前言
本文章是我在完成机器学习课程设计写的总结,共计花费五天左右,在kaggle平台上测试,最高的一次准确率为0.78708。
在使用机器学习相关知识去处理某个实际的问题的时候首先就是从需求理解和问题预处理开始,通过异常数据收集、数据整合、数据分析探索,到模型训练和调优,最后进行模型验证评估。
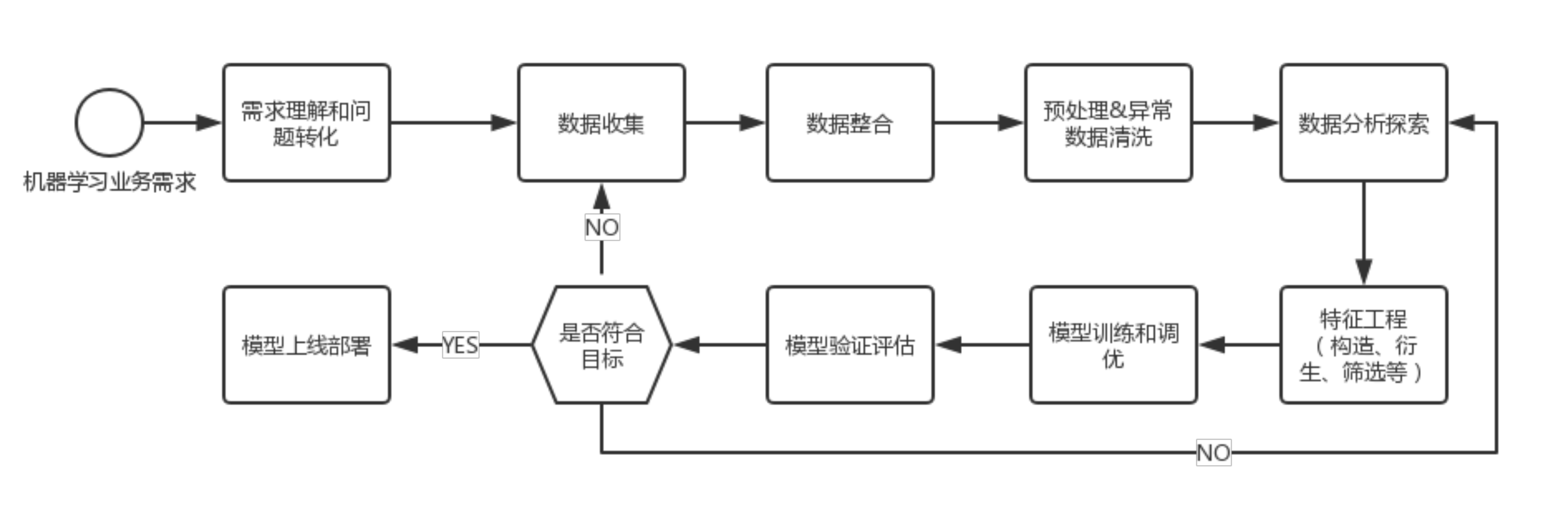
需求理解和问题预处理是整个流程的基础,在本次课程设计中,目标是判断乘客的生还率,怎样基于已有的特征来预测是否生还。
然后就是数据收集,这里我们用了kaggle平台上的数据集。但是这个数据集是不完整的这就需要我们对数据进行预处理和数据清洗。
需要数据进行清洗、整合和探索性分析,寻找数据的规律和特征,为模型的训练提供支持。在这里数据中存在缺失值,缺失值的填充方法有很多:
①如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
②如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
③如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
④有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
同时需要将数据进行因子化,这里我还将差值特别大的特征进行归一化,防止因为差值过大导致欠拟合。
接着就是模型构建,这里我选择了逻辑回归、KNN、SVM三种核函数、深度学习等算法,并进行了模型之间的对比,同时还使用了K折交叉验证,利用bagging算法进行模型融合,防止过拟合,输出预测错误的样本来进行模型调节等等。
一、数据集收集
数据集我是直接用kaggle上的数据集,大家可以自行获取。
链接:数据集![]() https://pan.baidu.com/s/1GjQwk9r6MXigFc8Op0xYdw?pwd=peng
https://pan.baidu.com/s/1GjQwk9r6MXigFc8Op0xYdw?pwd=peng
提取码:peng
原文地址:https://blog.csdn.net/qq_63159704/article/details/135621013
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_64535.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






