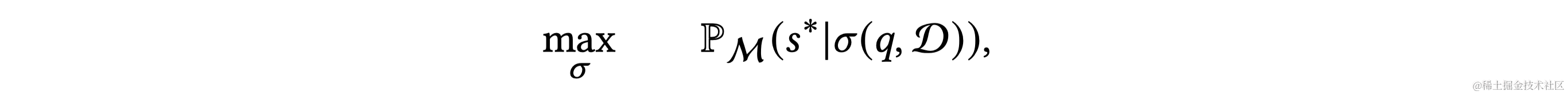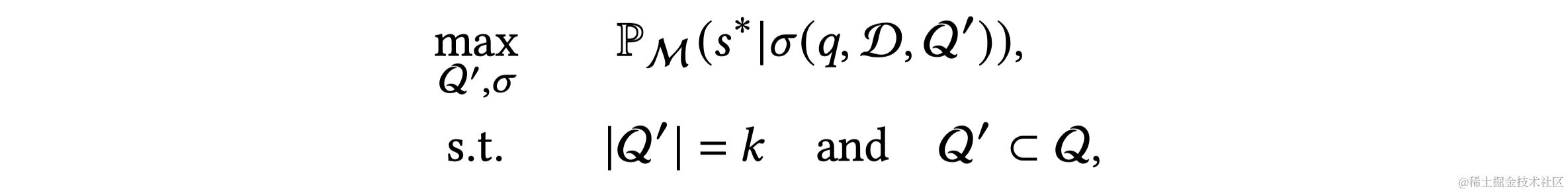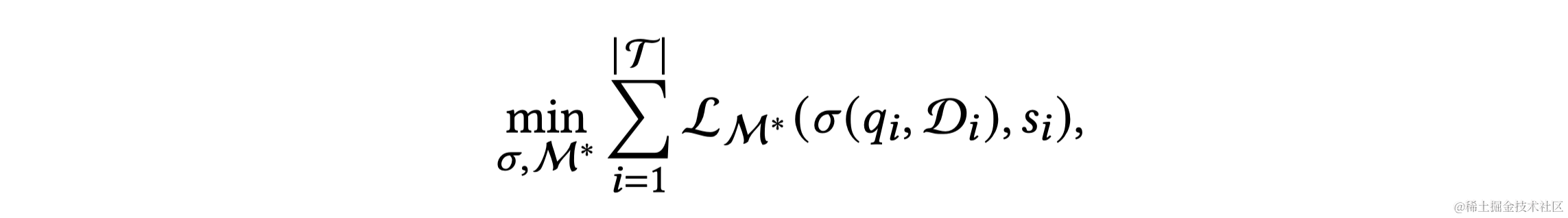导语
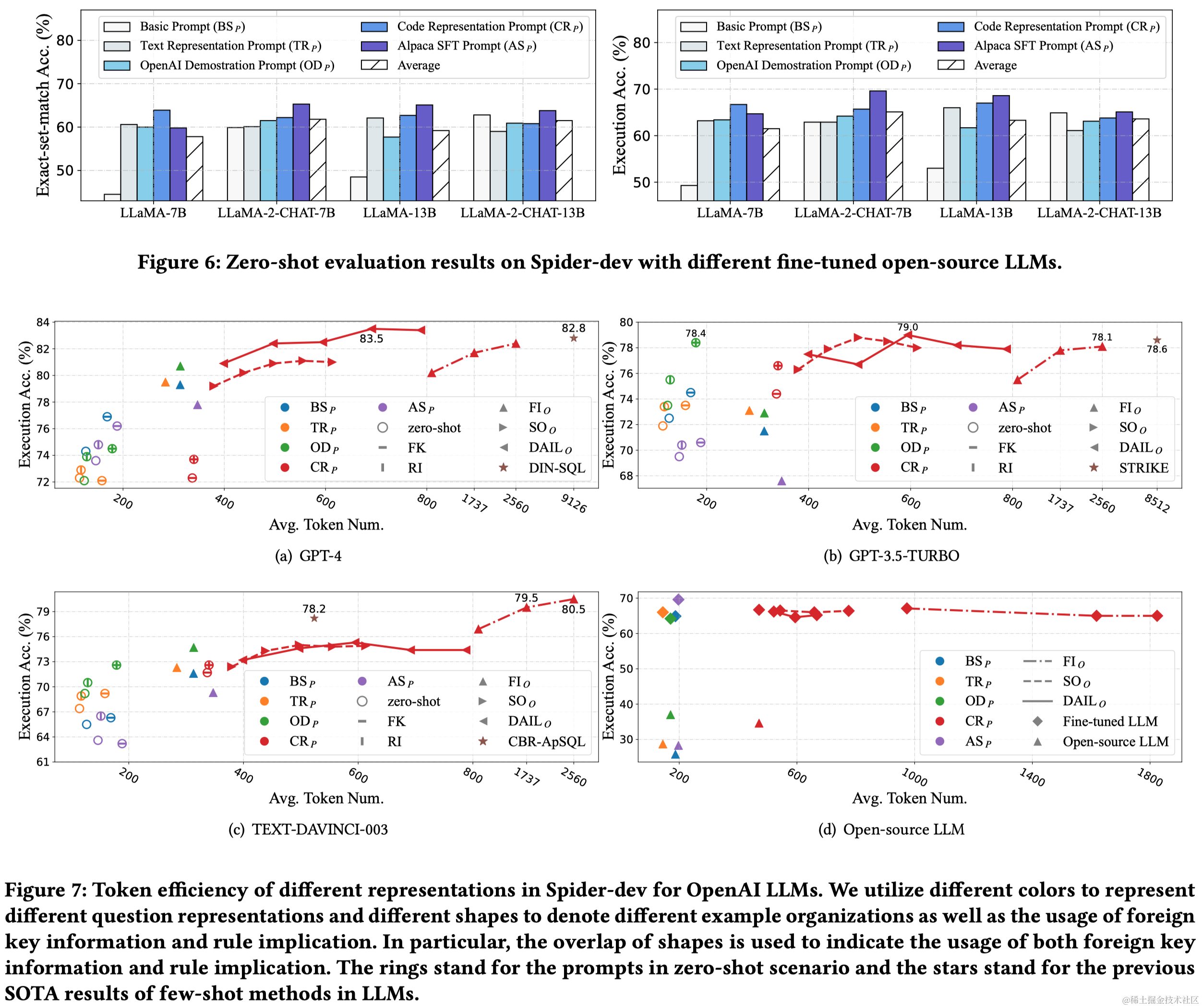
本文聚焦于利用LLMs进行Text-to-SQL任务,并指出缺乏系统性基准测试限制了有效、高效和经济的LLM-based Text-to-SQL解决方案的发展。研究者首先系统地比较了现有的提示工程方法,并分析了它们的优缺点。基于这些发现,提出了一个新的综合解决方案,名为DAIL-SQL,该解决方案在Spider排行榜上以86.6%的执行准确率刷新了SOTA。
1 简介
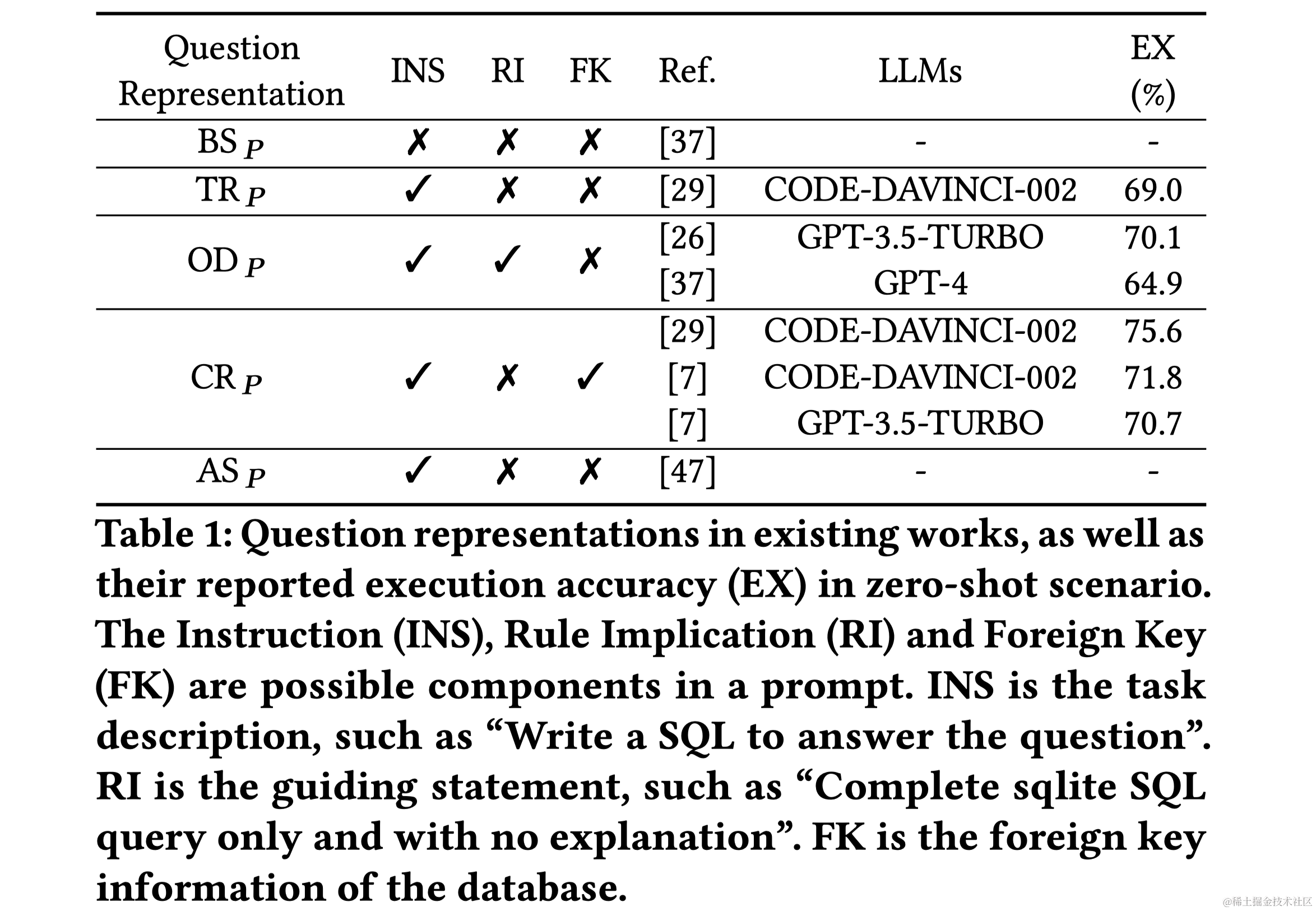
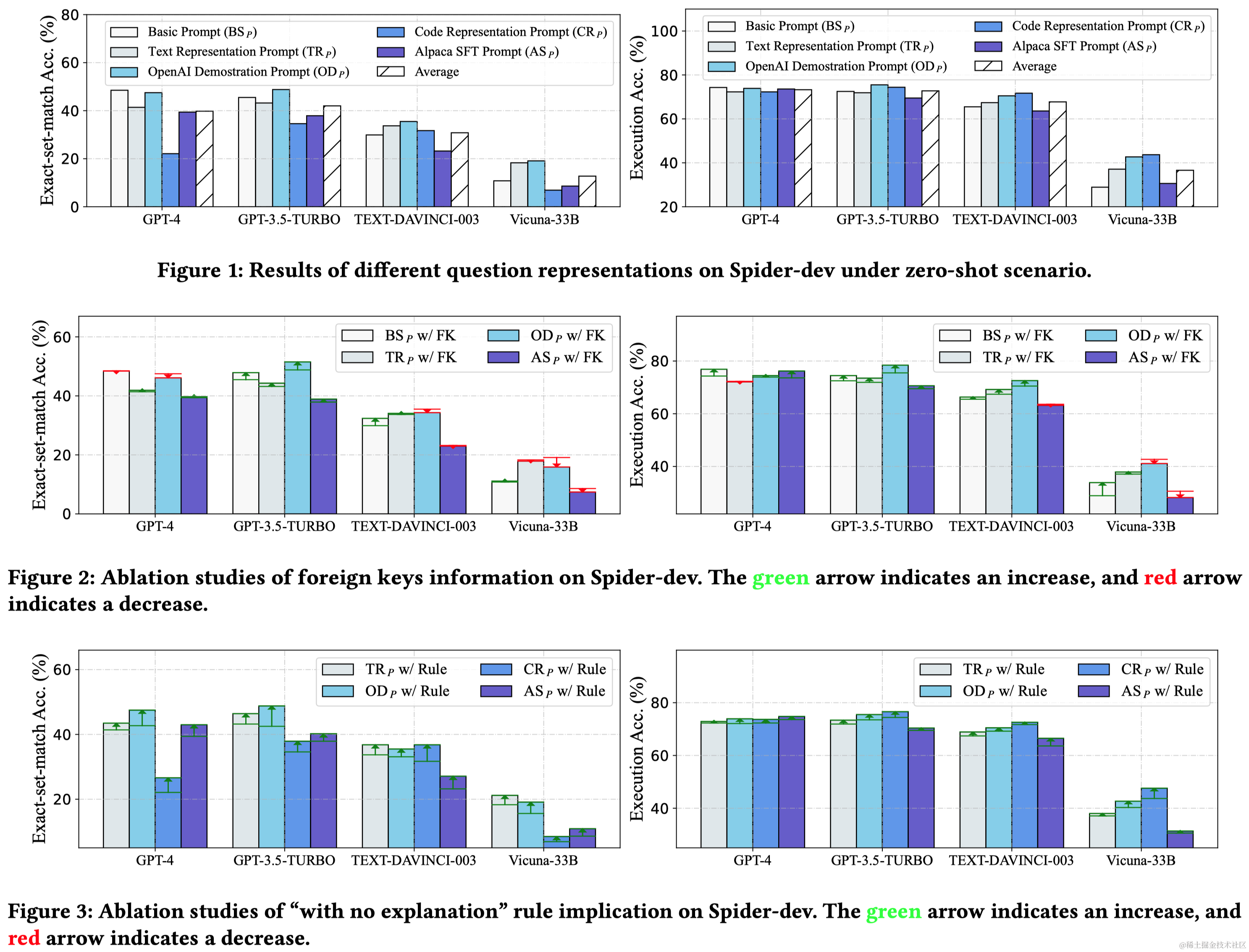
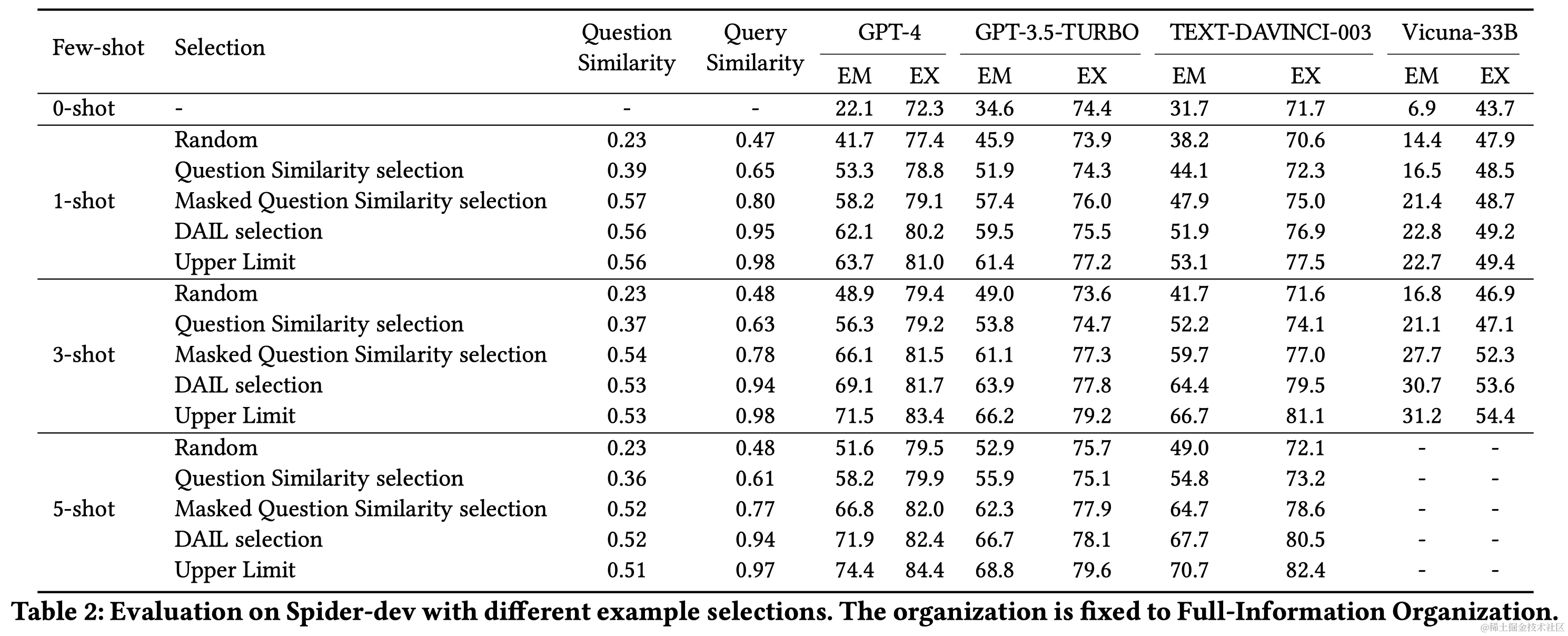
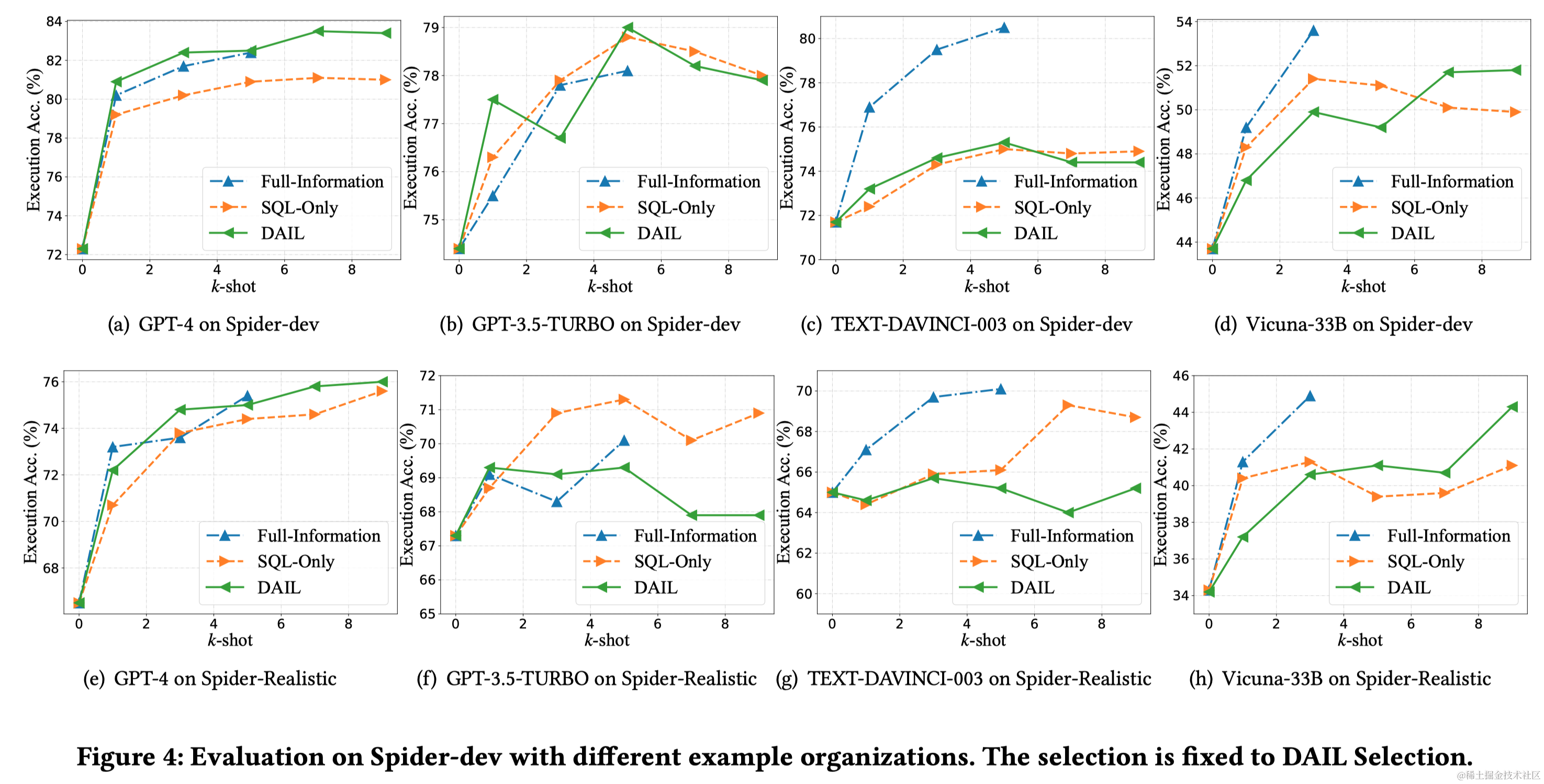
Text-to-SQL任务是将自然语言问题转换成SQL查询,这对自然语言处理和数据库领域都是一项挑战。近年来,大型语言模型(LLMs)成为Text-to-SQL任务的新范式。特别是,GPT-4实现了在Spider排行榜上85.3%的执行准确率。尽管已有研究取得进展,但LLM基础的Text-to-SQL解决方案的提示工程缺乏系统性研究。目前研究集中在问题表示、示例选择和示例组织上,以适应LLM的偏好和性能。
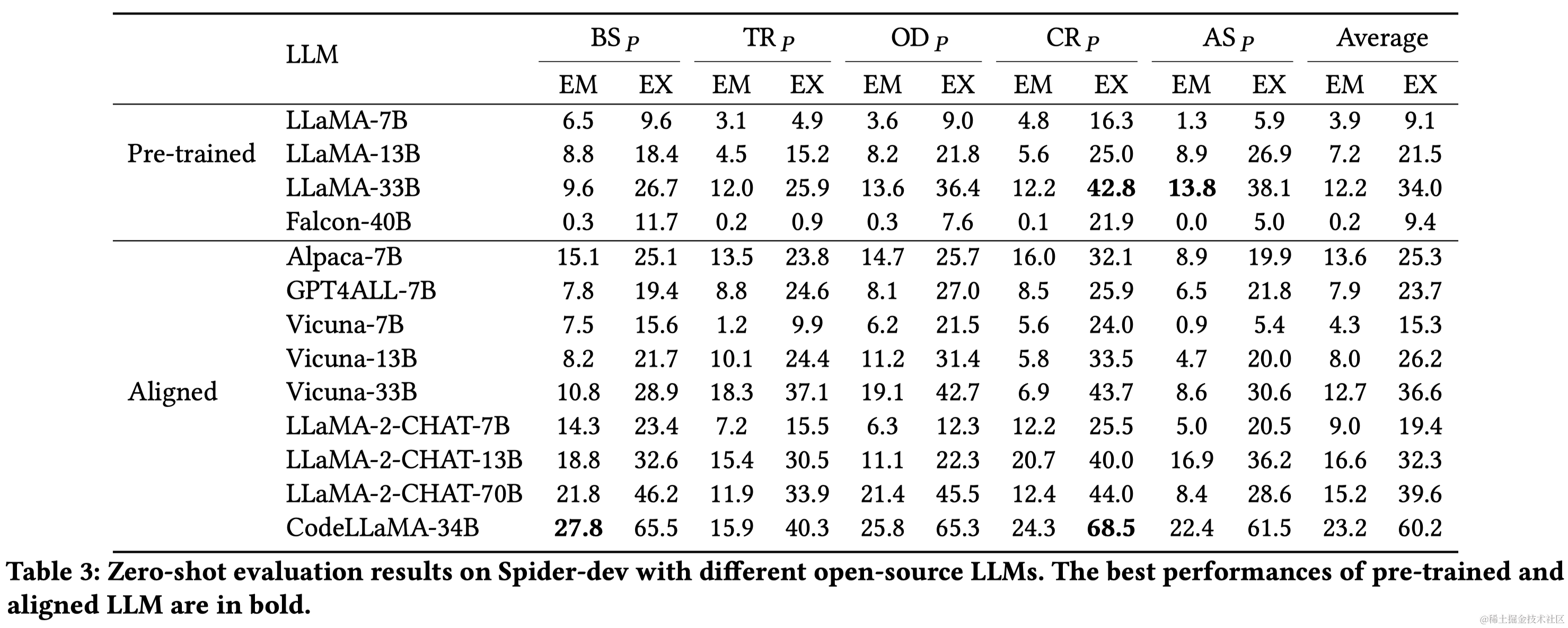
与OpenAI LLMs相比,开源LLMs的性能和上下文理解能力相对有限,需要通过监督式微调来提升。效率是LLM基础Text-to-SQL的另一个关键挑战,尤其是在使用多个示例的上下文学习提示时。
为了应对这些挑战,本研究旨在提供一个全面、系统和公平的LLM基础Text-to-SQL的基准评估。具体包括:
2 预备知识
Text-to-SQL的目标是将自然语言问题自动转换成SQL查询,促进了智能数据库服务、自动数据分析和数据库问答等应用的发展。由于理解自然语言问题和生成正确SQL查询的难度,Text-to-SQL仍然是一个充满挑战的任务。最初的研究集中于用预定义规则、查询枚举或将其视为序列到序列任务来解决Text-to-SQL任务。随着深度学习的迅速发展,例如注意力机制、图表示、语法解析等技术被应用于Text-to-SQL任务。BERT是Text-to-SQL领域广泛使用的技术之一,在当时取得了最佳性能。
随着大型语言模型(LLMs)的兴起,如GPT-4和LLaMA等LLMs成为自然语言处理和机器学习的新里程碑。LLMs是在大量文本语料上预训练的,能够执行各种自然语言任务。其操作原理是基于输入提示逐步产生概率最高的下一个词。在用LLMs处理Text-to-SQL任务时,关键是找到最佳的提示(Prompt)。根据在提示中提供的示例数量,提示工程分为零次示例(Zero-shot)和少次示例(Few-shot)场景。零次示例场景的挑战是有效地表示自然语言问题,包括数据库模式等相关信息。少次示例场景下,除了问题表示,还需要研究如何选择最有帮助的示例并适当地组织它们。LLMs通过上下文学习从输入提示中识别显式或隐含的模式,并生成相应的输出。尽管以前的研究证明LLMs在零次和少次示例场景下有效,但通过监督式微调,可以进一步提升它们的性能。