来源:B站尚硅谷
大数据概论
大数据概念
大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据主要解决海量数据的采集、存储和分析计算问题。
按顺序给出数据存储单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
1Byte = 8bit 1K = 1024Byte 1MB = 1024K
1G = 1024M 1T = 1024G 1P = 1024T
大数据特点(4V)
大数据应用场景
1、抖音:推荐的都是你喜欢的视频
2、电商站内广告推荐:给用户推荐可能喜欢的商品
3、零售:分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量。经典案例,纸尿布+啤酒。
4、物流仓储:京东物流,上午下单下午送达、下午下单次日上午送达
5、保险:海量数据挖掘及风险预测,助力保险行业精准营销,提升精细化定价能力
6、金融:多维度体现用户特征,帮助金融机构推荐优质客户,防范欺诈风险
7、房产:大数据全面助力房地产行业,打造精准投策与营销,选出更合适的地,建造更合适的楼,卖给更合适的人
8、人工智能 + 5G + 物联网 + 虚拟与现实
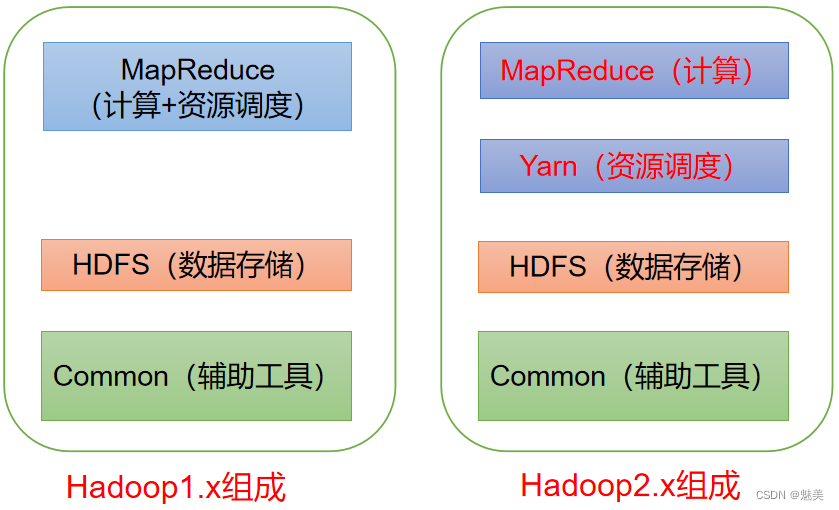
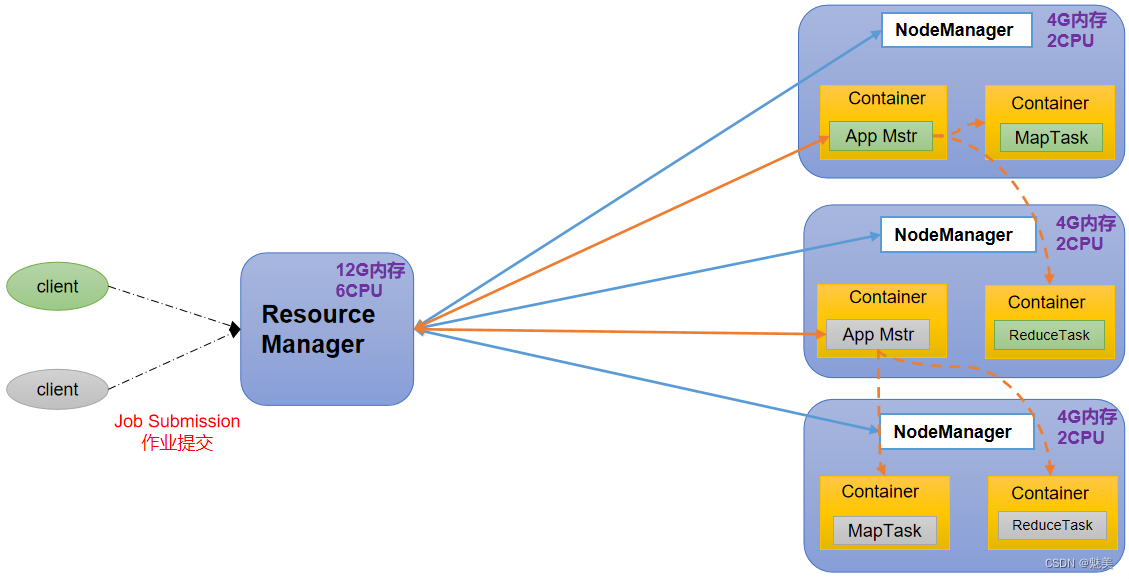
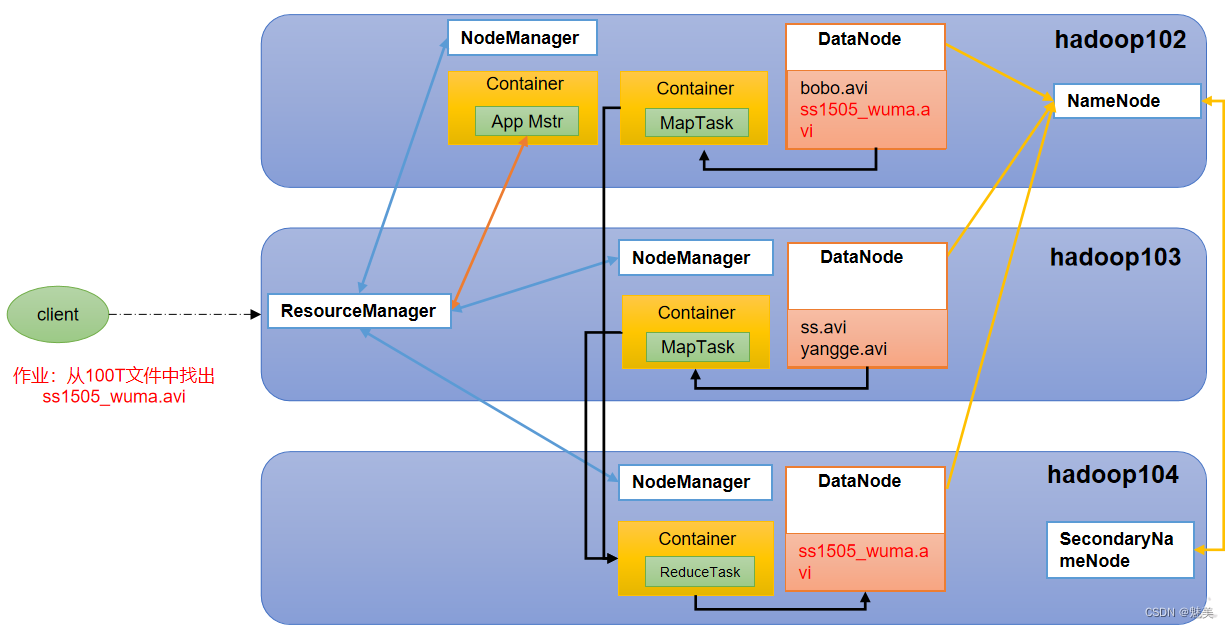
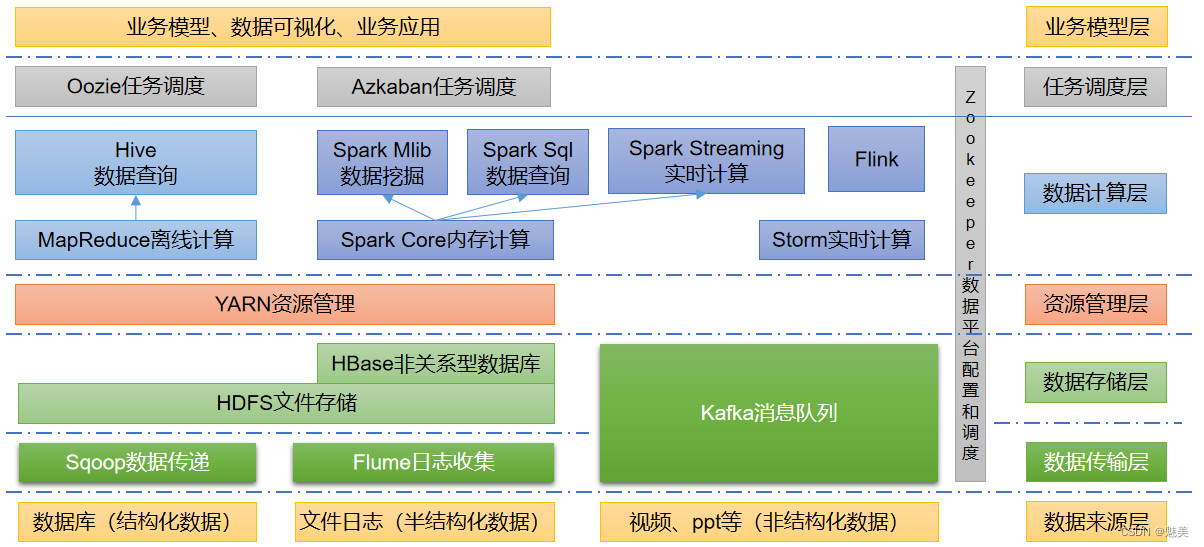
Hadoop概述
Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——**
Hadoop生态圈**。
Hadoop发展历史(了解)
1)Hadoop创始人Doug Cutting,为了实现与Google类似的全文搜索功能,他在Lucene框架基础上进行优化升级,查询引擎和索引引擎。
2)2001年年底Lucene成为Apache基金会的一个子项目。
3)对于海量数据的场景,Lucene框架面对与Google同样的困难,存储海量数据困难,检索海量速度慢。
4)学习和模仿Google解决这些问题的办法 :微型版Nutch。
5)可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
GFS —>HDFS
Map-Reduce —>MR
BigTable —>HBase
6)2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
8)2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS)分别被纳入到 Hadoop 项目中,Hadoop就此正式诞生,标志着大数据时代来临。
9)名字来源于Doug Cutting儿子的玩具大象

Hadoop三大发行版本(了解)
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。2006
Cloudera内部集成了很多大数据框架,对应产品CDH。2008
Hortonworks文档较好,对应产品HDP。2011
Hortonworks现在已经被Cloudera公司收购,推出新的品牌CDP。