本文介绍: 哈喽大家好,我是咸鱼今天我们继续来讲一讲 Kafka当有消息被生产出来的时候,如果没有指定分区或者指定 key ,那么消费会按照【轮询】的方式均匀地分配到所有可用分区中,但不一定按照分区顺序来分配我们知道,在 Kafka 中消费者可以订阅一个或多个主题,并被分配一个或多个分区如果一个消费者消费了多个分区,某些场景下消费者需要顺序地消费消息,但消息并不是按照顺序分配给分区的,所以就不一定能够保证消息消费的全局顺序性比如下图中Msg0002消息并不是在Msg0001。
哈喽大家好,我是咸鱼
今天我们继续来讲一讲 Kafka
当有消息被生产出来的时候,如果没有指定分区或者指定 key ,那么消费会按照【轮询】的方式均匀地分配到所有可用分区中,但不一定按照分区顺序来分配
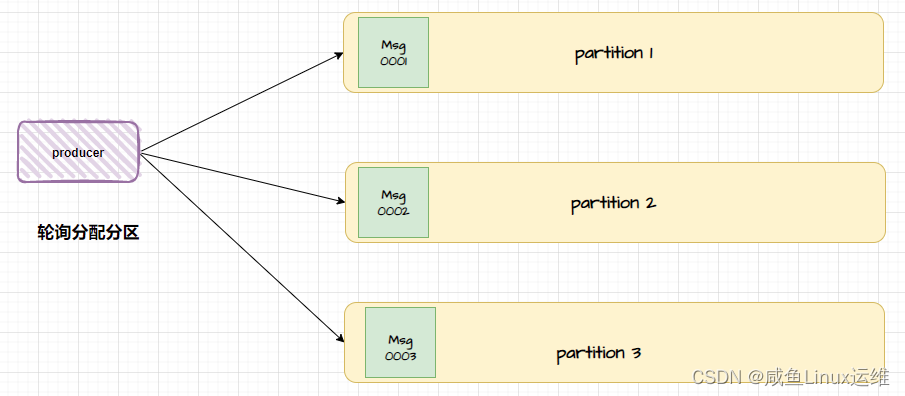
我们知道,在 Kafka 中消费者可以订阅一个或多个主题,并被分配一个或多个分区

如果一个消费者消费了多个分区,某些场景下消费者需要顺序地消费消息,但消息并不是按照顺序分配给分区的,所以就不一定能够保证消息消费的全局顺序性
比如下图中 Msg0002 消息并不是在 Msg0001 消息之后的,就有可能导致消费者先把 Msg0002 消息给消费, Msg0001 消息才被消费
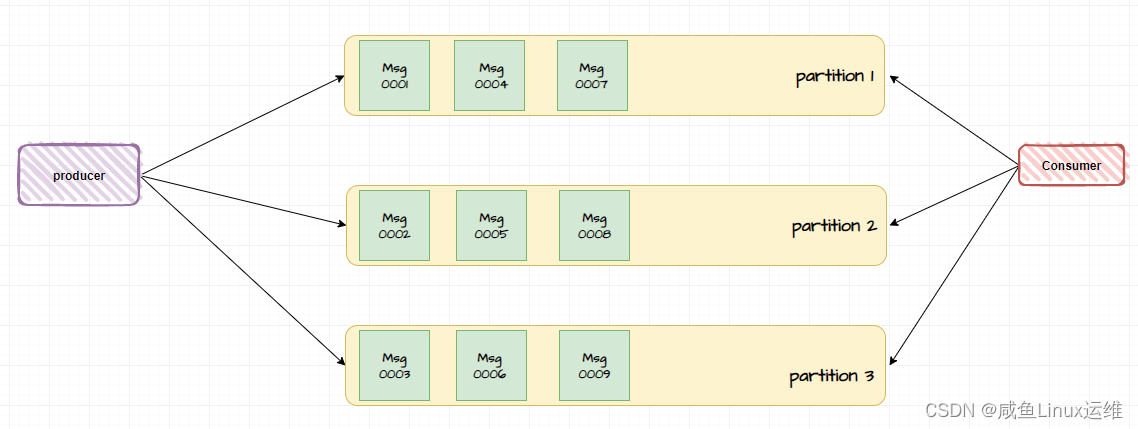
那么这种情况该怎么解决?**如何尽可能地保证消息消费的全局顺序性?(即这些消息具有因果关系)**要想消费消息 B 必须先消费消息 A
要注意的是,Kafka 的设计目标是提供高吞吐量和低延迟,而不是强制保证全局有序性
单分区

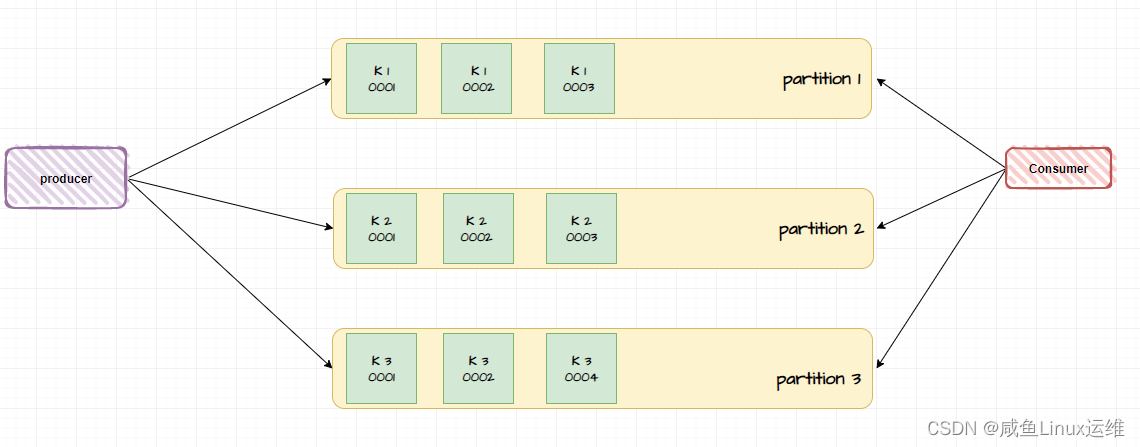
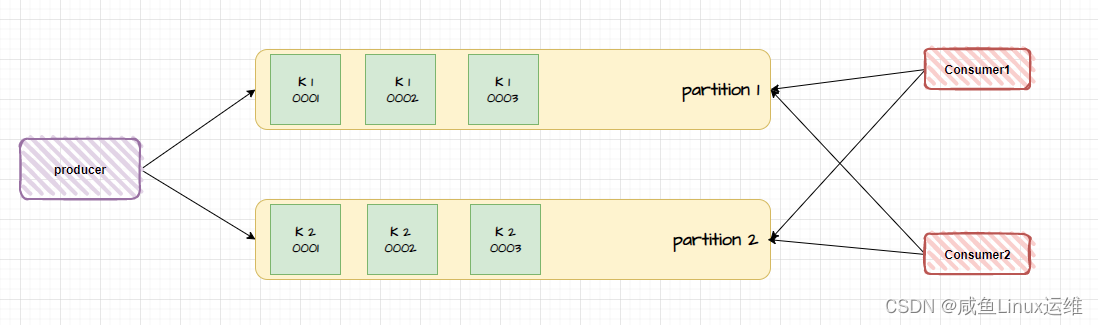
基于 key
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





