本文介绍: 一、机器学习概述所谓深度是指原始数据进行非线性特征转 换的次数.如果把一个表示学习系统看作一个有向图结构深度也可以看作从输 入节点到输出节点所经过的最长路径的长度. 这样我们就需要一种学习方法可以从数据中学习一个“深度模型”,这就是深度学习DL).深度学习是机器学习的一个子问题其主要目的是从数据中自动学习到有效的特征表示。一、机器学习概述通俗地讲机器学习ML就是让计算机从数据中进行自动学习得到某种知识或规律.作为一门学科机器学习通常指一类问题。
一、机器学习概述
一、基本概念
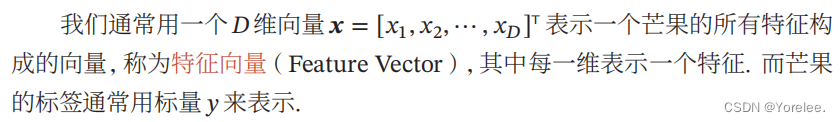

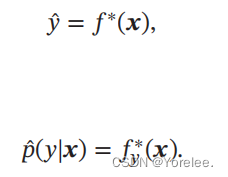

二、机器学习的基本流程

二、机器学习的三个基本要素
一、模型



二、学习准则


损失函数
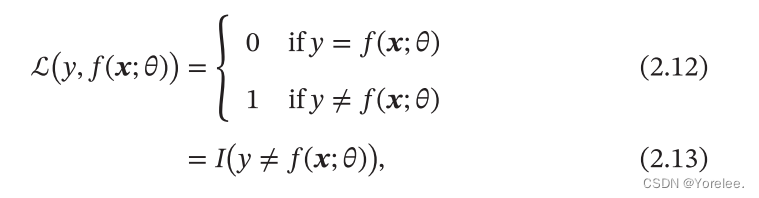



风险最小化准则
三、优化算法




三、机器学习算法的类型





声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






