数据仓库作为全行或全公司的数据中心和总线,汇集了全行各系统以及外部数据,通过良好的系统架构可以保证系统稳定性和处理高效性,那如何保障系统数据的完备性、规范性和统一性呢?这里就需要有良好的数据分区和数据模型,那数据分区在第三部分数据架构中已经介绍,本节将介绍如何进行数据模型的设计。
1、各数据分区的模型设计思路:
数据架构部分中提到了在数据仓库中主要分为以下区域,那各数据区域的主要设计原则如下:

(1)主数据区:主数据区是全行最全的基础数据区,保留历史并作为整个数据仓库的数据主存储区,后续的数据都可以从主数据区数据加工获得,因此主数据区的数据天然就要保留所有历史数据轨迹。
1) 近源模型区:主要是将所有入数据仓库的数据表按历史拉链表或事件表(APPEND算法)的方式保留所有历史数据,因此模型设计较简单,只需要基于源系统表结构,对字段进行数据标准化后,增加保留历史数据算法所需要的日期字段即可。
2)整合模型区:该模型区域按主题方式对数据进行建模,需要对源系统表字段按主题分类划分到不同的主题区域中,并主要按3范式的方式设计表结构,通过主题模型的设计并汇总各系统数据,可以从全行及集团角度进行客户、产品、协议(账户、合同)分析,获得统一视图。比如说,全行有多少客户、有多少产品?通过主题模型事先良好的设计和梳理,可以很快获得相关统计数据。
主数据区的模型设计按顶层设计(自上而下)为主,兼顾应用需求(自下而上)的方式,即需要有全局视角,也要满足应用需求。那顶层设计主要是需要从全行数据角度对源系统的主要业务数据进行入仓,获得全行客户、业务数据的整体视角,同时又保存所有交易明细数据,满足后续的数据分析需求;应用需求指源系统数据的入仓也需要考虑当前集市、数据应用系统的数据需求,因为数据需求是千变万化的,但是只要保留全面的基础的业务数据,就有了加工的基础,当前的数据需求只是考虑的一部分,更多的需要根据业务经验以及主题模型进行数据入仓和模型设计。
主数据模型的设计主要自上而下,近源模型层虽然比较简单,但设计步骤和整合模型类型,分为以下几个步骤:
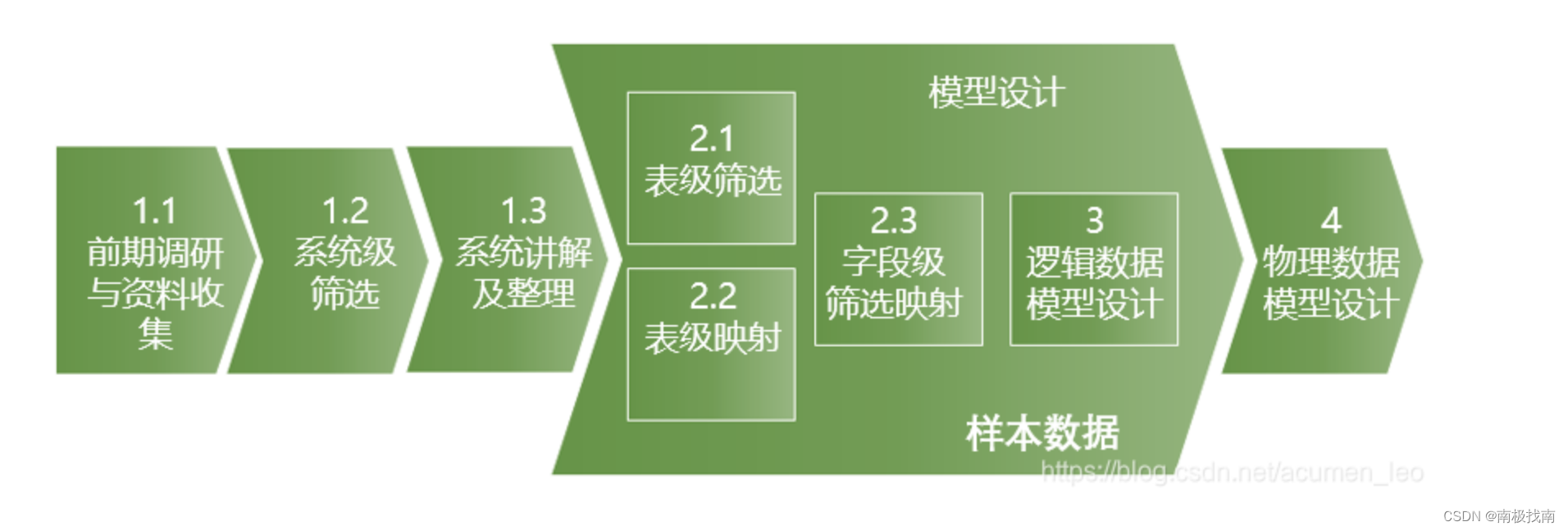
步骤1:系统信息调研,筛选入仓的系统并深入了解业务数据;
步骤2:对入仓系统进行表级筛选和字段筛选,并将字段进行初步映射;
步骤3:根据入仓字段按一定规范设计逻辑模型;
步骤4:对逻辑模型进行物理化;
(2)集市区:集市区的设计表结构设计主要按维度模型(雪花模型、星形模型)进行设计,主要是为了方便应用分析,满足数据应用需求,集市区一般以切片的形式保留结果历史数据,但保留期限不会太长,比如只保留月末数据以及当前月份的每日切片数据。
数据集市需要从数据仓库获得基础数据,对于仓内集市,可以直接访问或通过视图访问,减少数据存储,仓外集市则需要从数据仓库获得批量数据作为基础数据进行存储加工。因此仓外集市还需要设计基础数据的保留策略。
集市区的设计步骤如下:

(3)接口区:接口区的设计完全根据数据应用系统的接口方式来进行,一般也是维度模型(事实表+维度表)方式,接口区之前也提到过,不做复杂计算,只做简单关联,可以将复杂计算放到集市或指标汇总层加工。
(4)指标汇总区:作为集市接口区和主数据区的中间层,主要是提供基于各集市和接口数据的共性需求,基于主模型区数据进行统一加工。即面向所有的应用需求来设计,那中间层一般采用维度模型,按从细粒度到粗粒度的方式逐步汇总。由于各数据应用及集市的需求不断变化,指标汇总区也是不断进行完善,许多一开始在集市的加工由于其它集市或应用也需要,则会从集市转移到指标汇总层。常见的数据就是客户、账户、合同等常用的数据实体的宽表(事实表),统一进行汇总后供各数据应用使用。
另外指标汇总层也包括共性指标的加工,指标可以通过基础指标配置指标计算加工方式获得衍生指标,那这些基础指标和衍生指标的定义、口径以及加工方式可以由指标管理系统来维护并集成到数据标准系统和元数据管理系统中。
指标汇总区设计步骤如下:

(5)非结构化数据存储区:非结构化存储区的设计不仅需要考虑非结构化数据本身的存储,同时需要考虑非结构化数据所带有的结构化属性,因此在设计时主要考虑以下几点:
1)存储路径规划:是需要将非结构化数据按源系统、类型、日期、外部来源等角度进行存储路径的规划,分门别类,便于管理。
2)对非结构化数据的元数据建立索引:比如对于凭证的影像,需要有账户、流水号、客户名等相关结构化数据,以便完整描述影像图片的来源,通过对这些结构化数据建立索引,方便查找。
3)对部分文档内容建立索引:对于部分文档如合同电子版、红头文件PDF需要建立内容索引,以便快速搜索查找文件内容,一般可用支持HADOOP的ElasticSearch来实现。
4)设立计算区和结果区:由于非结构化数据往往需要使用MAPREDUCE或程序化语言进行处理,也会产生中间临时文件和结果数据,因此需要规划计算区和结果区来存放这些数据。
(6)历史数据存储区:历史数据区作为历史数据的归档,即包括结构化数据,也包括非结构化数据,对于历史数据除了存储也需要方便查找,历史数据区的规划设计需要考虑非结构化数据存储区的存储、索引设计外,还需要考虑以下几点:
1)压缩,由于历史数据使用频率低,可以选择压缩率较高的算法,降低存储空间。
2)容量规划:由于历史数据归档会越来越大,因此需要提前进行容量规划以及历史数据清理。比如10年以上的数据进行删除。
3)可设计一个管理系统对历史数据进行归档、查找以及管理。
(7)实时数据区:实时数据区需要使用部分批量数据来和实时流数据进行关联加工,因此可从主数据区获得所需要的数据后进行存放在实时数据区的关联数据区,同时对于加工结果不仅可以推送到KAFKA等消息中间件,同时也可输出到实时数据区的结果区进行保留。
(8)在线查询区:在线查询区主要在线提供计算结果查询,常用HBASE来实现,设计按照接口来分别存放到不同的HBASE表,字段内容也主要是接口字段内容。HBASE表可以根据应用或者接口类型进行分目录和分用户。由于在线查询区和实时数据区考虑到作业的保障级别以及资源竞争,往往会单独建立一套集群,与批量作业集群进行隔离,在线查询的结果计算可以在批量集群计算后加载到在线查询区。
版权声明:本文为acumen_leo博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/acumen_leo/article/details/95033707
原文地址:https://blog.csdn.net/weixin_43889788/article/details/135848017
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_64155.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







