前言
- 在日常开发中,主键id应用是非常广泛的,但是当涉及到分布式系统的时候,往往需要使用到分布式id,每一个服务里面一套生成规则的不易管理,容易引发冲突。
- 我的IM聊天系统中使用分布式id来生成消息唯一键,为后面幂等做准备。后续做幂等可以采用数据库唯一主键来做,也可以使用Redis token 令牌来做,但是都是需要唯一的分布式id。以及涉及到分布分表等场景也是会使用到。
- 这篇文章重点介绍美团Leaf 号段的使用。Leaf是美团推出的一个分布式ID生成服务,名字取自德国哲学家、数学家莱布尼茨的一句话:“There are no two identical leaves in the world.”(“世界上没有两片相同的树叶”),取个名字都这么有寓意,美团程序员牛掰啊!就是自己的IM项目中目前测试阶段用户量也不大,使用号段完全可以顶的住。
本期对应视频,可从b站查看
目前已经写的文章有。并且有对应视频版本。
git项目地址 【IM即时通信系统(企聊聊)】点击可跳转
sprinboot单体项目升级成springcloud项目 【第一期】
前端项目技术选型以及页面展示【第二期】
分布式权限 shiro + jwt + redis【第三期】
给为服务添加运维模块 统一管理【第四期】
微服务数据库模块【第五期】
netty与mq在项目中的使用(第六期)】
分布式websocket即时通信(IM)系统构建指南【第七期】
分布式websocket即时通信(IM)系统保证消息可靠性【第八期】
分布式websocket IM聊天系统相关问题问答【第九期】
什么?websocket也有权限!这个应该怎么做?【第十期】
1.分布式id是什么
生成ID的方式多种多样,可以使用Redis键自增,UUID,或者基于雪花算法实现的ID生成服务。最常见的基于数据库ID自增的方式,在业务数据量不大的时候,单库单表可以支撑,数据再大一点搞个MySQL主从同步、读写分离也能对付。但随着数据日渐增长,主从同步也扛不住了,就需要对数据库进行分库分表,但分库分表后需要有一个唯一ID来标识一条数据,数据库的自增ID显然不能满足需求。
伴随着业务快速迭代,很多业务都需要生成ID,每个微服务各自为政会陷入”重复造轮子”的低效劳动中,同时造成服务治理上的混乱,此时一个能够生成全局唯一ID的服务是非常必要的。那么这个全局唯一ID就叫分布式ID生成服务。
2.常见的分布式id方案
- UUID 当然 不建议(狗头) 它的存储以及查询对 MySQL 的性能消耗较大,
- 号段模式
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。 - Redis
基于全局唯一ID的特性,我们可以通过Redis的INCR命令来生成全局唯一ID。
同样使用Redis也有对应的缺点:ID 生成的持久化问题,如果Redis宕机了怎么进行恢复 - 雪花算法 雪花算法是 Twitter 提出的一种分布式ID生成算法。雪花算法可以在多台机器上生成不重复的ID,支持高并发和大规模的分布式系统。
具体的涉及方案可以网上了解,本期主要讲解美团的开源项目Leaf的分布式id,有两种模式可以进行选择,一种是号段模式,一种是雪花算法。
3.美团分布式id 号段原理
需要插入的数据库
CREATE TABLE `segment_id` (
`biz_tag` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '业务类型',
`max_id` BIGINT(20) NOT NULL DEFAULT '1' COMMENT '当前最大id',
`step` INT(11) NOT NULL COMMENT '号段步长',
`version` INT(20) NOT NULL COMMENT '版本号',
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
比如使用下面的SQL,当需要ID时,先发起查询,然后更新max_id,更新成功则表示获取到新号段[max_id, max_id+step)。
UPDATE segment_id SET max_id=max_id+step, VERSION = VERSION + 1 WHERE VERSION = #{version} and biz_tag = #{biz_tag};
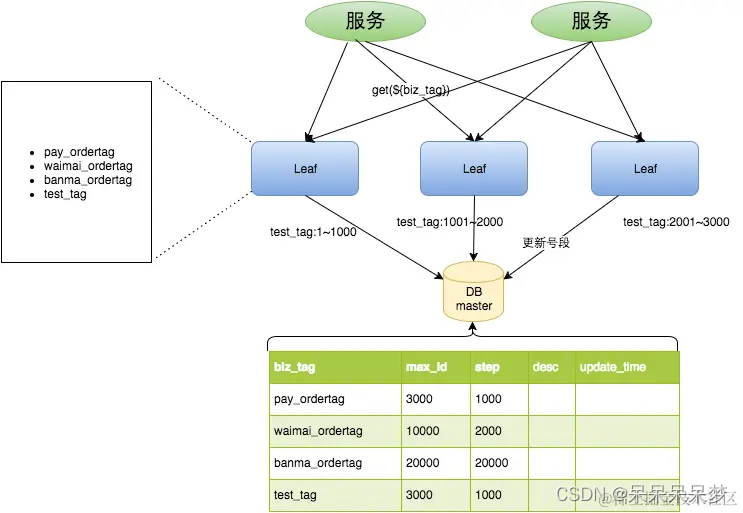
可以从这张图上面看出不同的服务去请求分布式id发号器,然后去数据库中去取一个号段,然后存储起来起始值以及步长在缓存中进行分发,并且美团LeafLeaf还采用了双Buffer异步更新的策略,保证无论何时,都能有一个Buffer的号段可以正常对外提供服务。有兴趣的消小伙伴可以去了解下。
4.改造分布式id
美团的分布式id是基于mysql5.7的,然后就是数据库的版本比较老了,我们项目使用的数据库是Mysql8,需要改一下pom依赖,以及数据库连接池也不一样,也是需要改造一下 。
首先拿出core模块;
美团源码的这个部分直接拿了进去没有做一些更改,然后
在loginuser模块
4.1首先需要数据库建好,然后进行Mysql8的改造。
1.更改pom文件
<mysql-connector-java.version>8.0.14</mysql-connector-java.version>
2.leaf.properties做下面修改
leaf.name=com.sankuai.leaf.opensource.test
# 开启号段模式
leaf.segment.enable=true
leaf.jdbc.url=jdbc:mysql://192.168.1.200:3307/leaf?characterEncoding=utf8&serverTimezone=Asia/Shanghai
leaf.jdbc.username=root
leaf.jdbc.driver-class-name=com.mysql.cj.jdbc.Driver
leaf.jdbc.password=123456
# 开启snowflake模式
leaf.snowflake.enable=false
leaf.snowflake.zk.address=localhost
leaf.snowflake.port=2181
springboot是2.2.5版本,durid是1.1.13 配置如下.
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/yan?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: root
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
#Oracle需要打开注释
#validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: false
test-on-return: false
stat-view-servlet:
enabled: true
url-pattern: /druid/*
#login-username: admin
#login-password: admin
filter:
stat:
log-slow-sql: true
slow-sql-millis: 1000
merge-sql: false
wall:
config:
multi-statement-allow: true
dao层的实际应用.
@Mapper
public interface IDAllocMapper extends BaseMapper<LeafAlloc> {
@Select("SELECT `key`, max_id, step, update_time FROM leaf_alloc")
@Results(value = {
@Result(column = "key", property = "key"),
@Result(column = "max_id", property = "maxId"),
@Result(column = "step", property = "step"),
@Result(column = "update_time", property = "updateTime")
})
List<LeafAlloc> getAllLeafAllocs();
@Select("SELECT `key`, max_id, step FROM leaf_alloc WHERE `key` = #{tag}")
@Results(value = {
@Result(column = "key", property = "key"),
@Result(column = "max_id", property = "maxId"),
@Result(column = "step", property = "step")
})
LeafAlloc getLeafAlloc(@Param("tag") String tag);
@Update("UPDATE leaf_alloc SET max_id = max_id + step WHERE `key` = #{tag}")
void updateMaxId(@Param("tag") String tag);
@Update("UPDATE leaf_alloc SET max_id = max_id + #{step} WHERE `key` = #{key}")
void updateMaxIdByCustomStep(@Param("leafAlloc") LeafAlloc leafAlloc);
@Select("SELECT `key` FROM leaf_alloc")
List<String> getAllTags();
}
原文地址:https://blog.csdn.net/qq_21561833/article/details/135852852
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_64499.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




