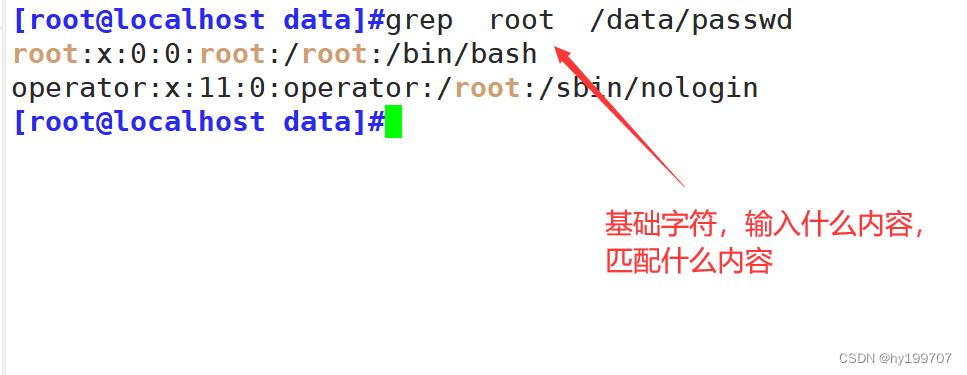
一,正则表达式
(一)正则表达式相关定义
1,正则表达式含义
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,但与通配符不同,通配符功能是用来处理文件名,而正则表达式是处理文本内容中字符。
2,正则表达式支持的语言
vim, less,grep,sed,awk, nginx,mysql 等
3,正则表达式分类
-
基本正则表达式
-
扩展正则表达式
-
编程语言支持的高级正则表达式
4,基础正则表达式 扩展正则表达式区别
grep sed默认使用基础正则表达式
grep -E、sed -r、egrep、awk扩展正则表达式
扩展正则表达式 加
(二)元字符(字符匹配)
1,常用元字符

2,元字符 (.)的介绍
. 匹配任意单个字符,可以是一个汉字
[root@localhost ~]#ls /etc/|grep rc[.0-6]
#此处的点代表字符
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@localhost ~]#ls /etc/ | grep ‘rc.’
#点值表示点需要转义
rc.d
rc.local
3,元字符 [ ] 的介绍
[root@localhost ~]# ls |grep ‘[zhou].txt’
#匹配[]中任意一个字符
h.txt
o.txt
u.txt
z.txt
[a-z] 小写字母
[A-Z] 大写字母
[root@localhost ~]# ls |grep ‘[^a-z].txt’
#显示非小写字母
(三)表示次数 表示一个qq 号码
1,常用表示次数的元字符
小技巧: 怎么去记 {n} 把斜杠看成转义符

2,匹配规则
h[abcde] 先去匹配 hello h[abcde] 再去匹配world

匹配 1到5 和9

(四)位置锚定

(五)分组或其他
1,定义
分组:( ) 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: 1, 2, 3, … 分组
1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
或者:|
2,例子
2.1 匹配ccc三次
[root@localhost ~]#echo abccc |grep “abc{3}”
abccc
2.2 匹配 abc 三次
[root@localhost ~]#echo abcabcabc |grep “(abc){3}”
#分组 匹配abc
2.3 匹配 1或 2abc
[root@localhost ~]#echo 1abc |grep “1|2abc”
#只匹配了1
1abc
2.4 匹配 1abc 或者 2abc
[root@localhost ~]#echo 1abc |grep “(1|2)abc”
#1abc或者2abc
1abc
2.5 提取ip地址
[root@localhost ~]#ifconfig ens33|grep netmask|grep -o ‘([0-9]{1,3}.){3}[0-9]{3}’|head -1
192.168.91.100
二, 扩展正则表达式(表示字符相差不大)
grep -E 或者egrep
(一)表示次数
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
{,n} #匹配前面的字符至多n次,<=n,n可以为0
{n,} #匹配前面的字符至少n次,<=n,n可以为0
(二) 表示分组
() 分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
后向引用:1, 2, …
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat
(三) 例子
1,表示qq号
[root@localhost ~]#echo “aa940132245” |grep “b[0-9]{6,12}b”
位置锚定后,像aa940132245这种杂项 就不会被过滤了
这样我们只会过滤 我们想要的 qq号

前后加b 位置锚定
如 grep name 可能会匹配 hostname
grep “bnameb” 只会匹配name 前后的b 相当于符号,电脑可以识别


2, 表示邮箱
echo “zhou@qq.com” |grep -E “[[:alnum:]_-]+@[[:alnum:]_]+.[[:alnum:]_]+”
3,表示手机号
echo “13705173391”|grep -E “b1[3456789][0-9]{9}b”
三,grep
(一)通式
grep [选项]… 查找条件 目标文件
(二)选项
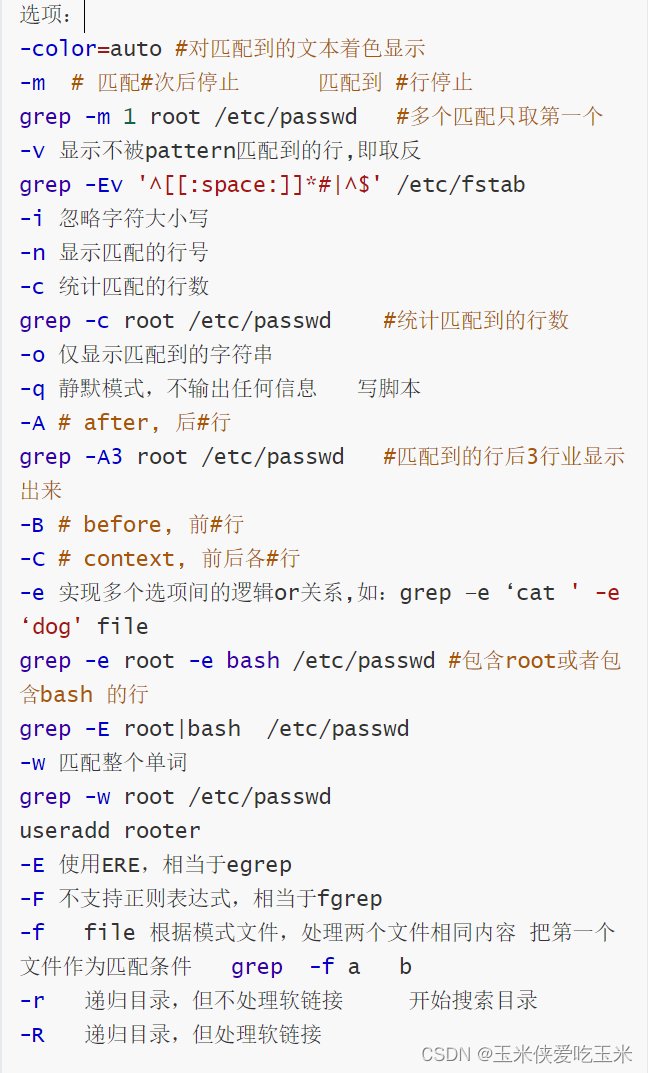
(三)选项详细介绍
1,grep 支持 标准输入,标准输出,文件内容

2,-m 1 匹配一次就停止

3, -i 忽略大小写

4, -c 行数

5,-o 显示匹配内容

6,-A 匹配后三行 -B 匹配前三行 -C 匹配前后三行

7, -e 或

8, -E 启用扩展正则,grep 默认基本正则
9,-W 匹配单词
和正则表达式 b 用途相似

10, -r递归目录,但不处理软链接 -R递归目录,但处理软链接muku
目录 文件夹!!!!!!
(四)示例
1,提取 ip
+ 表示1 或多次
[root@localhost yum.repos.d]# ifconfig ens33 |grep -o “[0-9]+.[0-9]+.[0-9]+.[0-9]+”
192.168.91.100
255.255.255.0
192.168.91.255
[root@localhost yum.repos.d]# ifconfig ens33 |grep -o “[0-9]+.[0-9]+.[0-9]+.[0-9]+”|head -1
192.168.91.100
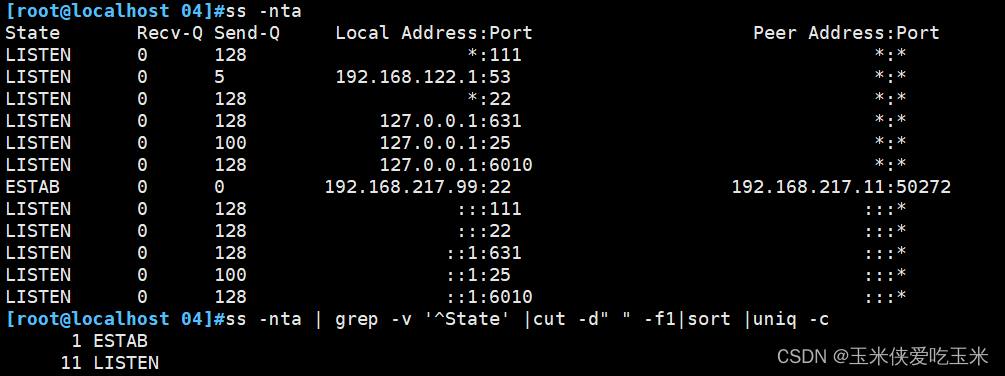
2, 统计当前主机的连接状态
[root@localhost ~]# ss -nta | grep -v ‘^State’ |cut -d” ” -f1|sort |uniq -c
3, 统计当前连接主机数
[root@localhost ~]#ss -nt |tr -s ” “|cut -d ” ” -f5|cut -d “:” -f1 |sort|uniq -c

四,sed
(一)sed 介绍
sed 即 Stream EDitor,和 vi 不同,sed是行编辑器,读取一行处理一行。
用于大文件,电脑内存不够,vim打不开大于内存大小的文件
(二)基本用法
sed [option]… ‘script;script;…’ [input file…]
选项 自身脚本语法 支持标准输入管道
1, 常用选项
常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑[root@www data]#sed -n -e ‘/^r/p’ -e’/^b/p’ /etc/passwd
-f FILE 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式
-i.bak 备份文件并原处编辑#说明:
-ir 不支持
-i -r 支持
-ri 支持
-ni 会清空文件
2,常用基本用法
2.1 sed 为空 看文件内容

2.2 支持重定向
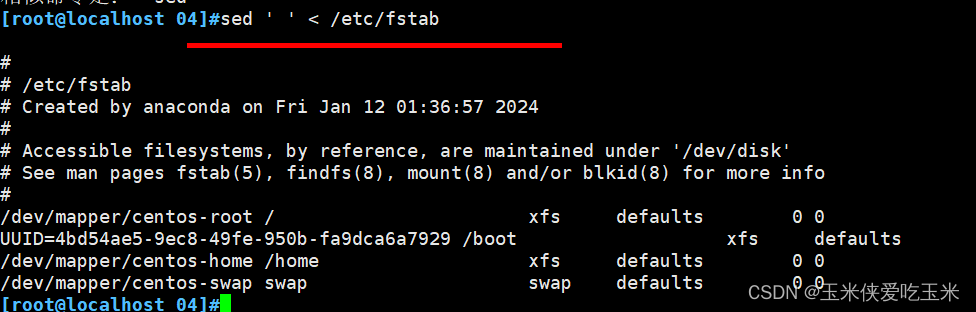
2.3 支持管道符

2.4 n 选项是关闭自动打印 p语法选项打印
系统自带自动打印

(三)sed 脚本格式
单引号中间需要写脚本;脚本格式如下
‘地址+命令’组成
1,地址 相关语法
1.1 不给地址: 全文处理
vim不给地址:默认光标当前行
1.2 单地址:
2p 第二行 $最后一行


1.3 地址范围
1,3 1到3行

1.4 3q 1到3行 (不能加 -n)
1.5 r 开头 f结尾
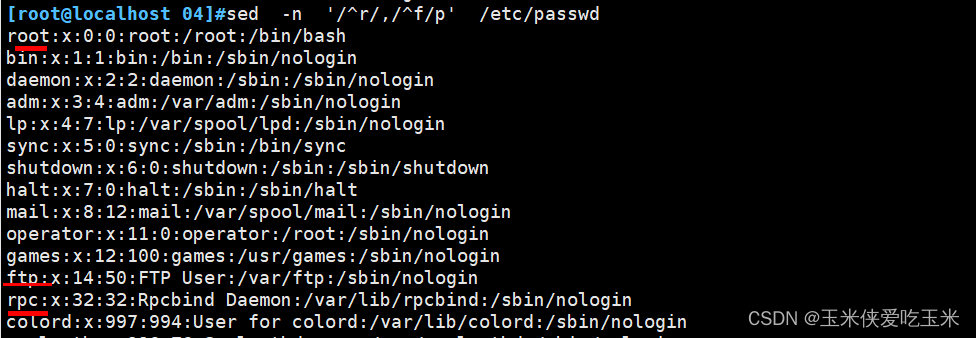
1.6 某一天几点几分 到 某一天几点几分 的日志

12/Jan/2024:04:12:06
这是时间 Jan 和2024 前面的/ 需要转义
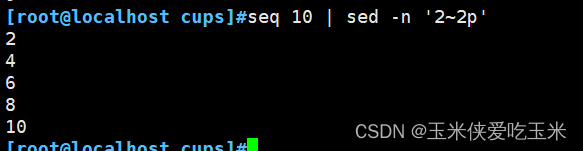
1.7 步进 打印奇数行,偶数行
1~2 奇数
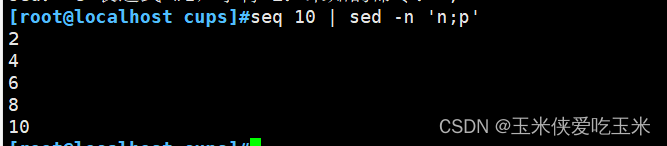
2~2偶数 sed -n ‘n;p’

2,命令相关语法
2.1 命令的选项

2.2 真删 sed -i

2.3 删之前备份 sed -i.bak

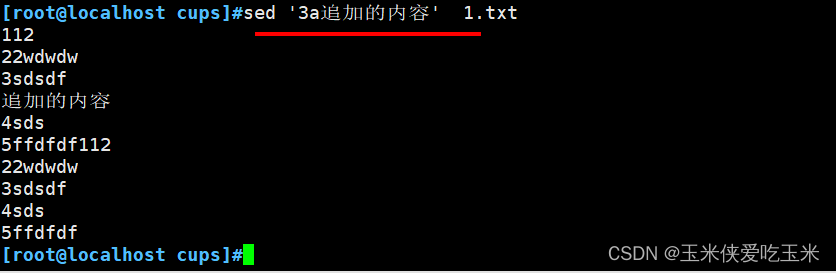
2.4 在第三行的后一行 追加 a
2.5 追加多行内容 n 换行
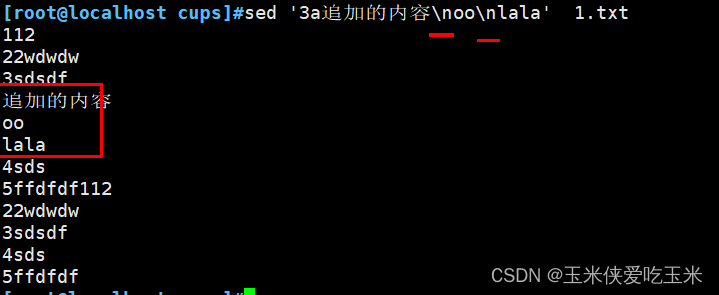
2.6 在第三行的前一行 追加 i
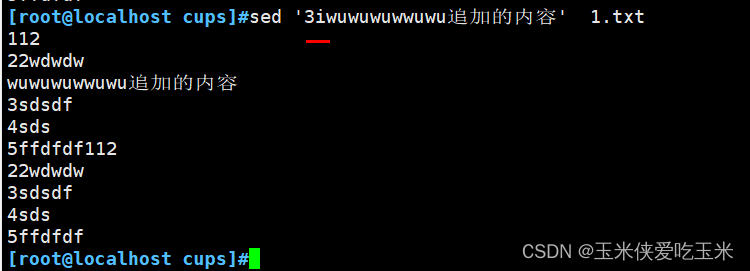
2.7 替换 c
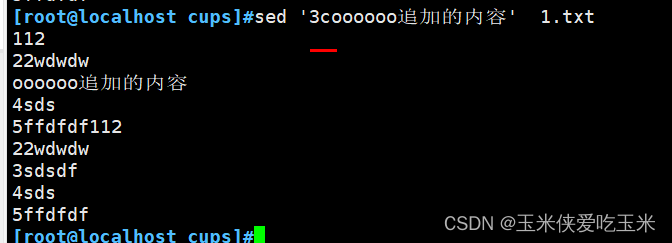
2.8 把第三行写到 新文件 w
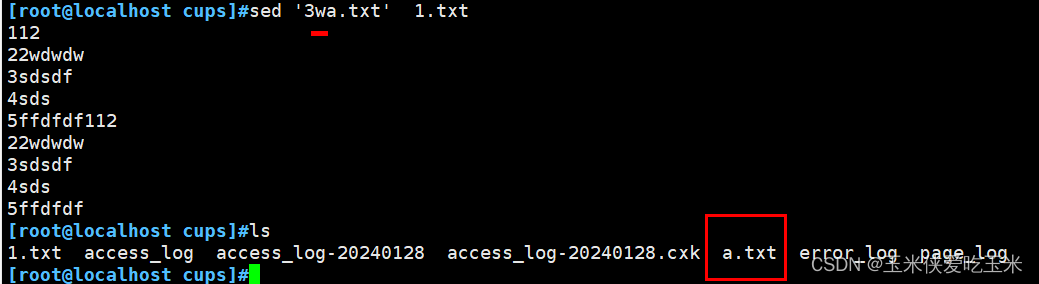
2.9把新文件插入 第二行 r
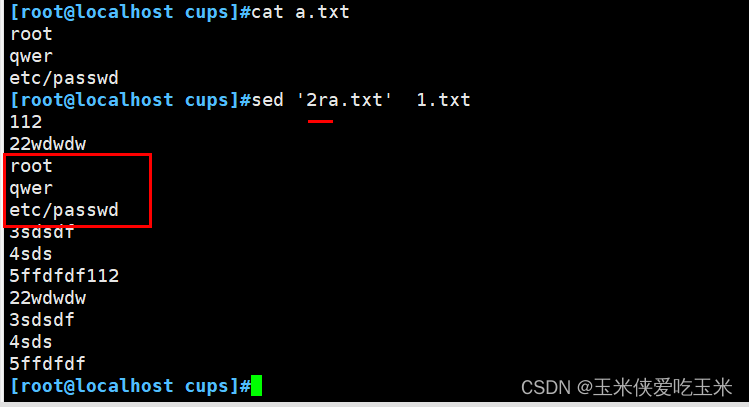
(四) 搜索替代
1,通式
新内容一定是固定的字符串,不能有通配符
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g 行内全局替换
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写
2,示例
2.1 修改防火墙
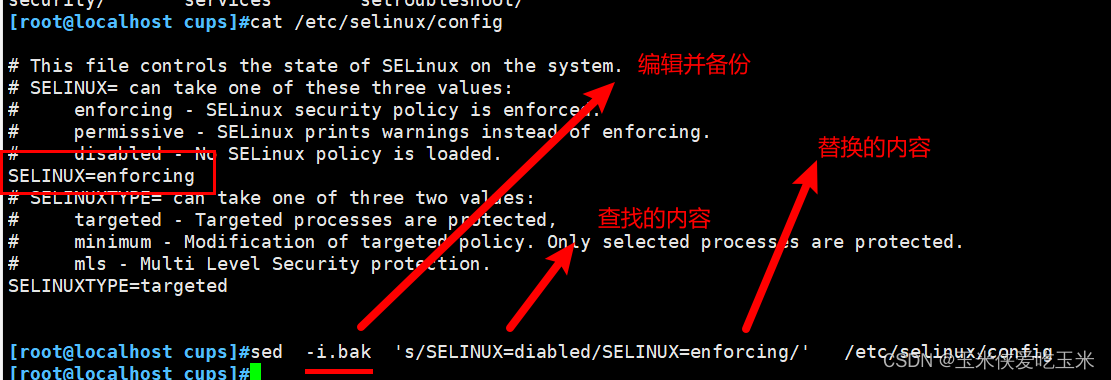
2.2 & 变量 指前面找的内容


2.3 分组替换
-r, -E 使用扩展正则表达式 1 是扩展正则表达式,表示第一个括号里的内容


2.4 提取ip

.* 意思 1到正无穷 任意长度字符 约等于+

2.5 提取中间的数字

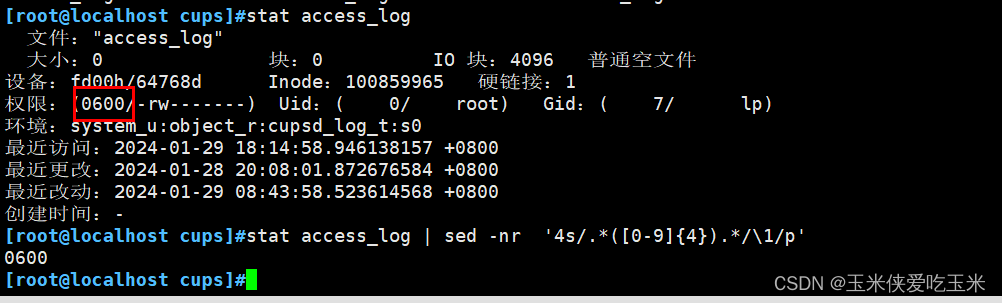
2.6 提文件权限
提取第四行
然后提取(四个0到9的数字)
提取()里的内容
(五)sed 支持变量

(六) 不打开配置文件 改配置文件

(七)sed 高级用法
1,模式空间 保持空间
sed 中除了模式空间,还另外还支持保持空间(Hold Space)
利用此空间,可以将模式空间中的数据,临时保存至保持空间,从而后续接着处理,实现更为强大的功能
2,常见的高级命令

3,示例
3.1 打印偶数行 4种写法
第一种写法:

#解释: ‘n;p’
此处 n 是读取匹配到的行的下一行覆盖至模式空间 p 是打印
先读第一行是 数字1
然后匹配第二行,将第二行覆盖,就是把 数字2 覆盖 数字 1 再输出
这样,第一行,第二行都处理完毕
接下来从第三行开始,以此类推
第二种写法:
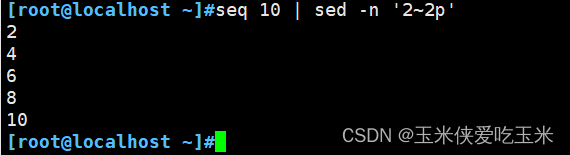
这是步进,从第二行开始,隔两行打印一次
第三种写法:
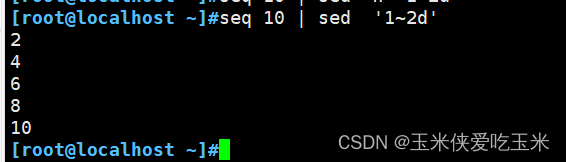
这也是步进 从第一行开始,隔两行删除(删除了奇数行,剩下的就是偶数行)注意次出不要加 -n
第四种写法:
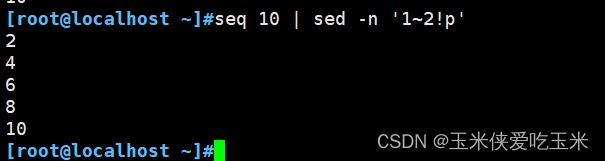
!反选的意思 奇数反选
3.2 小p 大P 区别
小p 是打印的意思 大P 指打印模式空间开端至n内容,并追加到默认输出之前
N 指读取匹配到的行的下一行追加至模式空间
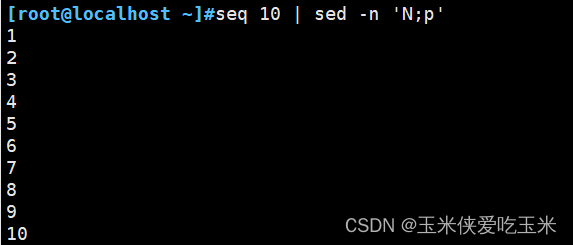
小p 打印
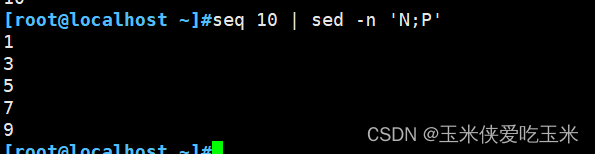
此处N 到模式空间 就是
1
2
大P 是打印 n 之前的内容,(换行之前的内容) 即 数字 1
依次类推,打印奇数
3.3 前后两行追加

3.4 倒序

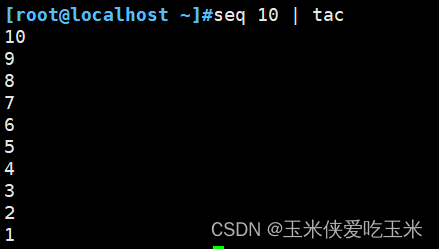
五,awk
(一)awk 含义
vim: 是将整个文件加载到内存中 再进行编辑, 受限你的内存
awk(语言): 读取一行处理一行,
在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,默认以空格或tab键作为分隔符作为分隔(并且默认会压缩空格),并按模式或者条件执行编辑命令。而awk比较倾向于将一行分成多个字段然后进行处理。AWK信息的读入也是逐行
指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互
的情况下实现相当复杂的文本操作,被广泛应用于 Shell 脚本,完成各种自动化配置任务。
(二)工作原理
前面提到 sed 命令常用于一整行的处理,而 awk 比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
(三)awk通式
awk [options] ‘program’ var=value file…
1,program组成
program通常是被放在单引号中,并可以由三种部分组成
-
BEGIN语句块
-
模式匹配的通用语句块
-
END语句块
2,Program格式
xxxxxxxxxx1 11 1pattern{action statements;..}
-
pattern:决定动作语句何时触发及触发事件,比如:BEGIN,END,正则表达式等
-
action statements:对数据进行处理,放在{}内指明,常见:print, printf
-
output statements:print,printf
-
Expressions:算术,比较表达式等
-
Compound statements:组合语句
-
Control statements:if, while等
-
input statements
-
3,awk 常见选项:
-
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-
-v var=value 变量赋值
(四) awk 执行原理
第一步:执行BEGIN{action;… }语句块中的语句
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,
从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{action;…}语句块
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
(五)awk 使用方法
1,输出原来内容

2,提取某一行 并输出

3, 指定分隔符 -F

4, BEGIN语句块 END语句块
改变执行顺序,先BEGIN 再print$1

改变执行顺序,先print$1 最后END

5,重定向
passwd 有多少行 hello 打多少行

6,awk 可以当计算机
注意,此处 awk 没有处理的文件对象,所以加一个BEGIN

7, 提取磁盘占用率
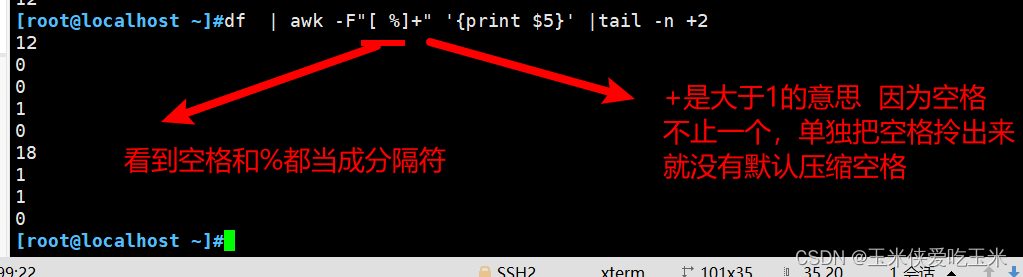

8, 改输出内容分隔符
输出内容默认空格做分隔符

9, 提取网卡的 ip 地址(awk sed)
awk方法;

sed 方法:
 -rn r启用扩展正则 n 不打印
-rn r启用扩展正则 n 不打印
2p 打印第二行
1 打印第一个括号的内容
10,提取普通用户 uid 号大于等于1000

11,统计当前主机的连接状态
第一种方法:
第二种方法:

第三种方法:

#解释
NR!=1 先去掉第一行
a[$1]++ a是数组名 [$1] 第一个位置变量listen 或者estab
a[$1] 就是 a的数组,把isten 或者estab 当做下标且自循环加1(出现一次加1)
end 做完以上结束后,再做下面的动作
for(i in a)print i,a[i] 这是遍历的意思
12,去重

非0 是真 0是假
#解释: zzz 是数组名 $0 就是把一整行作为参数写进去
++是最后执行, 前面!zzz[$0] 处理完再++
针对aa:
初始 取反 是否打印 打印后++
第一次 为空假 非0真 打印 真+1
第二次 真+1 (真) 假 (0) 不打 0+1
第三次 0+1(真) 假(0) 不打 0+1
第四次 0+1(真) 假(0) 不打 0+1
所以aa 不论有多少行只打印一次,达到去重的效果
13,提出主机名,再放指定文件夹
第一种方法:awk

第二种方法:cut

第三张方法:sed

14,统计/etc/fstab文件中每个文件系统类型出现的次数


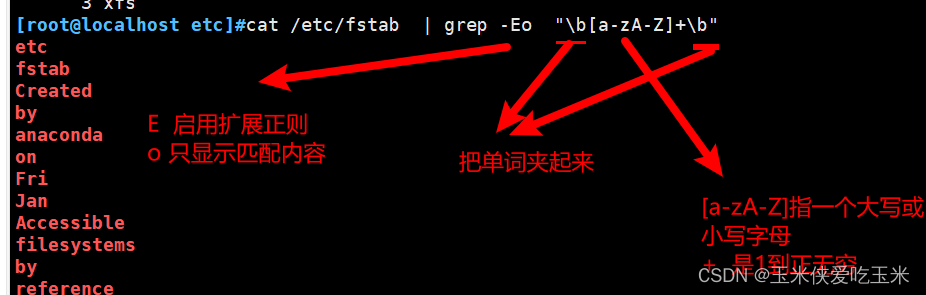
15,统计/etc/fstab文件中 真单词的个数

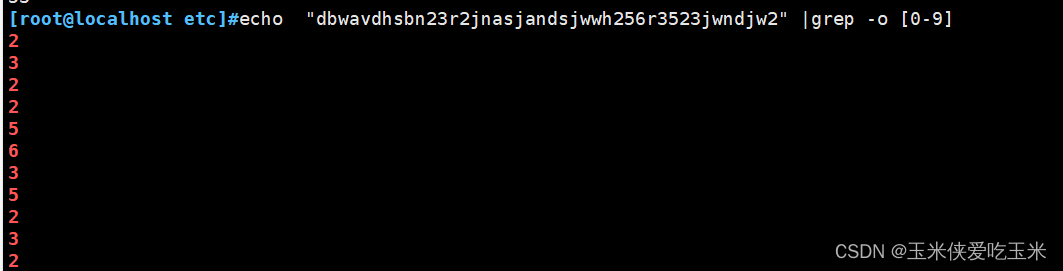
16 , 提取一长串乱码中的数字
17,提取 文件权限
方法1:sed
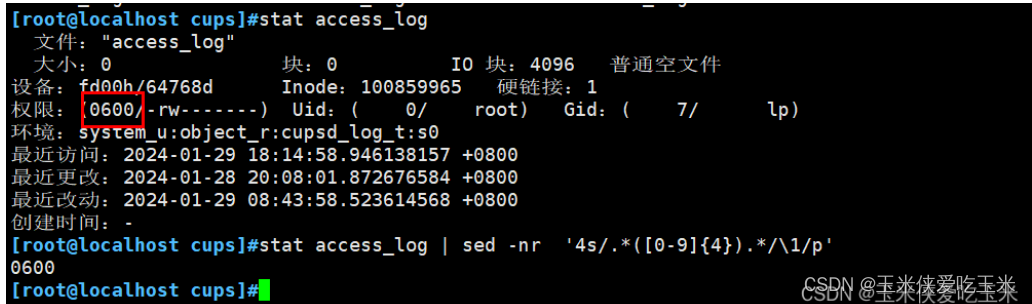
方法2:awk

18,查出uid最大的用户的 uid 用户名 shell类型

这边有个小技巧,awk 提取的时候把 uid放第一列
方便我们后续用 sort -n 排序
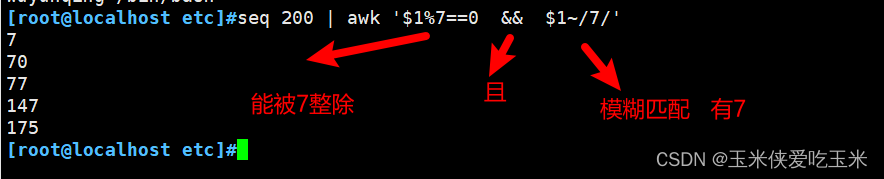
19,打印 1-200 之间所有能被7整除 并且包含数字7 的整数
20,提取内存 使用率
先提出 内存这一行,用使用内存 除 所有内存

取整 并加 %

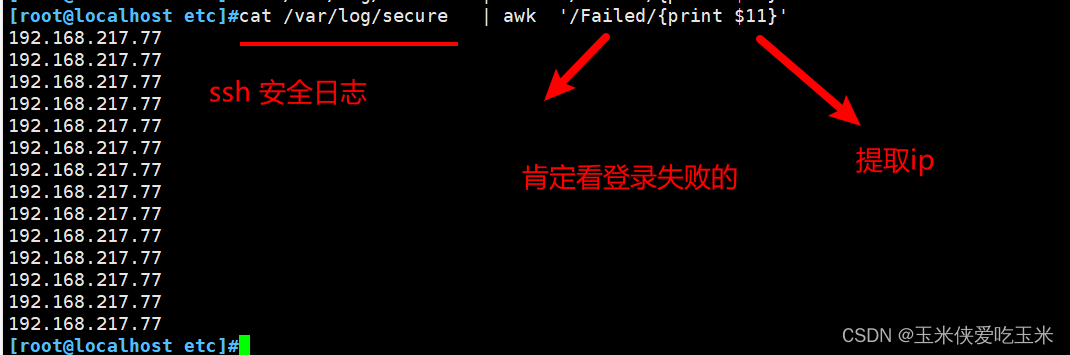
21 ,看ssh 登录失败(看谁在暴力破解密码)

(六)awk 常见的内置变量
awk 选项
-
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-
-v var=value 变量赋值
1,内置变量具体内容
awk 选项 ‘模式{print }’
FS :指定每行文本的字段分隔符,缺省默认为空格或制表符(tab)。与 “-F”作用相同 -v “FS=:”
OFS:输出时的分隔符
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是n
2, 示例展示 内置变量
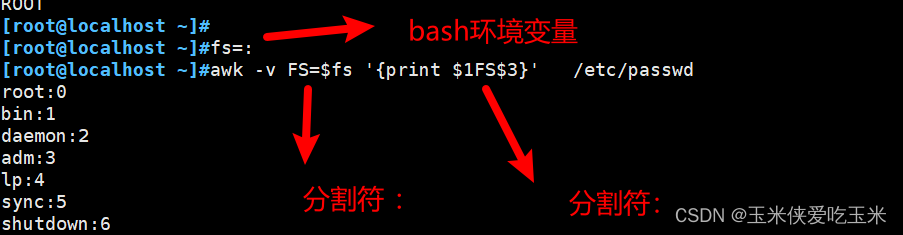
2,1 FS 自定义分隔符
二者效果相同


此外,FS 支持bash 变量
2.2 RS 行分隔符 代表一行结束

2.3 NF 你一行有多少列 $NF 表示最后一列
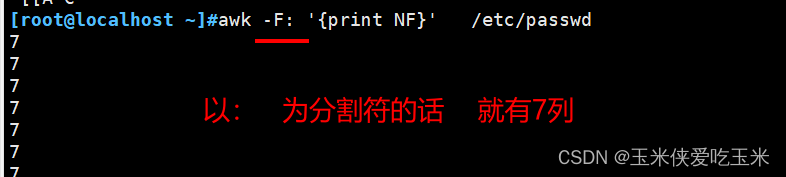

2.4 NR 行号的序号
显示行号

打印第二行 (固定格式 2个等号)

2 到5行

不要第一行
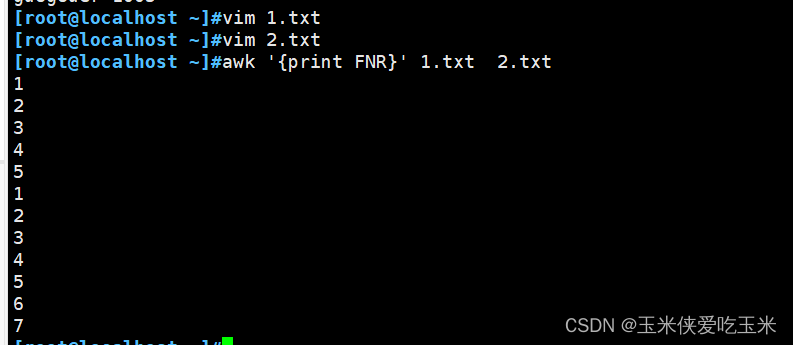
2.5 FNR 将两个文件合并 并显示行号
(七)自定义变量
1,自定义变量具体内容
printf
%s:显示字符串
%d, %i:显示十进制整数
%f:显示为浮点数
%e, %E:显示科学计数法数值
%c:显示字符的ASCII码
%g, %G:以科学计数法或浮点形式显示数值
%u:无符号整数
%%:显示%自身
2,用法

(八)模式
awk ‘模式{处理动作}’
PATTERN:根据pattern条件,过滤匹配的行,再做处理
模式”其实就是选择的”条件”,awk是逐行处理文本的,也就是说,awk会先处理完当前行,再处理下一行,当不指定任何”条件”,awk会一行一行的处理文本中的每一行,如果指定了”条件”,只有满足”条件”的行才会被处理,不满足”条件”的行就不会被处理。
1,正则匹配

2,找到10:00 到11:00 之间的日志
sed -nr ‘/10/,/11/p’
awk ‘/10/,/11/’
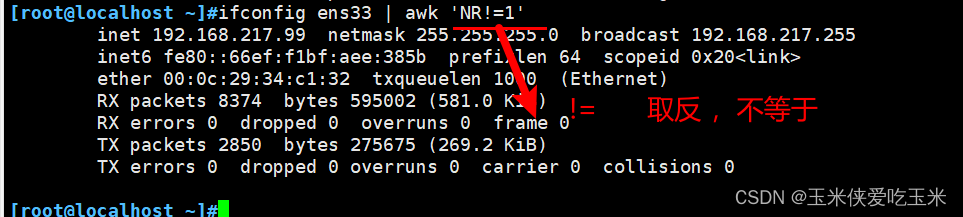
3,关系表达式
非0 是真 0是假
3.1 非0 是真
3.2 n++
除了第一行都打印
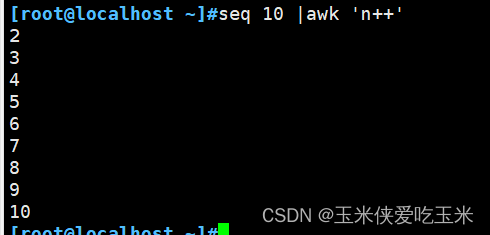
#解释: 第一次循环n=0 所以不打印 数字1
后面循环依次加1 都大于0 所以后面的都打印
3.3 !0
都打印

3.4 i=!i
打印奇数

#解释
i 一开始0 所以第一行假,然后取反 是结果真 最后打印
下一行 真取反 假 不打印
3.5 !(i=!i)
打印偶数

(九)条件判断
1, if 语句
1.1 支持if else
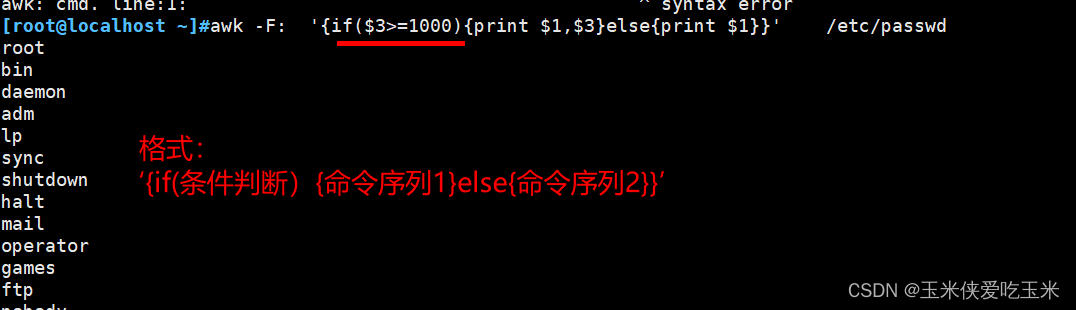
注意 括号不同
1.2 支持多分支
‘{if(判断条件){执行语句1}else if(判断条件){执行语句}else if(判断条件){执行语句}}’
2, 支持 for while 循环语句

3,数组
3,1, awk 数组特性
awk数组特性:
awk的数组是关联数组(即key/value方式的hash数据结构),索引下标可为数值(甚至是负数、小数等),也可为字符串
1. 在内部,awk数组的索引全都是字符串,即使是数值索引在使用时内部也会转换成字符串
2. awk的数组元素的顺序和元素插入时的顺序很可能是不相同的
awk数组支持数组的数组
3.2, awk 数组示例
① 数字1 是关联数组是个符号 不是数字

a为 关联数组的名字 1 是个符号 不是数字
② 遍历数组 遍历出来 顺序不固定

③统计当前主机的连接状态

#解释
NR!=1 先去掉第一行
a[$1]++ a是数组名 [$1] 第一个位置变量listen 或者estab
a[$1] 就是 a的数组,把isten 或者estab 当做下标且自循环加1(出现一次加1)
end 做完以上结束后,再做下面的动作
for(i in a)print i,a[i] 这是遍历的意思
④ 去重
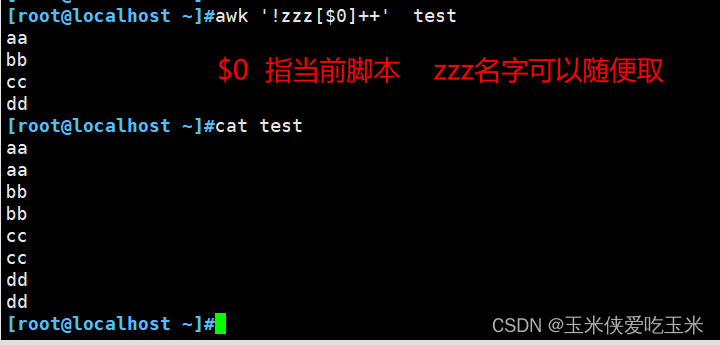
非0 是真 0是假
#解释: zzz 是数组名 $0 就是把一整行作为参数写进去
++是最后执行, 前面!zzz[$0] 处理完再++
针对aa:
初始 取反 是否打印 打印后++
第一次 为空假 非0真 打印 真+1
第二次 真+1 (真) 假 (0) 不打 0+1
第三次 0+1(真) 假(0) 不打 0+1
第四次 0+1(真) 假(0) 不打 0+1
所以aa 不论有多少行只打印一次,达到去重的效果
(十) awk 模糊匹配
1,用~表示包含

2,!~ 表示不包含

原文地址:https://blog.csdn.net/wyq2070857323/article/details/135910579
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_64071.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!