前言
对于数据库、中间件的监控,目前社区里最为完善的就是 Prometheus 生态的各个 Exporter,不过这些 Exporter 比较分散,不好管理,如果有很多目标实例需要监控,就要部署很多个 Exporter,要是能有一个大一统的 Exporter,具备所有这些 Exporter 的能力就好了。还真有,而且还不止一个,一个是 Grafana-agent,一个是 Cprobe,Grafana-agent 整合这些 Exporter 相对比较生硬而且缺少了目标实例自动发现机制,好处是 Grafana-agent 不止是整合了常见的 Exporter,还整合了 Promtail 和 OTEL Collector,也可以用于日志和链路数据的采集转发,Cprobe 整合 Exporter 的方式相对更为丝滑且一致性更好,支持目标实例的自动发现机制,专注在指标采集方向,不提供日志采集和链路数据转发能力,两个项目都是开源的,大家根据自己的需求选择。
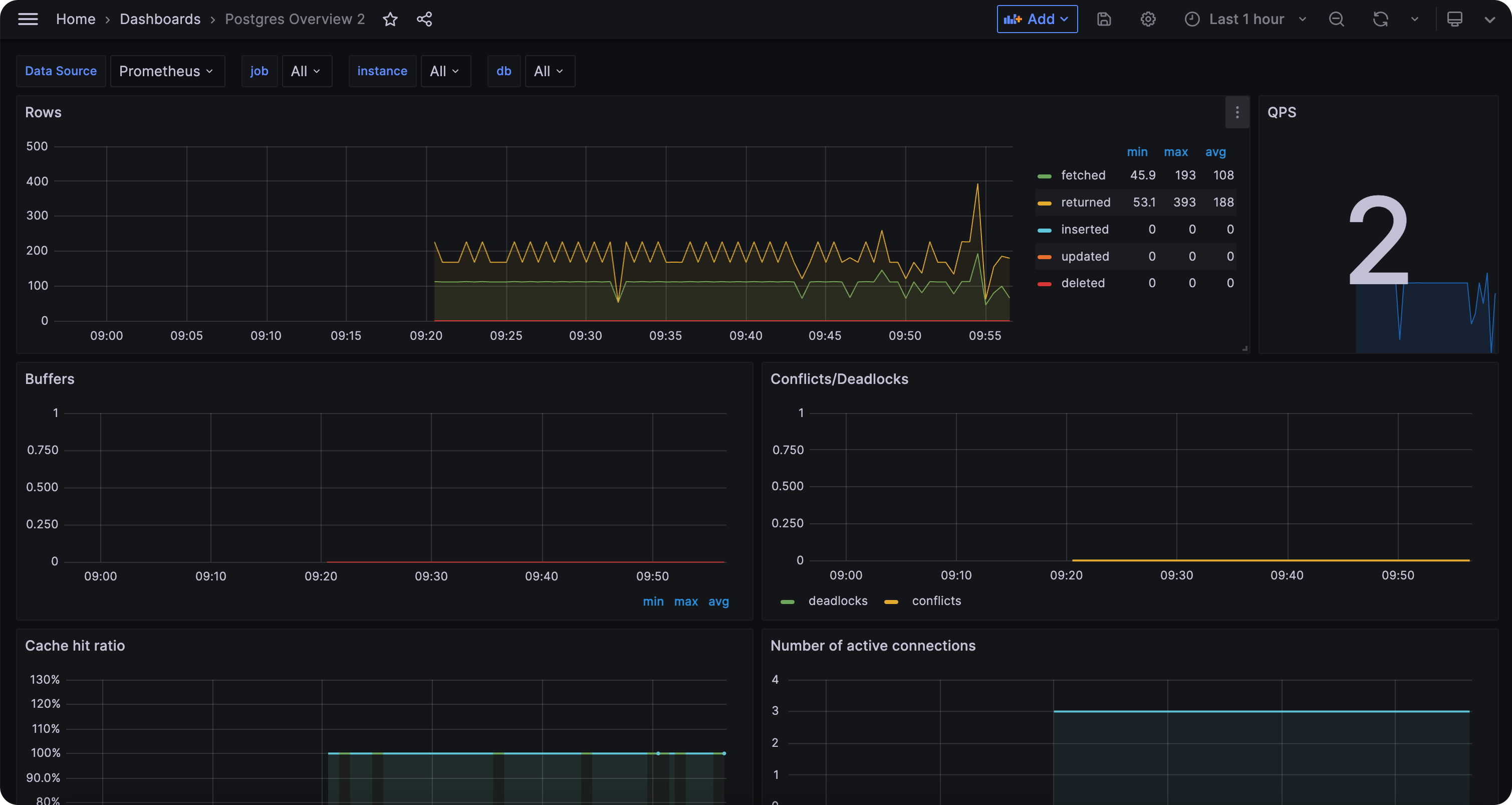
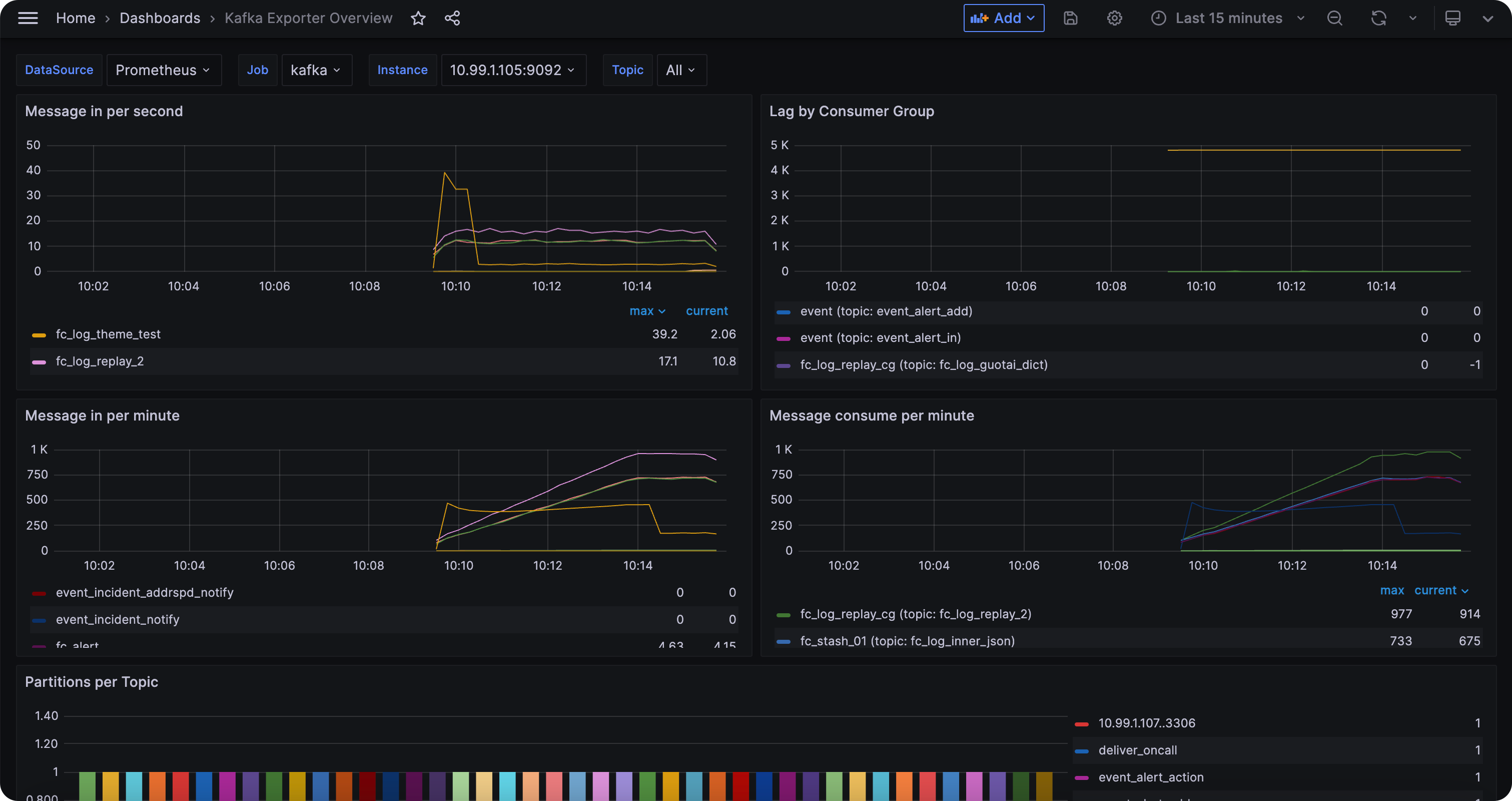
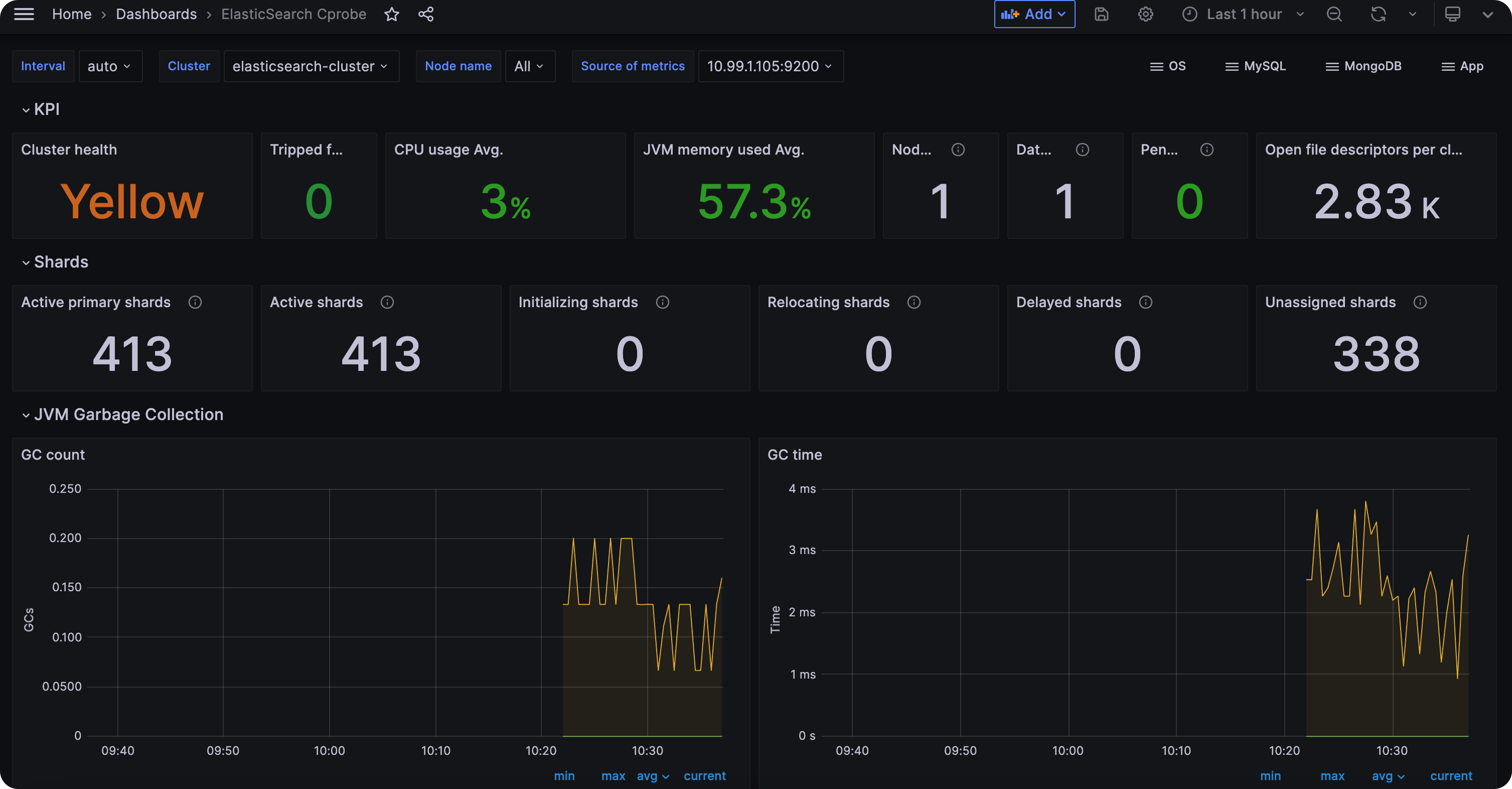
本专栏专注如何构建生产级监控系统,侧重指标监控领域,选择 Cprobe 作为采集器。下面我们对 Cprobe 的通用配置做简要说明。
Cprobe 简介
Cprobe 的 README 中已经放置了相关文档链接,不多总共三四篇,请各位自行阅读,这里就不再赘述了。安装的话,可以采用二进制方式、容器方式、Kubernetes 方式,安装文档在这里:https://github.com/cprobe/cprobe/issues/5,每种安装方式基本就是一条命令的事,简单的很。
Cprobe 的配置文件在 conf.d 目录下,writer.yaml 配置时序库的 remote write 地址,Cprobe 采集了数据之后通过 remote write 协议发送指标数据给时序库。conf.d 下面有不少目录,每个目录对应一个采集插件,每个采集插件的目录下通常都会有一个 main.yaml 的入口配置,main.yaml 中配置要采集的监控目标的地址,当然,也可以不写死目标实例的地址,而是通过 HTTP SD 或 File SD 的方式动态发现监控目标。其次,main.yaml 中一般会有 scrape_rule_files 配置项,配置各个 job 的采集规则,这是个数组,程序处理时会把数组里的每个规则文件拼接成一个整体来使用,即:通过这种方式可以实现配置文件拆分管理。举例:
另外,每个插件目录下通常有个 doc/README.md 文件,里面会有该插件的详细说明,并且会有插件对应的仪表盘和告警规则的模板。OK,下面我们就来看看如何配置 Cprobe 来监控常见的数据库、中间件。
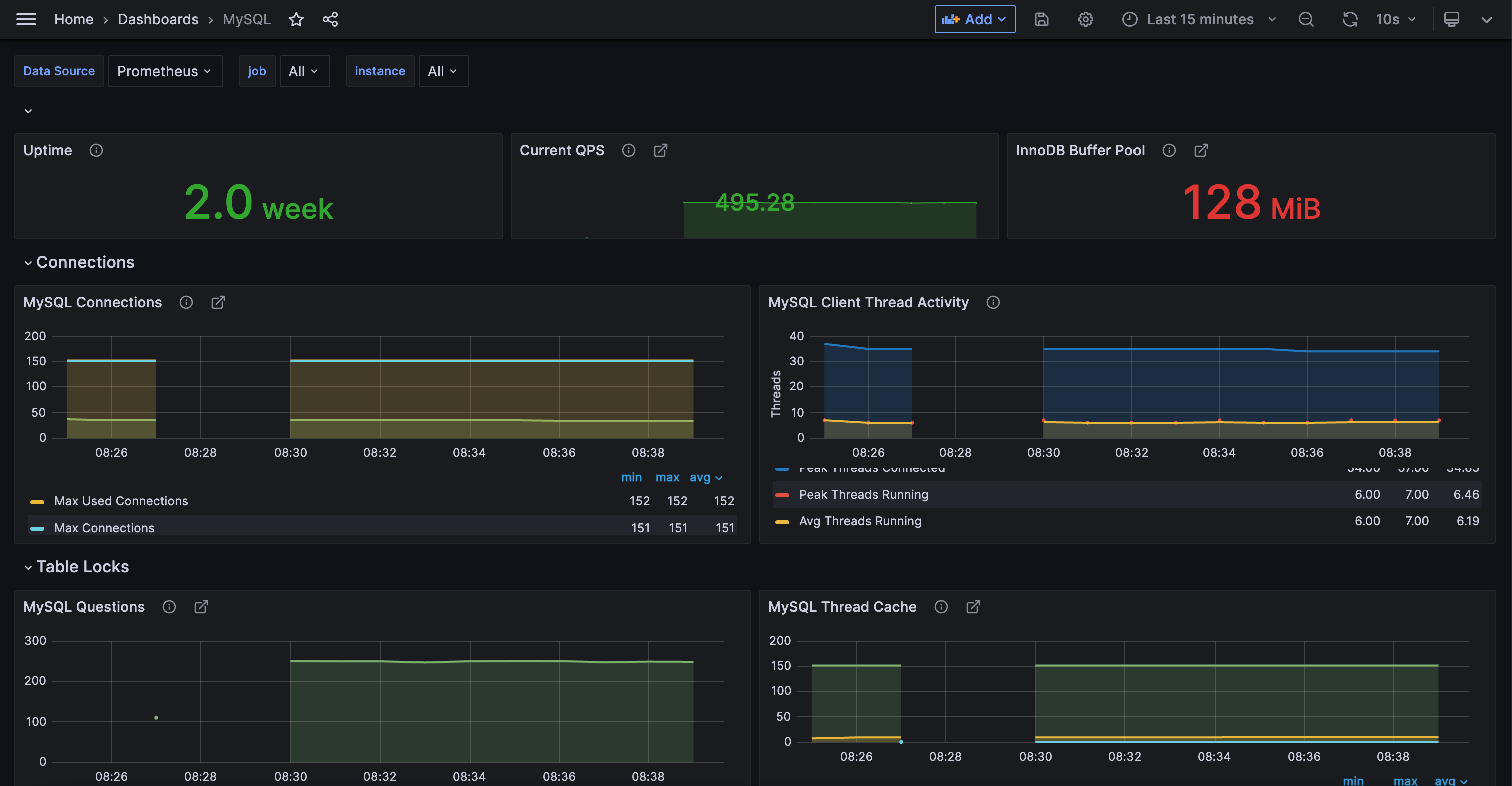
MySQL
MySQL 的监控插件配置在 conf.d/mysql 目录下,我给大家演示一下监控 3 个 MySQL 实例的配置,首先是 main.yaml: