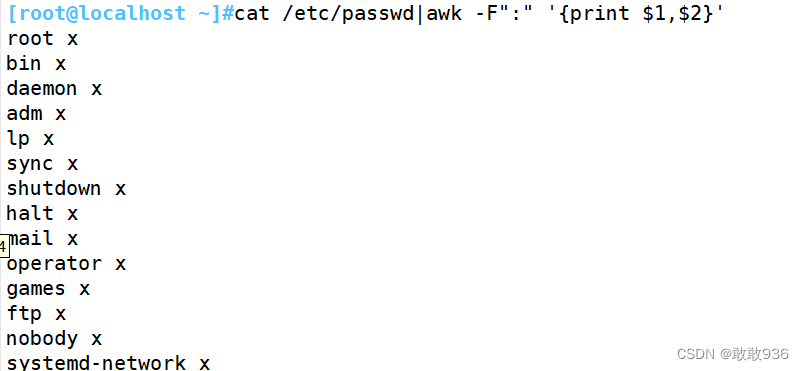
7.4提取磁盘已经使用情况,并去除%:

7.5匹配以root开头的行:

7.6匹配以bash结尾的行:

7.7提取df里面数字:

三、awk的三元表达式:
1. java和shell中的三元表达式:
2.awk三元表达式的应用:

四、awk精准筛选:


五、内置变量的使用:
1.NF-当前处理的行的字段个数:
1.1显示每行有几个字段:

1.2打印出每行最后一个字段:
 1.3 打印出每行倒数第二个字段:
1.3 打印出每行倒数第二个字段:

2.NR:当前处理行的行号:
2.1当前处理行的行号:



2.2 NR==n代表行号等于什么

2.3 NR%2==0取偶数行

2.4 NR%2==1取奇数行:

2.5 NR==1,NR==4取区间行:

2.6 取UID数值范围$n>1000:

六、awk的分隔符:
1.RS 指定分隔符:

2.指定输出的分隔符:
2.1 FS 输入时的列分隔符:

3.awk结合数组运用:
3.1 awk中定义数组打印:

3.2 去重打印数组:
七、关系表达式:

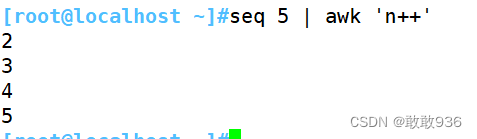


八、awk脚本:

九、试题练习:
1. 统计/etc/fstab文件中每个文件系统类型出现的次数:

2.统计/etc/fstab文件中每个单词出现的次数:

3.提取主机名:



4.提取任意字符串中的数字:

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。