本文介绍: 详解SpringCloud微服务技术栈:深入ElasticSearch(4)——ES集群
ElasticSearch本身就是分布式的,在这里将要讨论如何用3个docker容器来模拟实现ElasticSearch的集群搭建,并且提出集群会出现的脑裂问题并讨论解决方案。
但是这里集群的部署需要我们的Linux虚拟机至少拥有4G的内存空间,内存有限就不要做了。
集群结构介绍
单机的ElasticSearch做数据存储,会面临两个问题:海量数据存储问题,单点故障问题。
针对这两个问题,不得不用集群来解决了:
搭建集群
没有多台电脑,所以这里会利用3个docker容器来模拟3个ES结点。
编写docker-compose文件,里面包含了三个容器结点的部署方案,大致看懂语句的意思是什么:
这个docker-compose文件直接可以从百度网盘中下载并上传到虚拟机:
集群职责及脑裂
分布式新增和查询流程
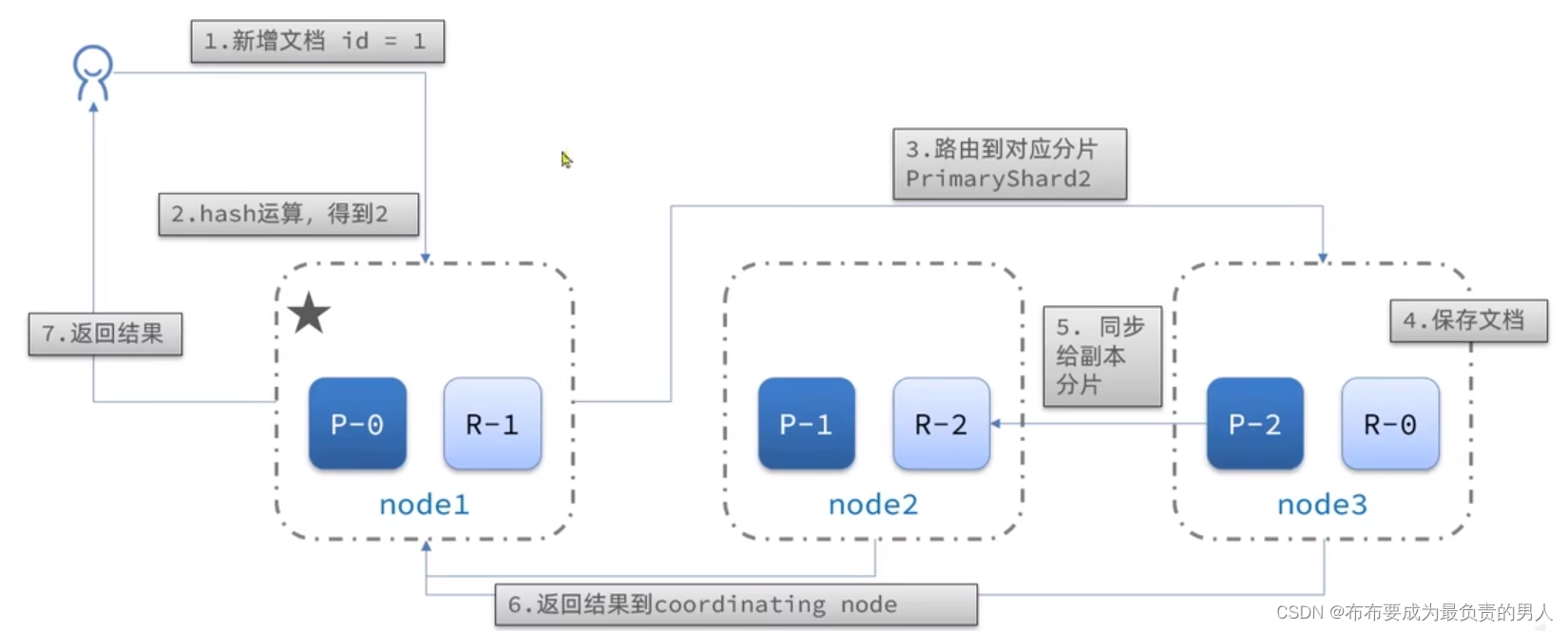
故障转移
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。