本文介绍: GPU在Transformer 大模型中的协同计算处理任务中功不可没,其在架构和功能设计中体现出的强大的并行计算、流式处理和多头注意力的优势,堪称黑魔法,为AI 大模型的深度学习任务提供了强大的堪称黑魔法般的加持。
)V
这就是自注意力机制(self-Attention)的原理。
在进行自注意力计算时,GPU处理器的并行计算能力就可以大显身手了。以一个批次大小为64的例子为例,GPU处理器能够同时计算64个样本中每个样本的自注意力,加速整个模型的训练过程。
这里,Q、K、V是输入序列的查询、键和值的表示,通过GPU上的矩阵乘法和softmax计算,同时处理多个样本的注意力权重。
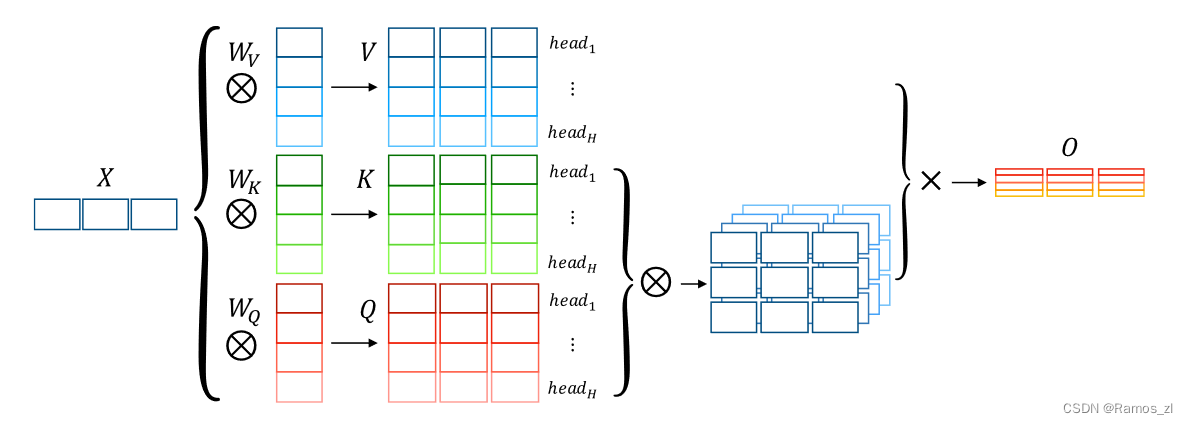
多头注意力的并行化
Transformer模型中还引入了多头注意力机制,通过并行计算多个注意力头,提高了模型的表示能力。GPU处理器的并行计算能力极大地加速了多头注意力的计算,每个注意力头都可以在不同的GPU核心上独立计算。
在上述示例中,每个注意力头的计算可以独立地在GPU上进行,最后再通过GPU处理器的并行计算能力将它们合并。
CUDA流的优化
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。